博文参考《数据挖掘概念与技术》:韩家威著(机械工业出版社)
一 分类的概念
在面向对象编程(OOP)中我们说“一切皆对象”,在数据挖掘中,我们应该认为“一切皆数据”。而分类就是按照您的选择评估标准将数据进行分离,使得具有某些相同特性的数据属于一个类,不相同的数据不在一个类。
二 分类的一般过程
分类一般分为两个阶段:学习阶段(构建模型)和分类阶段(使用分类模型给测试数据的赋予类标号)。
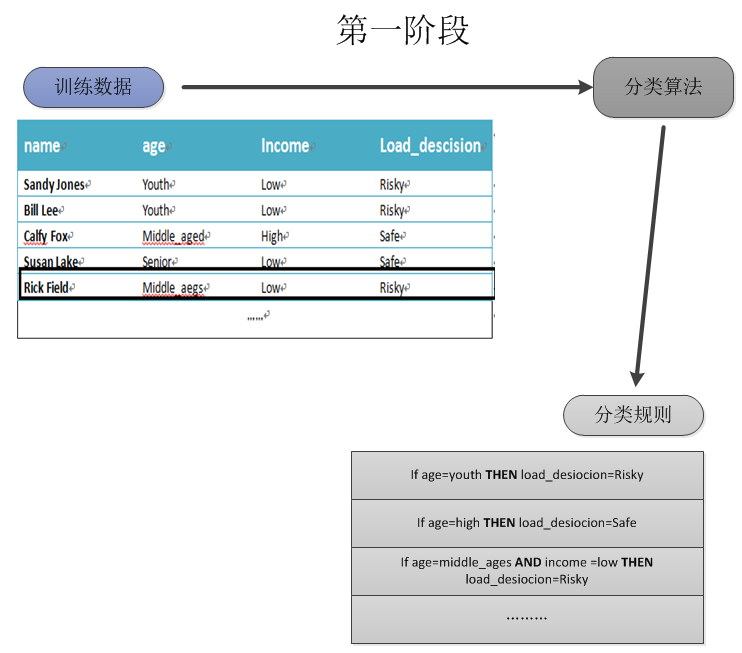
- 学习阶段:通过分析或从训练集“学习”来构造分类器。训练集由数据元组和相应的类标号组成。
- 元组:是用n维向量 $X=(x_1,x_2,x_3…)$ 表示的一条数据记录,其中n维向量表示的是元组X在n个属性上的度量。例如下图中黑边框标记的一条记录的元组表示为:X=(“Ricky Field”,”Middle_aged”,”Low”) 该数据有4个属性,分别是 “name”,”age”,”income”,”Loan_descision” ,其中属性”Loan_descision”也是分类属性,类标号为”Risky”。
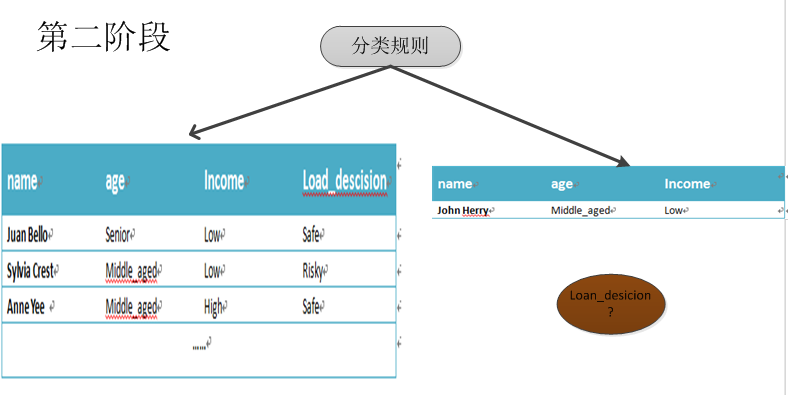
- 分类阶段,如下图所示,它属于一种映射过程。根据分类模型中的规则,给予测试数据元组X特定的类标号
三 分类的评估
3.1 度量的基础术语
- 正元组:感兴趣的主要元组,即我们要在第二章图中的数据中找到类标号”Loan_edscision”为”safe”的记录。
- 负元组:除去正元组以外的其他元组(或称为记录)。
3.2 度量的四个构件
- 真正例/真阳例(True Positive ,TP):指的是被分类器正确分类的我们”感兴趣”的元组。
- 真负例/真阴例(True Negative ,TN):指的是被分类器正确分类的我们”不感兴趣”的元组。
- 假正例/假阳例(False Positive,FP):指的是被分类器错误的分类的元组,即将我们”不感兴趣”的元组分成了”感兴趣”的元组。
- 假负例/假阳例(False Negative,FN):指的是被分类器错误的分类的元组,即将我们”感兴趣”的元组分成了”不感兴趣”的元组。
3.3 评估度量
有了度量的四个构件,我们可以得到常用的评估度量公式。如下
| 度量 | 公式 |
|---|---|
| 准确率(识别率) | $\frac{TP+TN}{P+N}$ |
| 错误率(误分类率) | $\frac{FP+FN}{P+N}$ |
| 敏感率(真正例率、召回率) | $\frac{TP}{P}$ |
| 特效性(真负例率) | $\frac{TN}{N}$ |
| 精度 | $\frac{TP}{TP+FP}$ |
| F分数(精度和召回率的调和均值) | $\frac{2精度召回率}{精度+召回率}$ |
如何理解:
- 准确率和错误率是相对的:前者计算的是全部记录中,分类器正确分类的元组数量,包括正确分类的”感兴趣”元组和”不感兴趣”元组;而后者计算的是全部记录中分类器错误分类的元组,也包括错误分类的”感兴趣”元组和”不感兴趣”元组。
- 敏感度和特效性是相对的:前者计算的是“感兴趣”元组中,被正确分类的元组数量,可以理解为“我们得到的”感兴趣”元组,有多少是真正的”感兴趣”元组”;特效性计算的是“不感兴趣”元组中被正确分类的元组数量,可以理解为“我们的得到的”不感兴趣”元组,有多少真正是”不感兴趣”元组”。
- 精度:是一个完全关乎”感兴趣”元组的统计项,一般情况下与敏感度等同。
四 对模型的评估
4.1 保持(holdout)方法和随机二次抽样
- 保持(holdout)方法 是我们在讨论准确率时默认使用的方法。此方法中,数据会被随机地划分为两个独立的集合:
训练数据集合和检验数据集合。通常,2/3的数据分配到训练集,其余1/3分配到检验集。 - 随机二次抽样方法 ,是保持方法的一种变形,只是将保持方法重复k次,总准确率取每次迭代准确率的平均值。
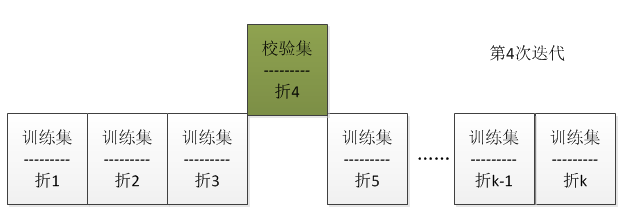
4.2 k折交叉验证
将数据分成互不相交的k等份 $D_1,D_2,D_3,…D_k$,训练和校验进行k次。第i次迭代时,将第i个等份(“折”)作为校验集,而其他等份(“折”)全体作为训练集合。注意,在保持方法中数据是随机分的,而此处是均分,并且每份数据集合都有一次机会作为校验集。下图显示的是第四次迭代时的一个示例: