一 spark安装和使用
1.1 安装spark
我们主要以Windows环境为例介绍Spark的安装。
整个安装过程主要分为四个步骤:安装JDK、安装Scala、安装Spark、安装WinUtil。在Linux和Mac OS X下
安装Spark只需要完成前三步即可。
1.1.1 安装JDK
Spark采用Scala语言编写,而Scala程序是以JVM为运行环境的,因此需先安装JDK以支持Spark的运行。
Spark通常需要JDK 6.0以上版本,你可以在Oracle的JDK官网 下载相应版本的JDK安装包,如
。需要注意的是,应选择下载“JDK”安装包,而不是“JRE”。在我们这个示例中,我们选择的是JDK 7.
1.1.2 安装scala
刚才我们提到,Spark是采用Scala语言编写的,因此第二步是要安装Scala。Scala官网的下载页面提供了多个版本的Scala下载,
但由于Scala各个版本之间兼容性并不好,因此在下载的时候一定要注意你要安装的Spark版本所依赖的Scala版本,以免遇到一些难以预知的问题。在我们的例子中,是要安装目前最新的Spark 1.3.0版本,因此
我们选择下载所需的Scala 2.10.4版本。选择之前的历史版本下载,需要先从如图2-2所示的下载页面中点击“All previous Scala Releases”链接,进入历史版本列表,然后选择“2.10.4”版本[下载](http://www.scala-lang.org/f iles/archive/scala-2.10.4.msi)
。下载后按照提示一步一步执行安装即可。
Scala安装后,要进行一个验证的过程以确认安装成功,其方法如下:
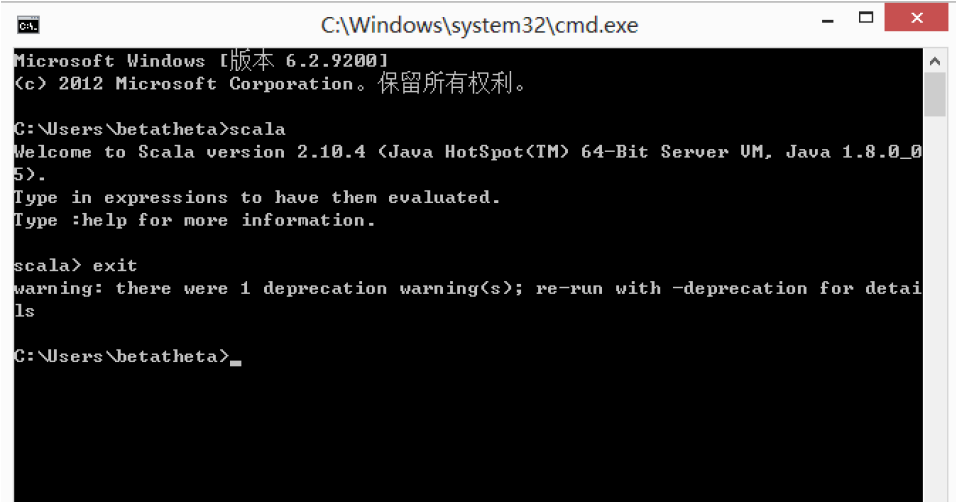
- 在Windows中执行命令cmd,启动Windows命令行环境。
- 在命令行环境中,输入scala,然后敲回车。
- 如果看到如图2-3所示成功启动Scala Shell环境,则说明安装成功,然后输入exit,退出Scala Shell环境。
- 如果启动Scala Shell环境失败,一般只需要在Windows环境变量设置界面配置SCALA_HOME环境变量为Scala的安装路径即可。
1.1.3 安装spark
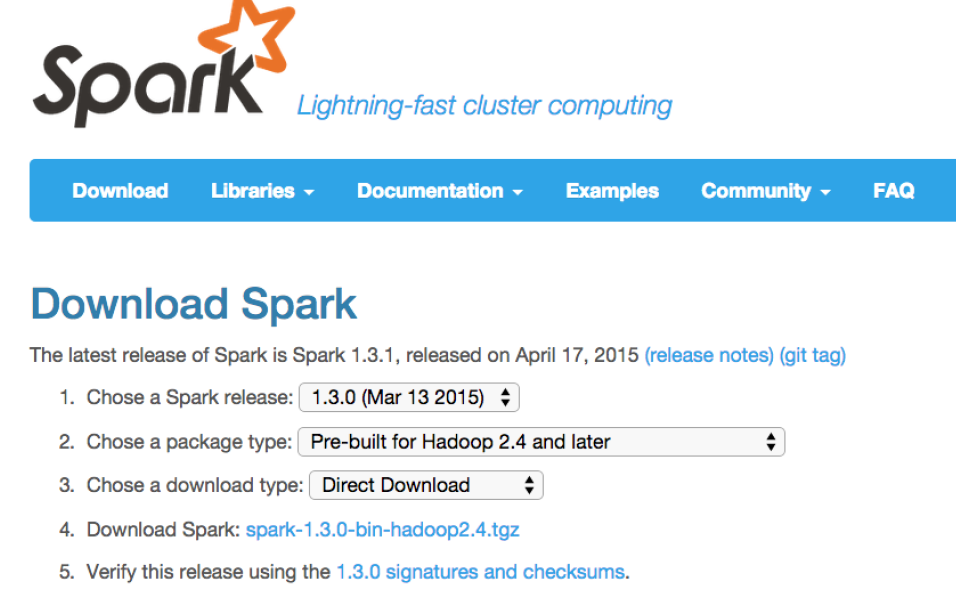
Spark官网提供了各个版本的安装包。为搭建学习试验环境,我们选择下载下载预编译好的包,例
如spark1.3.0binhadoop2.4.tgz
1.1.4 安装winutils
由于Spark的设计和开发目标是在Linux环境下运行,因此在Windows单机环境(没有Hadoop集群的支撑)时运行会遇到winutils的问题(一个相关的Issue可以参见
参考 。为了解决这一问题,我们需要安装winutils.exe,具体方法如下:
- 从一个可靠的网站下载winutils.exe(我们选择从Hadoop商业发行版Hortonworks提供的下载链接
- 将winutil.exe拷贝到一个目录,例如:E:\LearnSpark\win\bin。
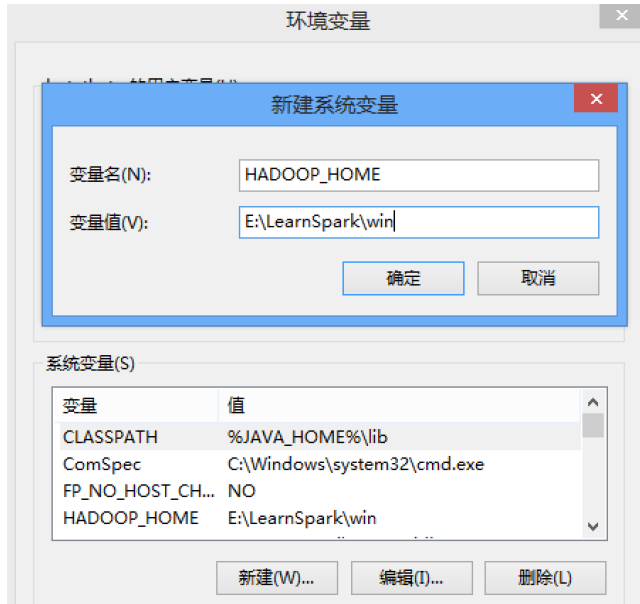
- 按照如图2-4、2-5的步骤,设置Windows系统的环境变量HADOOP_HOME为E:\LearnSpark\win(注意没有bin)
至此,Windows下安装Spark的过程全部完成。
1.2 使用spark shell
就像HelloWorld程序基本已成为学习某一门开发语言的第一个入门程序一样,WordCount程序就是试用大数据处理技术的HelloWorld。下面我们就以使用Spark统计一个文件中的单词出现次数为例,快速体验一下便捷的Spark使用方式。
启动Spark Shell环境
在Windows文件管理器中,切换目录到Spark安装后生成的spark1.3.0binhadoop2.4目录下,按住Shift键的同时点击鼠标右键,然后使用左键点击在此处打开命令窗口。在打开一个命令行的窗口中,输入bin\sparkshell,就可以启动spark-shell环境,如图2-6所示。
如果不希望这么麻烦地切换目录,而是希望在打开一个命令行窗口中直接运行spark-shell,那么只需要在Windows环境变量中将上面的spark-shell所在的路径加入环境变量PATH中即可。建立待统计的单词文件
选择一个已存在的文本文件,或新建一个文本文件,作为待统计的单词文件E:\LearnSpark\word.txt,在这里我们新建一个文件,内容为:
1 | banana banana``` |
part00000
(apple,1)
part00001
(banana,3)
## 1.3 了解Spark目录结构
Spark安装后,会在安装目录下生成一系列的目录,其结构如下:
+ bin目录下是使用Spark时常用的一些执行程序,例如我们进行Spark命令交互环境使用的spark-shell。
+ conf目录下存放的是运行Spark环境所需的配置文件。
+ data目录mllib需要的一些测试数据
+ ec2目录是在AWS上部署使用的一些相关文件
+ examples目录中有一些例子的源代码和测试文件
+ lib目录下存放的是Spark使用的一些库,我们之后开发spark应用,也是需要使用这些库的。
+ python目录是使用python相关的一些资源
+ sbin目录中是搭建spark集群所需要使用的一些脚本。