原文翻译整理自: 理解tensorflow中输入管道
主要内容 本文旨在根据mnist数据集构建一个简单而有效的输入管道。
使用tensorflow加载数据 有两种方式来加载数据,其一是使用feeding 方法并在每一步提供data 和label 给feed_dict 对象。这种方式在数据集太大而无法在内存中存放时将无能为力,因此tensorflow的作者提出了使用 input pipelines 。下一步将描述 pipelines ,但是,注意:只有在session操作之前启动队列runners才能激活pipelines并载入数据。input pipeline 将会处理读取csv文件,解析文件格式,重构数据,混洗数据,数据增强以及其他数据处理,然后在批处理中使用线程载入数据。
载入标签数据 假定我们有如下数据集:
1 2 3 dataset_path = "/path/to/out/dataset/mnist/" test_labels_file = "test-labels.csv" train_labels_file = "train-labels.csv"
首先要做的事情就是从生成的文本文件中载入图像和标签信息。注意,我们并不是要训练模型,所以不需要进行one-hot编码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def encode_label(label): return int(label) def read_label_file(file): f = open(file, "r") filepaths = [] labels = [] for line in f: filepath, label = line.split(",") filepaths.append(filepath) labels.append(encode_label(label)) return filepaths, labels # reading labels and file path train_filepaths, train_labels = read_label_file(dataset_path + train_labels_file) test_filepaths, test_labels = read_label_file(dataset_path + test_labels_file)
在字符串列表上选择性地做一些处理 接下来,我们将图像数据的相对路径转换为绝对路径,同时将训练数据和测试数据拼接在一起。然后混洗数据并创建我们自己的训练和测试集合。为使脚本输出结果易于理解,我们将只从数据集中抽样20个样本。
1 2 3 4 5 6 7 8 9 10 11 12 # transform relative path into full path train_filepaths = [ dataset_path + fp for fp in train_filepaths] test_filepaths = [ dataset_path + fp for fp in test_filepaths] # for this example we will create or own test partition all_filepaths = train_filepaths + test_filepaths all_labels = train_labels + test_labels # we limit the number of files to 20 to make the output more clear! all_filepaths = all_filepaths[:20] all_labels = all_labels[:20]
开始构建pipelines 确保我们所使用 tensor 的数据类型dtype 与列表中的已有的数据是一致的。载入以下包可以创建我们的tensorflow对象
1 2 3 4 5 from tensorflow.python.framework import ops from tensorflow.python.framework import dtypes # convert string into tensors all_images = ops.convert_to_tensor(all_filepaths, dtype=dtypes.string) all_labels = ops.convert_to_tensor(all_labels, dtype=dtypes.int32)
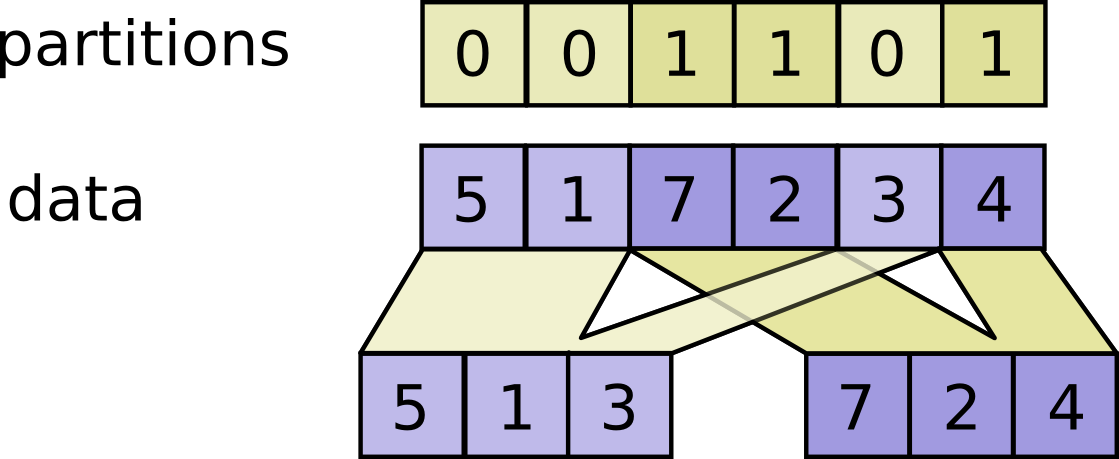
开始对数据分区 这一步是可选的。鉴于我们已经将我们的20个样本置于一个大集合之中,我们需要执行一些partition 操作来构建测试机和训练集。tensorflow可以在tensors上即时完成,所以不必预先做。如果对 partition操作感到困惑,可以参考tensorflow partition .我们将 test_set_size 设置为5个样本。下图显示了如何从数据集中随机选出训练集和测试集
注意partition 类似于位置因子或标签,数据某个位置上的不同标签将会将数据分成不同部分。
1 2 3 4 5 6 7 8 # create a partition vector partitions = [0] * len(all_filepaths) partitions[:test_set_size] = [1] * test_set_size random.shuffle(partitions) # partition our data into a test and train set according to our partition vector train_images, test_images = tf.dynamic_partition(all_images, partitions, 2) train_labels, test_labels = tf.dynamic_partition(all_labels, partitions, 2)
构建输入队列并定义如何载入图像 slice_input_producer 将tensors切分成许许多多的单个实例,并使用多线程将它们入队列。关于进一步的参数,比如线程数和队列容量等需要参考API文档。然后,我们使用路径信息将文件读入到 pipelines ,然后使用jpg decoder 解码(也可以使用其他解码器)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # create input queues train_input_queue = tf.train.slice_input_producer( [train_images, train_labels], shuffle=False) test_input_queue = tf.train.slice_input_producer( [test_images, test_labels], shuffle=False) # process path and string tensor into an image and a label file_content = tf.read_file(train_input_queue[0]) train_image = tf.image.decode_jpeg(file_content, channels=NUM_CHANNELS) train_label = train_input_queue[1] file_content = tf.read_file(test_input_queue[0]) test_image = tf.image.decode_jpeg(file_content, channels=NUM_CHANNELS) test_label = test_input_queue[1]
分组抽样并汇成一批批 如果在session 中执行train_image ,你将会得到一张图片信息(比如,(28,28,1)),这是我们的mnist图像的维度。在一张图片上训练模型是十分低效的,因此我们将图像汇入队列中称为一批,并在这一批批的数据上训练。目前为止,我们没有开始 runners 来载入图像,只是描述了 pipelines 初步形象,此时tensorflow 尚不了解图像的形状。使用tf.train_batch 之前,需要先定义图像张量的shape ,以便于将图像汇成一批批数据。此示例中,我们使用的是5个样本作为一批数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # define tensor shape train_image.set_shape([IMAGE_HEIGHT, IMAGE_WIDTH, NUM_CHANNELS]) test_image.set_shape([IMAGE_HEIGHT, IMAGE_WIDTH, NUM_CHANNELS]) # collect batches of images before processing train_image_batch, train_label_batch = tf.train.batch( [train_image, train_label], batch_size=BATCH_SIZE #,num_threads=1 ) test_image_batch, test_label_batch = tf.train.batch( [test_image, test_label], batch_size=BATCH_SIZE #,num_threads=1 )
运行 Queue Runners并启动session 上面的步骤已经完成 input pipelines 的构建。但是若此时去访问比如test_image_batch ,将不会有任何数据,因为我们并没有启动载入队列并将数据注入到 tensorflowd对象中的线程。完成这一步之后,接下来是两个循环,其一是处理训练数据,其二是吹测试数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 with tf.Session() as sess: # initialize the variables sess.run(tf.initialize_all_variables()) # initialize the queue threads to start to shovel data coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(coord=coord) print "from the train set:" for i in range(20): print sess.run(train_label_batch) print "from the test set:" for i in range(10): print sess.run(test_label_batch) # stop our queue threads and properly close the session coord.request_stop() coord.join(threads) sess.close()
但是从下面的输出结果看,你就会知道tensorflow不关心回合数(epochs)。我们不会混洗数据(查看input slicer的参数),同时 input pipelines只是在训练集上按照既定频率循环。你自己应该确保回合数(epochs)的准确性。尝试着调节 batch size 和 shuffle 并预测这将如何改变输出结果。你能预测到如果 batch_size 改成4而不是5将会改变什么吗?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 tf-env)worker1:~$ python mnist_feed.py I tensorflow/stream_executor/dso_loader.cc:105] successfully opened CUDA library libcublas.so locally I tensorflow/stream_executor/dso_loader.cc:105] successfully opened CUDA library libcudnn.so locally I tensorflow/stream_executor/dso_loader.cc:105] successfully opened CUDA library libcufft.so locally I tensorflow/stream_executor/dso_loader.cc:105] successfully opened CUDA library libcuda.so.1 locally I tensorflow/stream_executor/dso_loader.cc:105] successfully opened CUDA library libcurand.so locally input pipeline ready I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:900] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero I tensorflow/core/common_runtime/gpu/gpu_init.cc:102] Found device 0 with properties: name: GeForce GTX 960 major: 5 minor: 2 memoryClockRate (GHz) 1.253 pciBusID 0000:01:00.0 Total memory: 2.00GiB Free memory: 1.77GiB I tensorflow/core/common_runtime/gpu/gpu_init.cc:126] DMA: 0 I tensorflow/core/common_runtime/gpu/gpu_init.cc:136] 0: Y I tensorflow/core/common_runtime/gpu/gpu_device.cc:755] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GeForce GTX 960, pci bus id: 0000:01:00.0) from the train set: [5 4 1 9 2] [1 3 1 3 6] [1 7 2 6 9] [5 4 1 9 2] [1 3 1 3 6] [1 7 2 6 9] [5 4 1 9 2] [1 3 1 3 6] [1 7 2 6 9] [5 4 1 9 2] [1 3 1 3 6] [1 7 2 6 9] [5 4 1 9 2] [1 3 1 3 6] [1 7 2 6 9] [5 4 1 9 2] [1 3 1 3 6] [1 7 2 6 9] [5 4 1 9 2] [1 3 1 3 6] from the test set: [0 4 5 3 8] [0 4 5 3 8] [0 4 5 3 8] [0 4 5 3 8] [0 4 5 3 8] [0 4 5 3 8] [0 4 5 3 8] [0 4 5 3 8] [0 4 5 3 8] [0 4 5 3 8]
由于我们混洗了 partition 向量,很显然你会得到不同的标签。但是注意,此处重点是理解tensorflow的载入机制是如何工作的。因为每我们的 batch size 与测试集合的一样大。
完整代码 完整代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 # Example on how to use the tensorflow input pipelines. The explanation can be found here ischlag.github.io. import tensorflow as tf import random from tensorflow.python.framework import ops from tensorflow.python.framework import dtypes dataset_path = "/path/to/your/dataset/mnist/" test_labels_file = "test-labels.csv" train_labels_file = "train-labels.csv" test_set_size = 5 IMAGE_HEIGHT = 28 IMAGE_WIDTH = 28 NUM_CHANNELS = 3 BATCH_SIZE = 5 def encode_label(label): return int(label) def read_label_file(file): f = open(file, "r") filepaths = [] labels = [] for line in f: filepath, label = line.split(",") filepaths.append(filepath) labels.append(encode_label(label)) return filepaths, labels # reading labels and file path train_filepaths, train_labels = read_label_file(dataset_path + train_labels_file) test_filepaths, test_labels = read_label_file(dataset_path + test_labels_file) # transform relative path into full path train_filepaths = [ dataset_path + fp for fp in train_filepaths] test_filepaths = [ dataset_path + fp for fp in test_filepaths] # for this example we will create or own test partition all_filepaths = train_filepaths + test_filepaths all_labels = train_labels + test_labels all_filepaths = all_filepaths[:20] all_labels = all_labels[:20] # convert string into tensors all_images = ops.convert_to_tensor(all_filepaths, dtype=dtypes.string) all_labels = ops.convert_to_tensor(all_labels, dtype=dtypes.int32) # create a partition vector partitions = [0] * len(all_filepaths) partitions[:test_set_size] = [1] * test_set_size random.shuffle(partitions) # partition our data into a test and train set according to our partition vector train_images, test_images = tf.dynamic_partition(all_images, partitions, 2) train_labels, test_labels = tf.dynamic_partition(all_labels, partitions, 2) # create input queues train_input_queue = tf.train.slice_input_producer( [train_images, train_labels], shuffle=False) test_input_queue = tf.train.slice_input_producer( [test_images, test_labels], shuffle=False) # process path and string tensor into an image and a label file_content = tf.read_file(train_input_queue[0]) train_image = tf.image.decode_jpeg(file_content, channels=NUM_CHANNELS) train_label = train_input_queue[1] file_content = tf.read_file(test_input_queue[0]) test_image = tf.image.decode_jpeg(file_content, channels=NUM_CHANNELS) test_label = test_input_queue[1] # define tensor shape train_image.set_shape([IMAGE_HEIGHT, IMAGE_WIDTH, NUM_CHANNELS]) test_image.set_shape([IMAGE_HEIGHT, IMAGE_WIDTH, NUM_CHANNELS]) # collect batches of images before processing train_image_batch, train_label_batch = tf.train.batch( [train_image, train_label], batch_size=BATCH_SIZE #,num_threads=1 ) test_image_batch, test_label_batch = tf.train.batch( [test_image, test_label], batch_size=BATCH_SIZE #,num_threads=1 ) print "input pipeline ready" with tf.Session() as sess: # initialize the variables sess.run(tf.initialize_all_variables()) # initialize the queue threads to start to shovel data coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(coord=coord) print "from the train set:" for i in range(20): print sess.run(train_label_batch) print "from the test set:" for i in range(10): print sess.run(test_label_batch) # stop our queue threads and properly close the session coord.request_stop() coord.join(threads) sess.close()