一 如何理解
前馈网络之所以称为网络,是因为它们是由多种不同函数组成。网络模型可以看做一个有向无环图,该图描述了函数之间是如何关联的。
例如,我们有三个函数 $f^{(1)},f^{(2)},f^{(3)}$ 链式相连,形成 $f(x) =f^{(3)}(f^{(2)}(f^{(1)}))$ ,这种链式结构是神经网络中最常用的结构。其中 $f^{(1)}$ 被称为网络的第一层,$f^{(1)}$ 称为第二层…链式的长度即为网络的深度,网络的最后一层为输出层,这也是深度学习的来源。
网络训练过程中,我们让 $f(x)$ 逐渐匹配 $f^*(x)$ (为我们需要拟合的函数) 。训练样本提供了由 $f^*(x)$ 在不同点的带有噪音的近似的样本。每个样本 $x$ 都有一个相对应的标签 $y\sim f^*(x)$ ,训练样本直接指明了输出层在每个点 $x$ 的行为,它应该输出一个近似于 $y$ 的输出。
二 示例:学习XOR
我们通过一个学习XOR函数的任务来让前馈网络的概念更具体。XOR函数是一个在两个二值变量 $x_1,x_2$ 上的操作。当 $x_1,x_2$ 中的某一个值为1时,XOR函数返回1,否则返回0。XOR函数提供了一个目标函数 $y=f^*(x)$ 。我们的模型提供了函数 $y=f(x;\theta)$ ,我们的学习算法将会逐步调整参数 $\theta$ 来使得 $f$ 尽可能地趋近于 $f^*$。
此实例中,我们的目标是使得网络能够正确的预测变量 $x_1,x_2$ 在全部的域值空间的四个点 $X={[0,0]^T,[0,1],[1,0],[1,1]}$。可以将此问题看做回归问题,选择均方误差作为损失函数,在全部训练数据集中,MSE(均方误差)损失函数如下:
$$
J(\theta) = \frac{1}{4}\sum_{x\epsilon X}(f^*(x)-f(x;\theta))^2 \tag {6.1}
$$
2.1 模型
此时我们需要选择模型的形式 $f(x;\theta)$。假若我选择了一个线性模型,其中 $\theta$ 由 $w$ 和 $b$ 组成。我们的模型定义如下
$$
f(x;w,b) = x^Tw+b
$$
将四个训练样本带入可求解得 $w=0,b=1/2$ 此时的线性模型将一直输出0.5。 下图演示了线性模型无法表述 XOR函数。

图中四个点是学习函数需要在四个坐标输出的值(左下点坐标是(0,0),要输出0),从左边可以看出线性模型无法实现XOR功能。图右是被神经网络抽取特征的变换空间,此时线性模型可以解决XOR问题了。在样本解中,输出值为1的两个点在特征空间中合并为一个点了
下图演示了一个包含了一个隐藏层(有两个神经元)的网络(之前只有两层,输入和输出),隐藏层神经元的作用函数 $h$ 为 $f^{(1)}(x;w,c)$ ,隐藏单元的输出将作为第二层的输入。输出层依然是一个线性回归模型,但是它作用对象是 $h$ 而不是之前的直接的 $x$ 了。
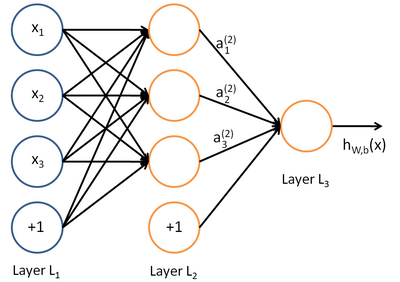
网络此时包含两个链式函数,$h=f^{(1)}(w;w,c)$ 和 $y=f^{(2)}(h;w,b)$ 。完整的模型可以表述为:
$$
f(x;W,c,w,b) =f^{(2)}(f^{(1)}(x))
$$
此时,函数 $f^{(1)}$ 该如何计算呢。如果使用线性模型,将会导致整个网络都沦为输入的线性函数( $f^{(2)}$(x) 是线性回归)。假若 $f^{(1)}(W^Tx)$ 而 $f^{(2)}(h)=h^Tw$ ,此时整个网络可以表述为 $f(x)=w^TW^Tx$ 依然是线性的。
很显然,我们必须使用一个非线性函数来描述这些特征。大多数神经网络是通过一个由学习参数控制的映射转换,加上一个固定的称为激活函数的非线性函数。大多数网络选用 ReLU作为激活函数
2.2 ReLU激活函数
ReLU作为激活函数的依据是,生物的稀疏激活性。人脑神经元同时被激活的只有1%-4%,这可提高学习精度,更好更快地提取稀疏特征。ReLU的非线性来源于神经元的部分选择性激活。
使用ReLU的另一个原因是,Sigmod(另外一种激活函数)网络会出现梯度消失情况。误差反向传播时,梯度
$$
Gradient = (y-y^{‘})sigmod^{‘}*x \
sigmod^{‘}(x) \quad\quad\epsilon (0,1) \
x \quad \epsilon (0,1)
$$
会成倍衰减( $sigmod^{‘}(x) \quad\epsilon (0,1)$ ,$x\epsilon (0,1)$)。而ReLU的梯度为 $max{0,W^Tx+b}$ 始终为1,只有一端饱和,梯度易流动,同时提高了训练速度。
关于ReLU的详细可参考 ReLU激活函数
三 基于梯度的学习
神经网络的非线性将导致损失函数非凸,没法全局收敛。应用于非凸的损失函数的SGD(随机梯度下降)方法也无法全局收敛,而且对初始值敏感。对于前馈网络而言,初始权重应随机初始化为很小的值,偏置 $b$ 初始化为0,或很小的值。 梯度下降方法应用在各种网络中,用来最小化损失函数。其实在训练SVM,线性回归模型中都可以使用梯度下降方法
3.1 损失函数
设计神经网咯时,一个重要的组成部分是损失函数的选择,尽管大部分神经网络的损失函数都与参数模型相似。
大多数情况下,参数模型的定义了一个概率分布 $p(y|x;\theta)$ ,我们使用的是最大似然定理(深度学习,机器学习的本质,将训练时最优的参数当做实际最优的参数),即,使用训练数据和模型预测值的交叉熵作为损失函数。
交叉熵定义:
$$
c = -\frac{1}{n}\sum_{x}[ylna+(1-y)ln(1-a)]
$$
交叉熵特性:
- 非负性
- 期望与实际误差小时,损失值小,反之则大。
有时候我们会使用一种简化解,不使用全部的 $y$的概率分布,仅预测满足一定条件的x对应的输出y的概率分布。
3.1.1.1 学习条件最大似然的条件分布
使用最大似然方法训练网络,其损失函数即负的对数似然,可定义为
$$
J(\theta) = -E_{x,y\sim p^{\sim}{data}}logp{model}(y|x)
$$
不同的参数模型,具体的损失函数不一样。
线性模型的输出的概率分布的最大似然估计等价于最小均方误差(损失函数的一种),实际上,这种等价是以忽略 $f(x;\theta)$ 对高斯分布的均值预测为前提的。
设计神经网络时的一个常见问题是:梯度需要足够大,且易于预测。饱和函数(上面一章中ReLU参考文章中有解释饱和函数)会破坏这一期望,它会将梯度变得特别小,这会导致网络很难调整。如果网络输出层是 $e^x$ 类的函数,若 $x$ 为较小负数,也会饱和。在这样的函数上应用对数函数可以有效化解饱和问题(对数和 $e^x$ 相互抵消)。
交叉熵损失函数可用来完成类似的最大似然估计的功能,因为它没有最小值,但可以无限逼近于0或1,这可同时用于离散化输出,logistic回归就是一个类似的模型。问题:若模型可控制输出分布的密度,就有可能给正确的训练集极高的密度,这会使得交叉熵趋于无穷大,使用正则化可用来避免这个问题。
3.1.1.2 学习条件概率
相比于 $p(y|x,\theta)$ 的完全概率分布,我们一般仅学习一个给定$x$ 的 $y$ 的条件概率分布。假若我们使用一个足够强大的网络,我们可以认为网络能够表述任意函数 $f$ (函数有足够多的分类),此时函数的分类仅受限于特征,比如特征的连续性和无界性,而不是某种固定的参数形式。从这个视角来看,我们可以将损失函数视为函数式而非简单的函数。函数式指的是从函数到实数的映射,而学习过程将会是选择一个函数,而不是一系列参数。此时,我们设计损失函数式为在某些期望函数上才取得最小值。比如,我们设计的损失函数式取得最小值的时候,对于给定的特征 $x$ 刚好输出了期望的 $y$ 。
3.2 输出神经元
损失函数的选择与输出神经元的选择直接相关。下文简述了一些不同输出分布时对应的神经元。
3.2.1 高斯分布输出的线性神经元
对于给定特征 $h$ ,线性输出神经元的输出为 $\bar y =W^Th+B$ 。线性输出层通常用来生产条件高斯分布的均值,此时求对数似然的最大值等价于最小化均方误差。(方差越小,分布越集中)。
最大似然框架易于学习高斯分布的方差,使得高斯分布的协方差成为输入的一个函数。但是所有的输入其输出必须为正的有限的矩阵。
3.2.2 Bernoulli输出分布的Sigmoid神经元
许多二分类问题都可以使用Sigmoid神经元输出。最大似然估计的方法是定义一个在条件 $x$ 上的 $y$ 的Bernoulli分布。
定义Bernoulli 分布只需要一个参数(概率),神经网络只需预测概率 $P(y=1|x)$ 即可。假若使用线性激活神经元,网络输出的预测概率
$$
P(y=1\mid x) =max \lbrace 0,min\lbrace 1,w^Th+b\rbrace \rbrace
$$
其中 $w^Th+b$ 很容易就不在区间 [0,1]上,为0.梯度为0,如何保证一直有较强的梯度呢?我们选用 Sigmoid 作为激活函数即可。Sigmoid激活神经元的输出为
$$
\bar y = \sigma (w^Th+b)
$$
而 $\sigma (x) =\frac{1}{1+e^{-x}}$ 。我们可以把 $sigma$ 输出单元看做两个组成部分:1.第一步是一个线性层,计算输出 $z= w^Th+b$ 即可。2. 使用Sigmoid将输出 $z$ 转换为概率。
我们考虑如何使用上面提到的 $z$ 来定义 $y$ 上的概率分布。我们可以通过构建一个非正态概率分布 $\tilde p(y)$(概率和不等于1)来理解 Sigmoid。下面是公式推导过程:
先假设对数概率在y,z上是线性
$$
log\tilde p(y)=yz \quad \
$$
取指数得非正态概率
$$
\tilde p(y) =exp(yz)
$$
对每个概率除以总概率即可归一化(概率和为1)
$$
p(y) =\frac{exp(yz)}{\sum^1_{y’=0}exp(y’z)}
$$
通过对 $z$ 的Sigmoid转换,获取一个Bernoulli分布
$$
p(y) =\sigma ((2y-1)z)
$$
此方法来预测对数空间的概率可以用最大似然方法。因为最大似然的代价函数是 $-log p(y\mid x)$ ,这个对数log 移除了Sigmoid中的指数式exp。如果没有这一步,sigmoid的饱和性会阻止梯度学习。
使用sigmoid参数化的Bernoulli分布的最大似然学习过程的损失函数如下:
$$
J(\theta) = -log P(y\mid x) \
=-log \sigma ((2y-1)z) \
=\varsigma ((2y-1)z)
$$
重写softplus损失函数中的部分项,我们可以看到当(1-2y)z,是负数且很大时,损失函数loss才会饱和。**只有当模型基本准确时,才会出现饱和现象,其中 $y=1$ 时,z将会是很大的正数(very positive), $y=0$ 时,z是很小的负数(very negative)**。如果使用其他损失函数,如均方差, $\sigma (z)$ 饱和时,损失函数就会饱和。
3.2.3 多重Bernoulli分布Softmax输出神经元
softmax是sigmoid函数的普遍形式,用于多分类。用在输出层,作为一个分类器,表述为多个分类上的概率分布。 softmax函数的常见形式如下:
对于二分类变量,我们一般只产生单一输出(两个分类,输出某个分类的概率)。公式:
$$
\hat y=P(y=1\mid x) \quad \epsilon (0,1)
$$
上式值区间为(0,1),如果想让此值的log对数能在基于梯度的算法中应用,我们选择预测一个值 $z=log \tilde P(y=1 \mid x)$ (概率的log对数)。指数化和归一化,外加一个Sigmoid函数,即可得到一个Bernoulli分布。
推广:假若我们将其推广到有n个离散值的场景中,输出向量 $\hat y$ ,其中 $\hat y$ 中每个分量 $\hat y_i=P(y=i \mid x)$ 取值区间为(0,1),向量各分量之和为1。一个线性层预测的非正态对数概率为: $z=W^Th+b$ ,其中 $z_i=log \tilde P(y=i \mid x)$
$$
P(i) =\frac{exp(\theta_i^Tx)}{\sum _{i=1}^Kexp(\theta_i^Tx)}
$$
通过softmax函数,可以使得 $P(i)$ 的范围在[0,1]之间。在回归和分类问题中,通常θ是待求参数,通过寻找使得 $P(i)$ 最大的 $\theta_i$作为最佳参数。回顾logistic函数形式.
对于logistic simoid,使用最大似然框架来训练softmax输出目标y时,exp函数效果很好。此时我们期望最大化 $log\quad P(y=i;z)=log\quad softmax(z)_i$ ,将softmax定义为指数形式是因为最大虽然估计中的log可以抵消。比如:
$$
log\quad softmax(z)_i=z_i-log\sum_iexp(z_j)
$$
最大化此等式即最大化 $z_i$,后面一项 $log\sum _iexp(z_j)$ 不显著。最大化此等式时,会使得 $z_i$ 增大,而其他所有 $z$ 变小。
通过近似,我们发现负的对数似然损失函数会惩罚大部分错误的激活函数。
3.2.4 softmax评价
除了对数似然目标函数外,许多目标函数与softmax搭配效果不好,尤其是那些没有使用Log来抵消指数部分的。
如果损失函数没有设计好,将导致网络很难学习,在某些区域网络的学习速度极慢。以神经网络的角度来看,softmax实际上是创建了一个竞争环境,总和为1,一方增加时会导致其他所有减少,极端情况下某一方为1,其他全为0.
3.2.5 其他输出神经元
最大似然框架指导如何根据输出层来设计一个好的损失函数。如果定义了一个条件分布 $P(y\mid x;\theta)$ 则建议使用 $logP(y\mid x;\theta)$ 作为损失函数。
通常,我们可以将神经网络看做函数 $f(x;\theta)$ 的表述,函数输出不会直接预测 $y$ 的值,而是提供 $y$ 分布上的参数,此时的损失函数为 $-logp(y;w(x))$。
3.3 隐藏神经元
隐藏神经元的设计并没有权威的指导原则。一般选择Relu作为隐藏神经元的激活函数。隐藏神经元的激活函数需要不断去尝试,无法预知使用哪种激活函数最好。
有些神经元的激活函数并不是严格可微的,比如Relu在 $z=0$ 时不可导(只是在部分点上)。而实际应用梯度方法依然表现很好,因为训练算法不会使损失函数达到局部最小,而只是大幅度减小。
神经元中的激活函数一般有左右导数,Relu中 $z=0$ 处左导数为0,右导数为1。但是程序实现时,一般只返回单侧导数,而且即便我们在求 $g(0)$ 的值,也只是逼近0的极小值,不是真的 $x=0$时的值。所以,实际上我们可以放心地无视激活函数中的不可微点。
3.3.1 Relu神经元和其泛化
可以参考两篇博客
Relu线性神经元的激活函数为 $g(z)=max\lbrace 0,z \rbrace$ 。
Relu与线性神经元很像,唯一的不同是,Relu的输出取值范围有一半为0(非激活)。这使得其导数一直很大,梯度不仅大而且连续。激活的神经元的二阶导数几乎处处为0,一阶导数处处为1。
Relu一般用在外层映射,比如 $h=g(W^Tx+b)$ 。初始化Relu时,建议取较小的b,这会使得Relu对大部分输入都是激活的。
缺点:激活函数输出为0时( $z_i<0$ ),Relu无法通过梯度学习,需要做一个泛化补充。
$z_i<0$ 时使用一种基于非0的斜率 $\alpha _i$ 来作变换,Relu变为:
$$
h_i=g(z,\alpha)_i=max(0,z_i)+\alpha_imin(0,z_i)
$$
有如下三种方法:
绝对值Relu:令 $\alpha_i=-1$,那么 $g(z)=\mid z\mid$ 。可以用在图像识别中寻找极性反转时特征不变的特征。
leaky Relu:令 $\alpha =0.001$ 取一个较小值。
参数化Relu:将 $\alpha$ 作为一个可以学习的参数。
3.4 其他隐藏神经元
许多未公开发表的激活函数其实与现在流行的激活函数一样有效。比如 $h=cos(Wx+b)$ 在 MNIST数据集上错误率只有1%,这完全可以媲美于使用多种卷积激活函数。通常情况下只有当新的隐藏神经元能够取得非常大提升时才会被公开发表。
神经网络中某些层可以使用纯线性激活函数,有助于减少网络参数。softmax一般用在输出层,但是也可以用于隐藏层。
其他可使用的隐藏层激活函数:
Radial basis function(RBF):$h_i =exp(-\frac{1}{\sigma i^2\mid \mid W{:,i}-x\mid \mid ^2})$ 。只有当x接近于模板 $W_{:,i}$ 时函数才会被激活,由于其对大多数的x都是饱和状态,所以很难优化。
softplus :$g(a)=\varsigma (a)=log(1+e^a)$ 是Relu的平滑版本,通常不鼓励使用softplus。
Hard tanh:形状与tanh和Relu很像,但是与Relu不同的是,它是有界的。 $g(a)=max(-1,min(1,a))$ 。
3.5 网络架构设计
网络架构设计关乎,需要多少个神经元,神经元之间是如何连接等问题。网络由一层层的神经元组成,每层由一组神经元构成。假设我们有第一层网络
$$
h^{(1)}=g^{(1)}(W^{(1)T}x+b^{(1)})
$$
其中 $x$ 为网络输入, $g^{(1)}$ 为第一层的激活函数。网络的第二层如下
$$
h^{(2)}=g^{(2)}(W^{(2)T}h^{(1)}+b^{(2)})
$$
其中 $h^{1}$ 为第一层的输出。
在这种链式结构中,网络架构需要考虑的是网络的深度和宽度,一般,更深的网络需要更少神经元,更少参数,但是难以优化。
3.5.1 通用近似属性和深度
通用近似定理表明,使用 至少一个隐藏层和线性输出层,以及激活函数的神经网络可以拟合任意Borel测度的函数。
多层前馈网络能表述任意函数,但是不能保证我们的训练算法可以学习此函数。有两个如下原因:
- 用来训练的优化函数,可能无法找到拟合目标函数的正确参数。
- 训练算法有可能因为过拟合选择错误的函数。
给定任意函数,必然存在可以拟合的神经网络,但是目前并没有一种通用的方法来校验特定训练样本和函数来泛化不在训练集中的数据点。
广义近似定律表明,存在一个大网络可以拟合任意准确率的预测函数,但是没有提及网络究竟会有多大。最新论文表明,最坏情况下,有隐藏层指数级数量的复杂度。比如一个向量 $V\epsilon \lbrace 0,1 \rbrace$ 上的可能的2分类函数有 $2^{2^n}$ 个,存储这些函数需要 $2^n$ 字节。
在选择机器学习算法时,其实我们是在表述算法所需要学习哪种先验知识。在选择深度学习模型时,其实是在将一个函数表述为几个简单的函数组合,此时学习问题变为挖掘变量间隐藏的关联参数问题,而这可进一步分解为更简单的变量之间的参数问题。
3.5.2 其他架构考虑
在设计网络时,需要明白不同的网络有不同用途,比如CNN用于图像处理,RNN用于做序列处理。网络也不必完全链式,从第 $i$ 层网络直接连接到第 $i+3$ 层这样的跳跃,使得梯度更容易从输出反馈到输入。
另外一个需要考虑的问题是,网络之间是如何连接的。默认是一个以矩阵 $w$ 的全连接,许多网络只是部分连接。比如CNN中用于图像处理,此时参数更少,计算速度快,这与具体问题相关。
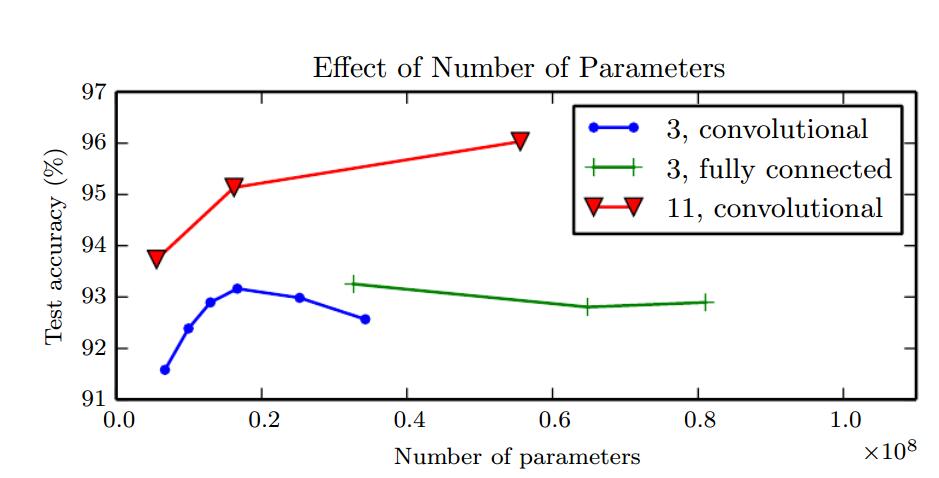
上图显示的是一个参数数量与测试准确率之间的关系。图中显示,增加CNN的参数而不增加深度并不能提升性能 。浅层网络在参数达到2000万时过拟合而深层网络在参数达到6000万时性能更强。表明,网络应该由更多更简单的函数组成。
4 反向传播算法
后向传播算法并不是指整个网络,它只是计算梯度的一个方法,有其他方法,如随机梯度下降,它还可以用于对任意函数求导。
以下解释来自知乎 反向传播算法
假若我们有如下简单网络:
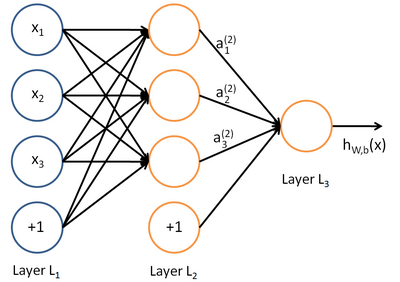
对应的函数表达式如下:
$$
a_1^{(2)}=f(W_{11}^{(1)}x_1+W_{12}^{(1)}x_2+W_{13}^{(1)}x_3+b_1^{(1)}) \
a_2^{(2)}=f(W_{21}^{(1)}x_1+W_{22}^{(1)}x_2+W_{23}^{(1)}x_3+b_2^{(1)}) \
a_3^{(2)}=f(W_{31}^{(1)}x_1+W_{32}^{(1)}x_2+W_{33}^{(1)}x_3+b_3^{(1)}) \
h_{W,b}(x)=a_1^{(3)}=f(W^{(2)}{11}a_1^{(2)}+W{12}^{(2)}a_2^{(2)}+W_{13}^{(2)}a^{(2)}_3+b_1^{(2)})
$$
上面式中的 $W_{ij}$ 就是相邻两层神经元之间的权值,它们就是深度学习需要学习的参数,也就相当于直线拟合 $y=k*x+b$ 中的待求参数k和b。
和直线拟合一样,深度学习的训练也有一个目标函数,这个目标函数定义了什么样的参数才算一组“好参数”,不过在机器学习中,一般是采用 **成本函数(cost function)**,然后,训练目标就是通过调整每一个权值 $W_{ij}$ 来使得cost达到最小。cost函数也可以看成是由所有待求权值 $W_{ij}$ 为自变量的复合函数,而且基本上是非凸的,即含有许多局部最小值。但实际中发现,采用我们常用的梯度下降法就可以有效的求解最小化cost函数的问题。
梯度下降法需要给定一个初始点,并求出该点的梯度向量,然后以负梯度方向为搜索方向,以一定的步长进行搜索,从而确定下一个迭代点,再计算该新的梯度方向,如此重复直到cost收敛。那么如何计算梯度呢?
我们把cost函数定义为 $H(W_{11},W_{12},W_{13},..W_{ij},..,W_{mn})$ ,那么它的梯度向量就等于
$$
\triangledown H=\frac{\partial H}{\partial W_{11}}e_{11}+…\frac{\partial H}{\partial W_{mn}}e_{mn}
$$
此,我们需求出cost函数H对每一个权值 $W_{ij}$ 的偏导数。而BP算法正是用来求解这种多层复合函数的所有变量的偏导数的利器。我们以求 $e=(a+b)*(b+1)$ 的偏导为例。它的复合关系画出图可以表示如下:
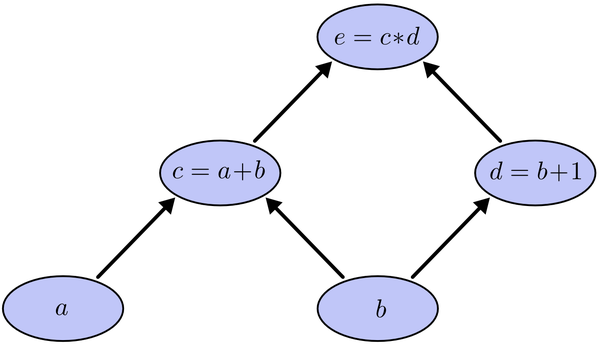
在图中,引入了中间变量c,d。
为了求出a=2, b=1时,e的梯度,我们可以先利用偏导数的定义求出不同层之间相邻节点的偏导关系,如下图所示。
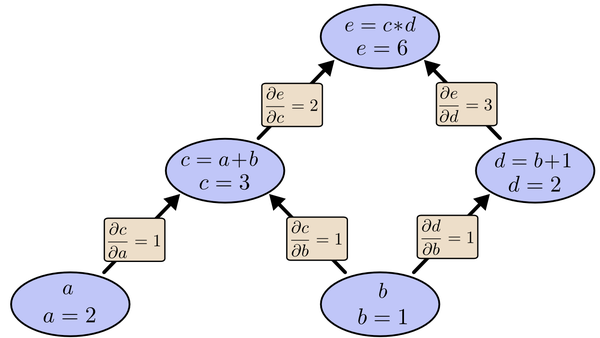
利用链式法则我们知道:
$$
\frac{\partial e}{\partial a}=\frac{\partial e}{\partial c}\frac{\partial c}{\partial a} \
\frac{\partial e}{\partial b}=\frac{\partial e}{\partial c}\frac{\partial c}{\partial b}+\frac{\partial e}{\partial d}\frac{\partial d}{\partial b}
$$
链式法则在上图中的意义是什么呢?其实不难发现, $\frac{\partial e}{\partial a}$ 的值等于从 $a$ 到 $e$ 的路径上的偏导值的乘积,而 $\frac{\partial e}{\partial b}$ 的值等于从 $b$ 到 $e$ 的路径 $1(b-c-e)$ 上的偏导值的乘积加上路径 $2(b-d-e)$ 上的偏导值的乘积。也就是说,对于上层节点p和下层节点q,要求得 $\frac{\partial p}{\partial q}$ ,需要找到从 $q$ 节点到 $p$ 节点的所有路径,并且对每条路径,求得该路径上的所有偏导数之乘积,然后将所有路径的 “乘积” 累加起来才能得到 $\frac{\partial p}{\partial q}$ 的值。
大家也许已经注意到,这样做是十分冗余的, 因为很多路径被重复访问了。比如上图中,a-c-e和b-c-e就都走了路径c-e。对于权值动则数万的深度模型中的神经网络,这样的冗余所导致的计算量是相当大的。
同样是 利用链式法则,BP算法则机智地避开了这种冗余,它对于每一个路径只访问一次就能求顶点对所有下层节点的偏导值。正如反向传播(BP)算法的名字说的那样,BP算法是反向(自上往下)来寻找路径的。
从最上层的节点e开始,初始值为1,以层为单位进行处理。对于e的下一层的所有子节点,将1乘以e到某个节点路径上的偏导值,并将结果“堆放”在该子节点中。等e所在的层按照这样传播完毕后,第二层的每一个节点都“堆放”些值,然后我们针对每个节点,把它里面所有 “堆放” 的值求和,就得到了顶点e对该节点的偏导。然后将这些第二层的节点各自作为起始顶点,初始值设为顶点e对它们的偏导值,以”层”为单位重复上述传播过程,即可求出顶点e对每一层节点的偏导数。
以上图为例,节点c接受e发送的12并堆放起来,节点d接受e发送的13并堆放起来,至此第二层完毕,求出各节点总堆放量并继续向下一层发送。节点c向a发送21并对堆放起来,节点c向b发送21并堆放起来,节点d向b发送31并堆放起来,至此第三层完毕,节点a堆放起来的量为2,节点b堆放起来的量为21+3*1=5, 即顶点e对b的偏导数为5.