一 GAN网络
与一般的被用于Supervised Learning任务的深度神经网络不同,GAN同时要训练一个生成网络(Generator)和一个判别网络(Discriminator),前者输入一个noise变量 z ,输出一个伪图片数据 $G(z;θ_g)$ ,后者输入一个图片(real image)/伪图片(fake image)数据 x ,输出一个表示该输入是自然图片或者伪造图片的二分类置信度 $D(x;θ_d)$ ,理想情况下,判别器 D 需要尽可能准确的判断输入数据到底是一个真实的图片还是某种伪造的图片,而生成器G又需要尽最大可能去欺骗D,让D把自己产生的伪造图片全部判断成真实的图片。
根据上述训练过程的描述,我们可以定义一个损失函数:
$$
Loss = \frac{1}{m}\sum[logD(x^i)+log(1-D(G(z^i)))]
$$
二 DCGAN网络
2.0 介绍
本论文做了以下贡献。
提出并评估了一系列的加在卷积GAN网络拓扑结构的约束,使得卷积GAN网络在大部分设置中稳定的用于训练。给这种架构取名为深度卷积GAN(DCGAN)
对图像分类任务使用训练好的分类器,结合其他无监督学习算法,性能较好。
可视化了GAN学习到的过滤器(filter),并且实验表明特定的过滤器已经学习到画特定的物体。
表明,生成器有些有趣的矢量算数性质,它可以很容易地完成生成模型的语义质量的操作。
2.1 无标签数据中的表征学习
经典的无标签表征学习是在数据上做聚类(K均值聚类)。图像领域,可以在图像patches上做层次聚类,以此来学习表征
另外一个方法是训练自动编码器(卷积,堆叠),它可以分离编码的组件是什么以及组件位置。梯形结构将图像编码成压缩编码,然后解码编码来重构图像。
2.2 生成自然图像
生成自然图像模型主要有两种:参数化和非参数化。
非参数化模型一般是从已存在的数据库中做匹配,通常是匹配图像块(patches)。这种方法已经用在了
纹理合成,超分辨率,绘画。参数模型目前已经被研究得较充分(例如MNIST数据集或者纹理合成)。但是生成真实世界的自然图像还没有取得成功。一种
变分抽样方法生成图像,生成的图像中容易有模糊干扰。另外一种方法是,使用迭代前向扩散方法生成图像。GAN生成网络生成的图像有噪音,并且可能产生无法理解的图像。一种拉普拉斯金字塔拓展方法的方法生成质量更高的图像,但是依然摆脱不了噪音。一种RNN和反卷积网络可以生成一些较好的自然图片。
2.3 CNN内部的可视化
使用反卷过滤最大激励,可以知道CNN中每个卷积过滤器(卷积核)的效果。
2.4 方法和模型架构
经验表明:使用CNN来增大GAN的方法来给图像建模的方法是失败的。我们定义了一组架构,它可以在多个不同数据集上稳定训练,并且可以训练更高的分辨率和更深的生成模型。
方法的核心在于,采用并修改了CNN架构中三个方面。
- 所有的用stride卷积替换确定性空间池化函数(例如最大池化)卷积网络,这允许网络学习它自己的空间下采样。我们在生成器中使用了这种方法,这使得它能够学习自己的空间下采样和分类器。
2.去掉顶层卷积特征上的全连接层。最好的例子是全局均值池化用在艺术图像分类模型。我们发现,全局均值池化增加了模型的稳定性,但是拖累了其收敛速度。一个中间层的生成器和分类器,分别直接将顶层的卷积特征链接到输入和输出,其结果较好。GAN的第一层,以正态噪音分布Z作为输入,可以称为全连接,因为它只是矩阵操作,但是结果被reshaped成一个4维tensor,并用作卷积堆叠的起始。对于分类器,最后的卷积层被平铺(flatten)并喂入单个sigmoid输出。
- 第三个是Batch Normalization,通过对每个输入神经元进行归一化(均值为0,方差是单位方差(1))来稳定学习。它可以避免由于poor initialization和深层模型中的梯度扩散问题。直接将batchnorm应用到所有层,将会导致抽样震荡和模型不稳定。因此,不要将batchnorm用在输出层的生成器和输入层的分类器。
Relu激活函数用在生成器中,输出层使用Tanh激活函数的除外。我们发现使用收敛的激活函数可以让模型更快的饱和并覆盖训练分布的颜色空间。在分类器中,我们发现,使用leaky Retified 激活函数表现较好,尤其是高分辨率模型。这与原始的GAN模型相反,它用的是maxout激励函数。
总结
使用strided 卷积(分类器)和fractional-strided卷积(生成器)替换所有池化层。
分类器和生成器中都是用batchnorm
深层架构,移除全连接层
除了输出层使用Tanh激活函数,其他层都使用Relu
所有层的分类器都使用 LeakyRelu
2.5 模型细节
数据集:, Large-scale Scene Understanding (LSUN) (Yu et al., 2015),Imagenet-1k and a newly assembled Faces dataset
预处理:图像不做预处理,激活函数tanh范围拓展到[-1,1]
所有模型预训练都是使用mini-batch SGD,mini-batch 是128。
所有权重初始化是,均值为0,方差为0.02
LeakyRelu:the slope of the leak was set to 0.2 in all models
之前的GAN使用动量来加速训练,此文使用带超参数的Adam 优化器
学习率为 0.0002
动量项 $\beta _1 =0.5$ 更稳定(原始的是0.9)
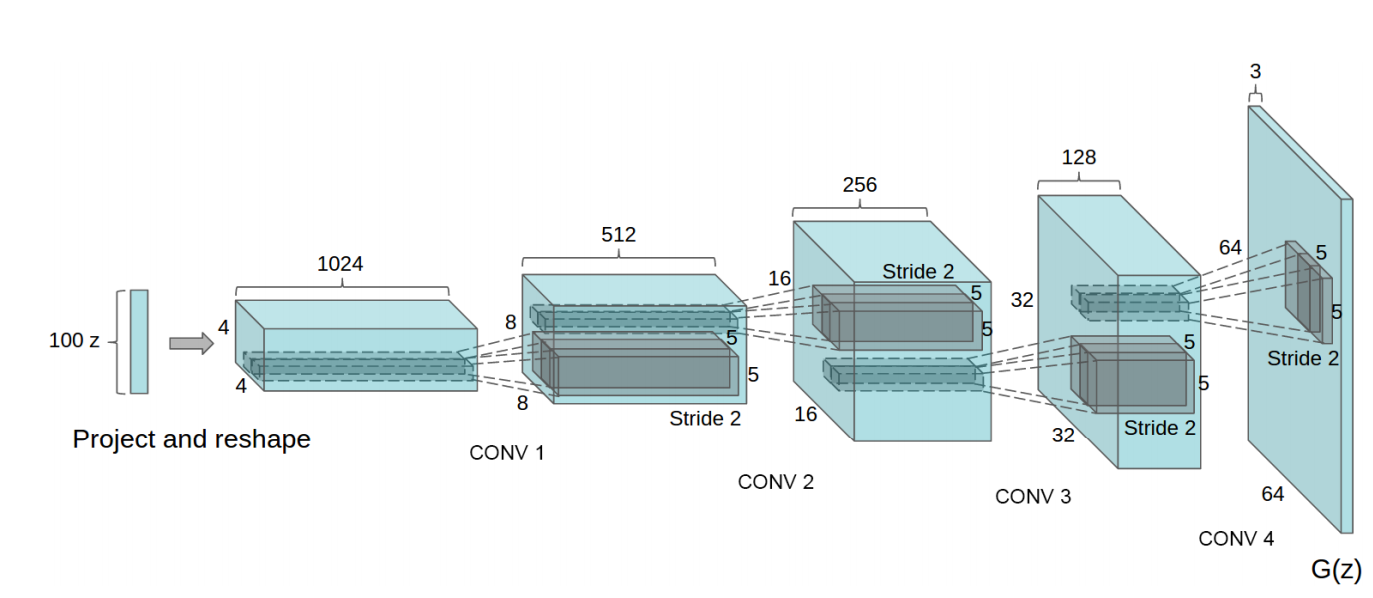
一个100维的正态分布Z被投影到一个小的空间范围,许多特征maps的卷积表征。一系列的四fractionally-strided卷积(有些论文误称为反卷积),然后将这个高度表征表示为64x64像素的图像。注意:没有使用全连接层或池化层。