摘要
算法使用图像的局部特征,如shape index和弯曲度,用以检测肺体积内的候选结构,然后再使用两个后续的KNN分类器来剔除假阳性样本。
肺结节检测系统在三个数据集上训练和测试,这三个数据集来源于一个大规模筛选实验。数据集的构建,为了评估算法既考虑挑选的随机性,又考虑到较高概率出现结节的需求。此系统在随机挑选的813scans中灵敏度为80%,平均一个scans4.2个假阳性。
二 处理方法
下图展示了结节检测的大体流程
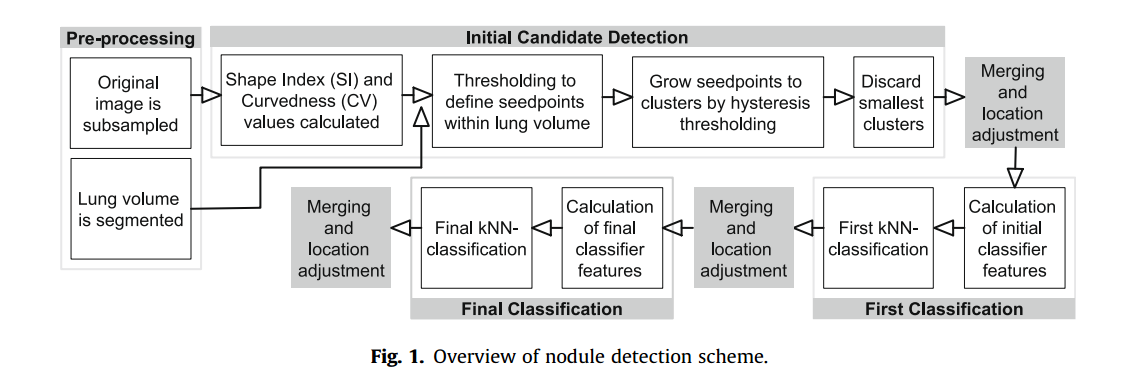
需要注意的是,结节检测步骤需要很多经验阈值,这些经验阈值基于一个完全独立的小测试集。
2 预训练
2.1 图像数据子抽样
第一步是下采样以提高算法速度。使用整副图像对最终结果帮助极小,反而非常消耗计算。下采样利用了block-average,比如图像的矩阵尺寸是512x512,减小到256x256,slices的数目减少以形成各向同性采样数据。线性插值用来体素位置(一个scans其实是个立方体数据)的灰度值。下采样scans的slices数目从149到428不等,平均每个scans有223个slices。
2.2 肺容积切割
第二个步骤是将肺部从周围组织中分割出,此步骤是紧接上一步骤,从子抽样中进行的。此切割获得的mask可用来确保结节检测仅限于肺容积内部。这个过程有两个好处,其一是减小计算时间,其二是避免在肺容积外去检测。
3 初始候选检测
初始候选检测的流程图如下
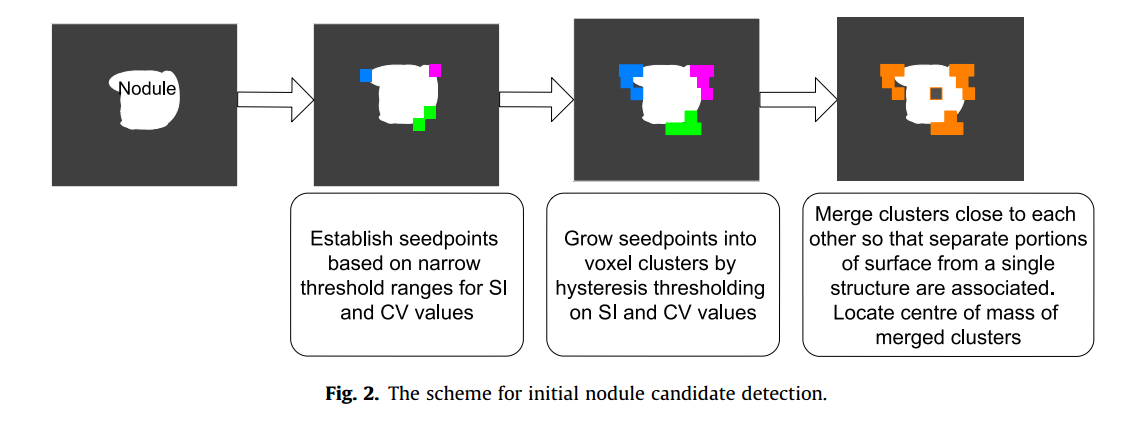
3.1 shape index and curvedness
结节检测使用了shape index(SI)和curvedness特征来检测初始结节候选(Koenderink, 1990) 。这些是逐个体素计算的3D局部图像特征,基于局部衰减值和图像容积内每个点的表面拓扑性。SI和CV从主曲率 $k_1$ 和 $k_2$ 中得出,但是有去耦拓扑形状和曲率大小的优势。结节检测中我们感兴趣的是那些明显球形的体素和球体半径在合适范围的。每个体素上的shape index和curvedness,使用主曲率 $k_1$ 和 $k_2$ 的计算方式如下
$$
SI =\frac{2}{\pi} arctan(\frac{k_1+k_2}{k_1-k_2}) \
CV = \sqrt{k_1^2+k_2^2}
$$
$$
K = \frac{F_{xx}\cdot F_{yy}-{F_{xy}}^2}{(1+{F_x}^2+{F_y}^2)^2}
$$
肺容积内部所有的体素都要计算主曲率 $k_1$ 和 $k_2$ 都要计算,使用图像高斯过滤器 $\sigma =1$模糊的一阶和二阶导数。这个 $\sigma$ 的值是经验设置的以减少噪声同时不移除重要的结构细节。
3.2 seed point检测
一旦知道了图像的SI和CV值,就可以获得其seed point点集合,这可以根据下表经验阈值来得到。在SI和CV阈值范围内的体素将会被选为seeds。这些seed points代表体素可能位于结节表面,并且其局部性值得进一步分析。胸膜表面的5个体素位置的SI阈值将会小一些,是为了增加肺部边缘的seed检测数目。这么做是因为胸膜结节的表面区域不明显,难以检查,并且其区域内的SI和CV值可能会受到邻接胸膜表面的拓扑结构影响。
初始seed阈值
| Value | Upper threshold | Lower threshold |
|---|---|---|
| SI | 1 | 0.8(near pleural surface) |
| 0.9(elsewhere) | ||
| CV | 1 | 0.3 |
3.3 cluster 信息
如今seed point扩大到形成VOI (voxels of interest)cluster。此扩张基于滞后阈值,使用下表中的边缘阈值。因此最终cluster包含的voxels(体素),其SI和CV值都落在阈值范围区间内,并且是可使用链式的此类体素连接(使用six-connectively)到一个seedpoint。
Hysteresis阈值
| Value | Upper threshold | Lower threshold |
|---|---|---|
| SI | 1 | 0.7(near pleural surface) |
| CV | 1.3 | 0.2 |
应当注意到一个完美的球形结构,最终cluster中的体素位于球形模糊表面。大量的cluster中心被当做这一阶段的兴趣点。
若某个cluster的原始seedpoint位于胸膜表面的5个体素之内,可以作为一个胸候选(?不是肺)。此阶段的cluster,若其容积(volumn)低于一个预先设置的阈值 $t_{vol}$ 则会被丢弃,因为如果不丢弃,后续的处理将会及其耗时,同时可能会引入假阳性样本。胸膜区域的候选 $t_{vol}$ 设置为4体素,剩下的候选中设置为15体素。
3.4 cluster merge
此阶段,已经检测到大量的cluster。每一个代表图像中的一个区域表面,并且有理由假设一个真实的结构,比如结节可能有不止一个cluster 代表它。除非是那种特别大的结节,或者其形状怪异,这些结节彼此十分靠近。位置在三个体素内的cluster会被递归地合并,直至无法再合并为止。这个合并过程在那些相距7个体素的cluster之间会不断重复。下图展示了候选结构的合并过程。可以看到这个合并过程在几个后续point上重复。尽管后续阶段,只有少部分结构需要合并,这个过程主要有两个目的:**(1)可以确保单个结节只会被单个检测,而不是被相邻的两个检测。(2)**合并候选是假阳性的话,会产生奇怪的形状结构,这可以很容易被后续的分类步骤剔除。

3.5 候选位置调整
此处候选位置会被检查并调整以确保它们处于局部最明亮的位置。这十分重要,因为结节的位置由大量的voxels(体素) cluster中心定义的,并且也不经常是结节中心。尤其是胸膜结节或者体素cluster在结节表面的中心位置的。位置调整过程使用原始候选位置的三个体素的最大距离检查所有的局部点。每个局部点,计算它与周围6个相连邻居(six-connectively)点的平均灰度值。有最高平均灰度值的位置将会被选为新的候选位置。局部平均有利于避免选择了高亮的噪音体素。
4 假阳性剔除
假阳性剔除由两个连续使用KNN分类器分类步骤组成。数据的属性表明其并没有很好的线性分类性能,使用SVM分类器得到的结果比KNN要差。所有情况中,$k$ 设置为训练集样本数目的(奇数)平方根。对 $k$ 值的实验并不能再开发阶段获得性能提升(K值应该就确定为样本平方根)。分类之前,尽可能生成较好的训练集。生成过程如下图
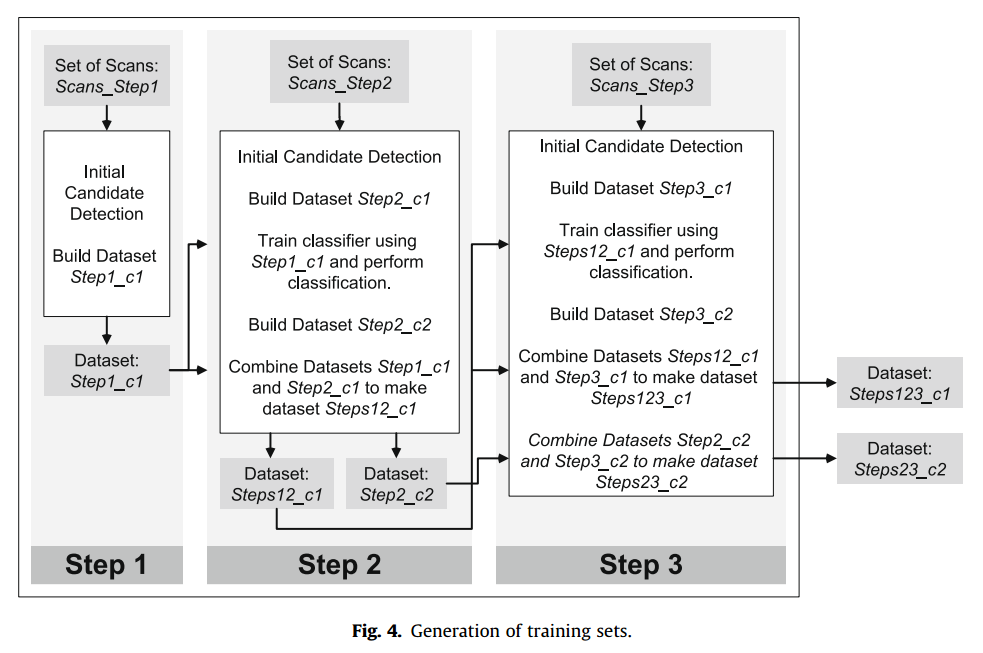
对于初始分类器,使用小量的足够计算的特征是为了进一步减小候选数目,而不至于过头。初始分类之后剩下的候选已经足够小,可以使得最终分类器计算大量复杂特征。两个分类步骤的特征选择是Sequential Forward Floating Selection’ (SFFS)(Pudil et al.1994)。SFFS过程仅在训练集上使用留一法(从训练集里留出训练集和测试集),ROC曲线下的区域作为优化标准。第一个分类器选择的最大特征数定为15,第二个分类器为50。训练集上的留一法也用来决定第一个分类器的软分类器的后验概率阈值。这个阈值用来选择第一个分类器的哪些项会作为候选送到第二个分类步骤。这个阈值的选择要使得训练集中90%的真结节都可以正确的被分类器区分。
最终分类器也有个类似的后验概率,也是使得训练集上90%的真结节可以被 区分。结节检测完之后,这些结果会被保存,减小此阈值可以使得系统低灵敏度性能。论文的余下工作是此系统的操作点的变化。
4.1 训练集和测试集的生成
生成训练集的关键是应该收集哪种条件下的数据集,使得它们在测试阶段尽可能靠近。例如第二个分类阶段的训练集,应该是由被训练好的初始KNN分类器标记为正的候选组成。因此,我们使用了一个三步训练集生成过程, 最终训练集中Steps123_c1作为第一个分类器,Steps123_c2作为第二个分类器的训练集。过程如上图。
用于训练的scans随机分为三个差不多大小的组,Scans_Step1,Scans_Step2和Scans_Step3。第一步我们在Scans_Steps的图片上做的初始候选检测,并使用生成的候选(有ground-truth信息的)来创建第一步分类所需的特征。由于没有先验训练数据集,所以没法在Scans_Step1的数据集上训练KNN分类器。
第二步,我们使用Scans_Step2中的图像,如第一步一样,我们检测初始候选并构建第一个分类器的合适的训练集。接着,使用第一步构建的训练集来训练KNN分类器并做一个初始分类来减少假阳性样本数。第一个分类器之后剩余的候选合并之后用于构建一个训练集,该训练集包含了第二步分类所需的全部特征。
第三步使用Scans_Step3的图像,并重复第二步的过程。不同之处在于,第一个分类器所使用的训练集来自第一步和第二步处理之后的数据的融合。将第三步独立出来而不是将第二、三步合并的原因是,在第三步融合的数据上训练时可以获得比第二步骤中的第一个分类器更精确的输出结果。
这种方式产生的训练集将包含更多的假样本,真样本较少。为此,我们在每个训练步骤的最后减小了阴性(假)数据分类,比如每个数据集中的阴性:阳性比例大致为3:1。这个比例被证明可以在测试阶段获得较优的结果。移除阴性样本使用的是缩合方法(Mitra etal 2002),为了不改变样本分布。此方法从一个较大的数据中从多种尺寸选择点来产生了一个小的表征子集。子集表征的准确率以原始数据集和缩减之后的数据集的密度评估误差来衡量。参数$K$值决定了浏览哪种尺寸的数据。本论文中 $K$ 的初始值设置为15,阴性样本集不断缩减直至目标数目(3倍的阳性样本数)。然后参数 $K$ 再次衰减。此循环至 $k\le 2$ 或者数据集已经达到了目标数量。
4.2 初始KNN分类器
第一个KNN分类器,总共18个特征需要在特征选取之前计算。整个需要计算的特征列表如表下表
下表是 Features of the voxel cluster
| ID | Description | Notes |
|---|---|---|
| a1 | Cluster size (number of voxels) | - |
| a2 | Compactness1,$\frac{ClusterSize}{(dim_x)(dim_y)(dim_z)}$ | $dim_i=width\quad in \quad dim.i$ |
| a3 | Compactness2,$\frac{ClusterSize}{max_dim^3}$ | $max_dim=max_i(dim_i)$ |
| a4 | Ratio max_dim:min_dim | min_dim = mini(dimi) |
| a5 | Ratio max_dim:med_dim | med_dim = mediani(dimi) |
| a6 | Ratio Amed:Amax where Amax, Amed and Amin are the eigenvalues for the eigenvectors of the cluster data by principal component analysis | - |
| a7 | Ratio Amin:Amax | as for a6 above |
| a8 | Sphericity, $\frac{num_cluster_voxels_in_sphere_S}{vol_sphere_s}$ where sphere_S is a sphere at the candidate location with radius r | - |
| a9 | Ratio Sphericity:r | - |
下表是 Features of voxels in spherical kernels at the candidate location
| ID | Description | Notes |
|---|---|---|
| a10-a18 | On grey-values over spherical kernels K: Average, Median, Standard-Deviation | Halfsizes of K: 1 (a10-a12), 3 (a13-a15), r (a16-a18) |
上面两张表其实是一张表,由于markdown不支持表合并。
,其ID将会在此文后续引用。详细的关于那个特征会被SFFS选取在不同的实验里面不相同,如下表
分类器一
| ID | A | B | C |
|---|---|---|---|
| a1 | 1 | 1 | 1 |
| a2 | 0 | 1 | 0 |
| a3 | 1 | 0 | 1 |
| a4 | 0 | 0 | 1 |
| a7 | 0 | 0 | 1 |
| a8 | 1 | 1 | 0 |
| a9 | 0 | 1 | 0 |
| a10 | 1 | 1 | 1 |
| a11 | 1 | 1 | 1 |
| a12 | 1 | 0 | 1 |
| a13 | 1 | 0 | 0 |
| a14 | 1 | 0 | 1 |
| a15 | 1 | 0 | 1 |
| a16 | 1 | 0 | 1 |
| a17 | 0 | 1 | 0 |
| a18 | 0 | 1 | 0 |
| Total | 10 | 8 | 10 |
分类器二
| ID | A | B | C |
|---|---|---|---|
| b1 | 1 | 1 | 1 |
| b5 | 0 | 0 | 1 |
| b7 | 0 | 0 | 1 |
| b8 | 0 | 0 | 1 |
| b12 | 0 | 1 | 0 |
| b13 | 0 | 0 | 1 |
| b21 | 0 | 0 | 1 |
| b22 | 0 | 1 | 0 |
| b24 | 0 | 0 | 1 |
| b25 | 1 | 0 | 0 |
| b26 | 0 | 0 | 1 |
| b27 | 0 | 0 | 1 |
| b28 | 0 | 1 | 1 |
| b29 | 1 | 1 | 0 |
| b36 | 0 | 0 | 1 |
| b39 | 0 | 0 | 1 |
| b40 | 0 | 0 | 1 |
| b41 | 1 | 0 | 1 |
| b44 | 0 | 0 | 1 |
| b45 | 0 | 0 | 1 |
| b46 | 0 | 0 | 1 |
| b49 | 0 | 0 | 1 |
| b52 | 1 | 0 | 0 |
| b54 | 0 | 0 | 1 |
| b55 | 1 | 0 | 0 |
| b56 | 1 | 0 | 0 |
| b57 | 0 | 0 | 1 |
| b58 | 0 | 1 | 1 |
| b62 | 0 | 1 | 1 |
| b64 | 1 | 0 | 1 |
| b65 | 1 | 1 | 1 |
| b66 | 0 | 1 | 1 |
| b67 | 0 | 1 | 0 |
| b68 | 1 | 0 | 0 |
| b70 | 1 | 0 | 0 |
| b72 | 0 | 0 | 1 |
| b75 | 1 | 0 | 1 |
| b79 | 0 | 1 | 0 |
| b83 | 0 | 1 | 1 |
| b90 | 0 | 0 | 1 |
| b92 | 0 | 0 | 1 |
| b93 | 0 | 0 | 1 |
| b94 | 0 | 0 | 1 |
| b103 | 1 | 0 | 1 |
| b107 | 0 | 0 | 1 |
| b113 | 0 | 1 | 0 |
| b115 | 0 | 0 | 1 |
| b116 | 0 | 0 | 1 |
| b120 | 1 | 1 | 0 |
| b122 | 0 | 1 | 0 |
| b123 | 1 | 1 | 1 |
| b124 | 1 | 0 | 1 |
| b125 | 1 | 0 | 1 |
| b126 | 1 | 0 | 1 |
| b129 | 0 | 0 | 1 |
| b130 | 0 | 0 | 1 |
| b131 | 0 | 1 | 0 |
| b134 | 1 | 1 | 1 |
| b135 | 1 | 1 | 1 |
| Total | 20 | 19 | 44 |
此阶段计算的特征与初始候选检测(a1-a9)步骤的体素cluster几何属性相关,也与候选位置周围区域的灰度值(a10-a18)。体素cluster的形状提供了一个线索,即其结构是细长(比如,像血管)还是类似球状,同时其尺寸在不同的阴性和阳性候选也是极有价值的。灰度值特征都是使用候选位置周围的球形体素kernel校验过的,以移除不在不在不够明亮区域的结构。注意,表中体素cluster的半径以r表述。此半径的计算是用X,Y,Z轴三个方向的cluster的最大半径的除以3得到的均值为平均直径,除以2得到平均半径。其中的kernel halfsize指的是问题中的球形kernel体素半径。
第一个分类器结束之后,候选需要合并(4.4节)。尽管原始的合并步骤已经很详细了,后续的位置调整步骤(4.5节)意味着进一步的合并成为可能。尤其当位置调整过程中将两个候选置于相同位置时,需要检查合并的可能性。只有当第一分类器结束之后合并才可以做,因为此阶段的假阳性数目已经缩减了,同时阴性和阳性样本之间的非法合并的概率也大幅度缩减。4.5节讲述的是结节位置合并之后需要再次调整最明亮的局部点。
4.3 最终KNN分类器
最终分类器需要计算的135个特征全集在下表,其指明了ID。
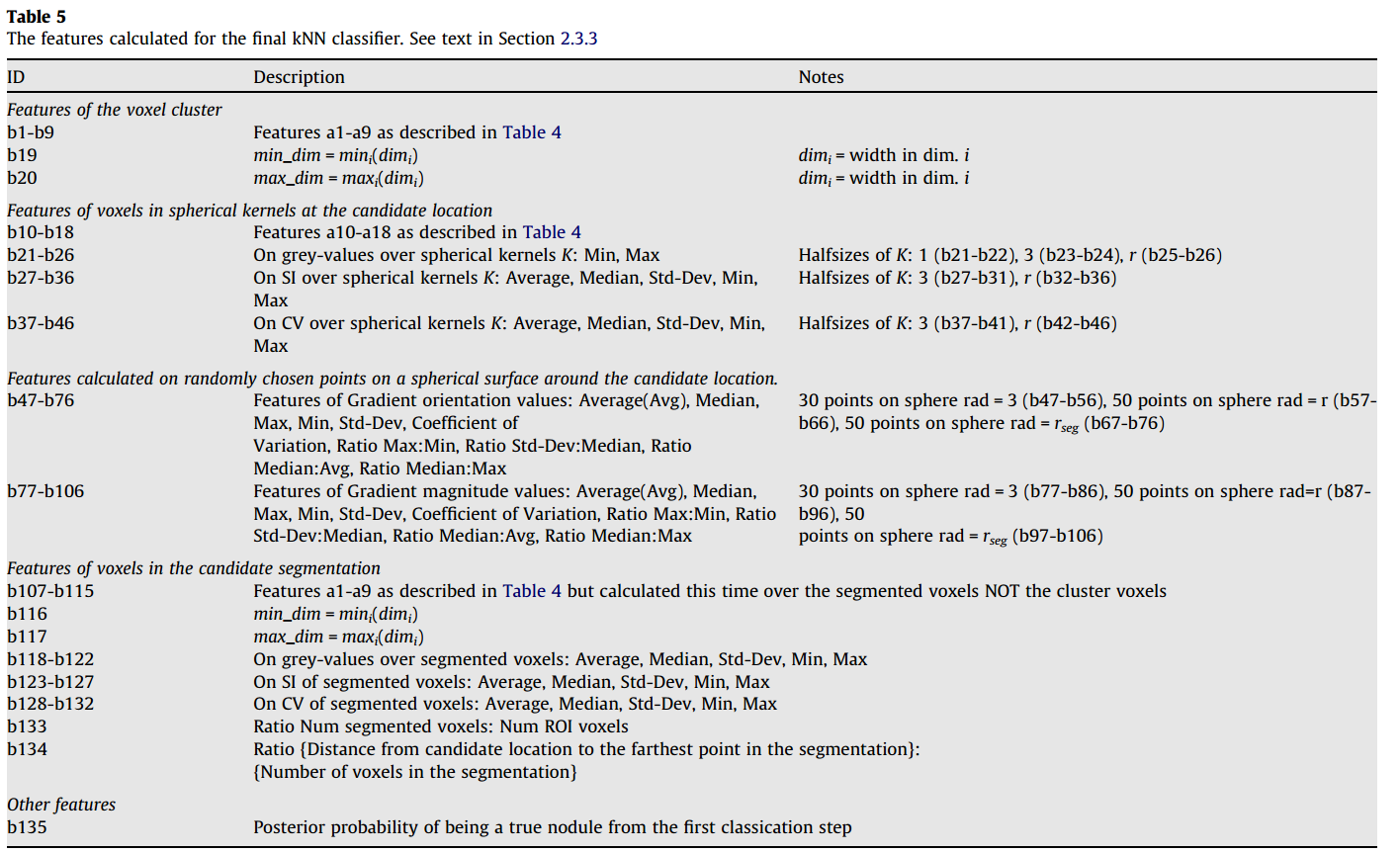
其中 $r_{reg}$指的是使用相同方式计算的包含结节切割体素的半径。
所有在第一个分类器中计算的特征都被重弄使用(b1-b18),并且被第一个分类器计算的结构为真结节的后验概率,成为第二阶段的计算特征。
除了结构(b47-b106)中心假象球面中心的梯度方向和大小外,候选位置的球形kernel的SI和SV值特征此次会被相加(b27-b46)。大部分真结节,其形状是大致球形并且梯度范围也是大致对称的。对于真阳性,我们期望其梯度大小在生成的球形表面所有点都是差不多的,同时梯度方向类似于一个正常的球面。这些特征都是在不同尺寸的球面上随机挑选的点来计算的。特定尺寸的球面随机抽样的点的数目是预先经验值设置的。梯度方向是径向的一部分,并且在点p处被定义为 $r\dot g/|r||g|$,其中g是点p处的梯度向量,r是从球状中心到点p的半径向量。
我们使用文章(Kostis et al 2003)提出的一种算法切割候选结构,为了计算切割对象的特征。为了提高切割准确率,此切割过程只在候选位置的感兴趣区域ROI,但是注意是直接从全分辨率图像中抽取的而不是subsample版本的数据集中。之所以这么做是因为在subsample中切割更容易失败,为后续处理的方便起见切割体素的坐标被转换为subsample图像的等同的值。被计算的切割的体素特征与初始检测的体素cluster的大体相似。这些特征用来决定被切割的对象的尺寸和形状与真实结节是否相称,同时我们期望好的切割应该比从初始体素cluster获得更准确的特征信息。
最后,候选合并过程将不止一次地被执行(如前面描述的,第一步的KNN分类之后进行位置调整后可能需要进行新的合并操作),最终位置将会被调整到局部最亮点。此步骤主要是确保每个标注只找到一个检测(这样就不用将剩余准确检测算为假阳性了)
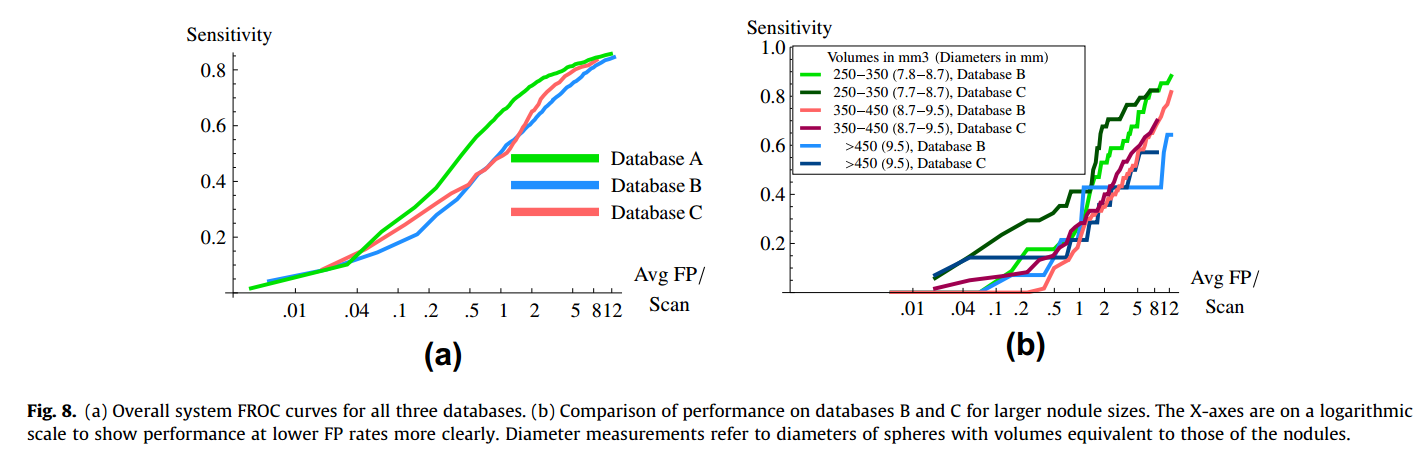
5 结果
5.1 数据集A
数据集A的训练集已经在上文有提及。初始的750个scans随机分为三组,每组250个,被用在训练集生成的三个步骤。移除scans中肺部切割失败的,三组分别包含了242,243,237个scans。
初始分类器的训练集包含5776个样本,1351个是真结节,第一个分类器的训练集包含3436个样本,819个真结节。
测试阶段开始于SFFS特征选取过程,如上表( 分类器二)中为每个分类器选取的特征。第一个分类器处理了10个选取的特征,最终分类器使用了全部的20个特征。测试集中移除切割失败的scans之后还有813个。
数据集A中的结节检测结果如下表,其中的FROC曲线通过改变如下图的最终分类器的操作点得到的。
检测结果表
| Number of Scans | 813 | |
|---|---|---|
| Number of annotations | 1525 | |
| Sensitivity | FP per scan | |
| After initial candidate detection | 97.2% | 649.0 |
| After first classification | 92.3% | 77.3 |
| After final classification | ||
| -At around 4 FP per scan | 80.0% | 4.2 |
最终分类器的操作点变化图
5.2 数据集B
此数据集包含了的scans至少包含了一个结节(根据其尺寸和物理属性)。这些scans中的大部分包含了其他更小的或者不明显的结节,即此数据集的结节尺寸变化很广。
训练集的构造上文已经提及。600个训练scans被分为3组,每组200个scans,用于三个生成步骤。这个划分是完全随机的,除了有确定的14个病人被划分到第三个数据集Scans_Step3。去除肺切割失败的样本之后,三个数据集分别包含192,196和193个样本。
初始分类器的训练集包含了7868个样本,1715个是真结节,最终分类器包含4490个样本,其中1090个真正样本。样本分布如下:
测试阶段的开始时进行SFFS特征选取,SFFS选取的特征遵循上面的表(分类器二),用于给每个分类器。给初始分类器8个特征,给最终分类器19个特征。测试数据集在移除了非切割失败的样本之后有541个scans。
表8演示了数据集B的结节检测结果,并在上图Fig8中展示了FROC曲线。从数据集B中选取的结节如下图。这些结节都是由系统以不同程度的概率(后验概率)检测到的。
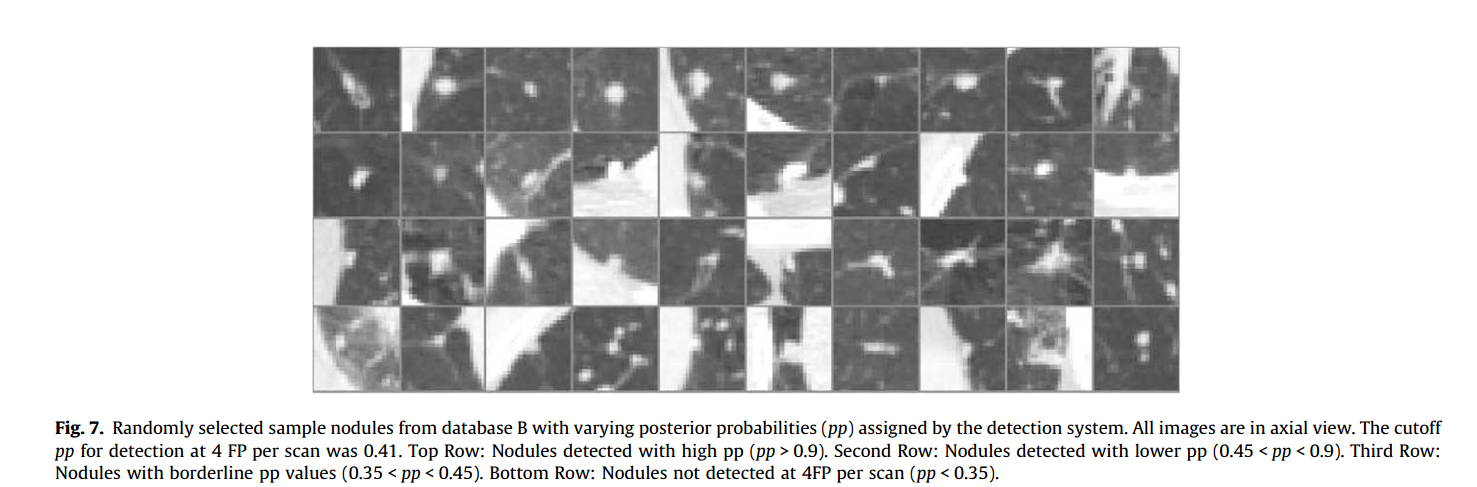
基于上图这样的小数据集很难概括,尤其是结节的3D结构信息很难从这些图像中获取。但是可以看到首行的结节是使用0.9的先验概率检测到的,通常有差不多的球形外形并且在局部有很明显的特征。第二行的结节先验概率为[0.45,0.9],它们有着相似的特征,并且平均每个scans有4个假阳性的灵敏度可以检测到。第三行的结节先验概率范围是[0.35,0.45],边界线上的点周围检测准确率是每个scans有4个假阳性。球状外形不明显或者/同时结构或表面相靠近的结节较难检测到。最底层的一行结节是每个scans4个假阳性时无法检测到的,先验概率为小于0.35。可以看到这些结节有着怪异的形状或者位于混杂的结构或外形中,或者处于病理区域内。
5.3 数据集C
此数据集有着与数据集B十分相似的图像,但是只有容积大于$50mm^3$ 的结节被放入训练集和测试集。数据分组如5.2节一样,只不过只使用容积大于 $50mm^3$ 。初始分类器的训练集包含了3127个样本,748个真结节。最终分类器的训练集包含了1900个样本,465个真结节。
测试阶段,SFFS特征选取过程也是按照上表(分类器二)。初始分类器使用10个特征,最终分类器使用全部的44个特征。测试阶段的scans数目,在移除肺切割失败样本之后包含了541个scans。
其检测结果如下表,FROC如上图
| Number of Scans | 541 | |
|---|---|---|
| Number of annotations | 768 | |
| Sensitivity | FP per scan | |
| After initial candidate detection | 98.2% | 752.1 |
| After first classification | 92.2% | 51.2 |
| After final classification | ||
| -At around 4 FP per scan | 77.7% | 4.2 |