一 简介
目前主流的三类人脸识别方法。
- 最经典的是增强级联框架(boosted cascade framework)。这些检测器(detector)计算高效,可快速抽取特征。
- 为了处理精确处理面部变化较大,DPM(deformable part models可变形部件模型):用以同时抽取图像的全局和局部特征。它基于一种覆盖分类内部变化的启发式方法,因此对于图像中人物表情姿势的变化有较好鲁棒性。但是非常耗时。
- 最新的是使用CNN卷积神经网络的方法。缺点是计算代价高,因为网络得复杂性和许多复杂的非线性操作。
以上工作都没有考虑特殊场景,比如多角度人脸识别。为了多角度识别人脸,一种直接的方法就是并行使用多个人脸检测器(detector)。并行架构需要所有候选窗口被所有模型分类,这导致计算成本和误报率的飙升。为缓解此类问题,所有模型需要精心地训练,使模型具有较好的区分能力去辨别人脸和非人脸。
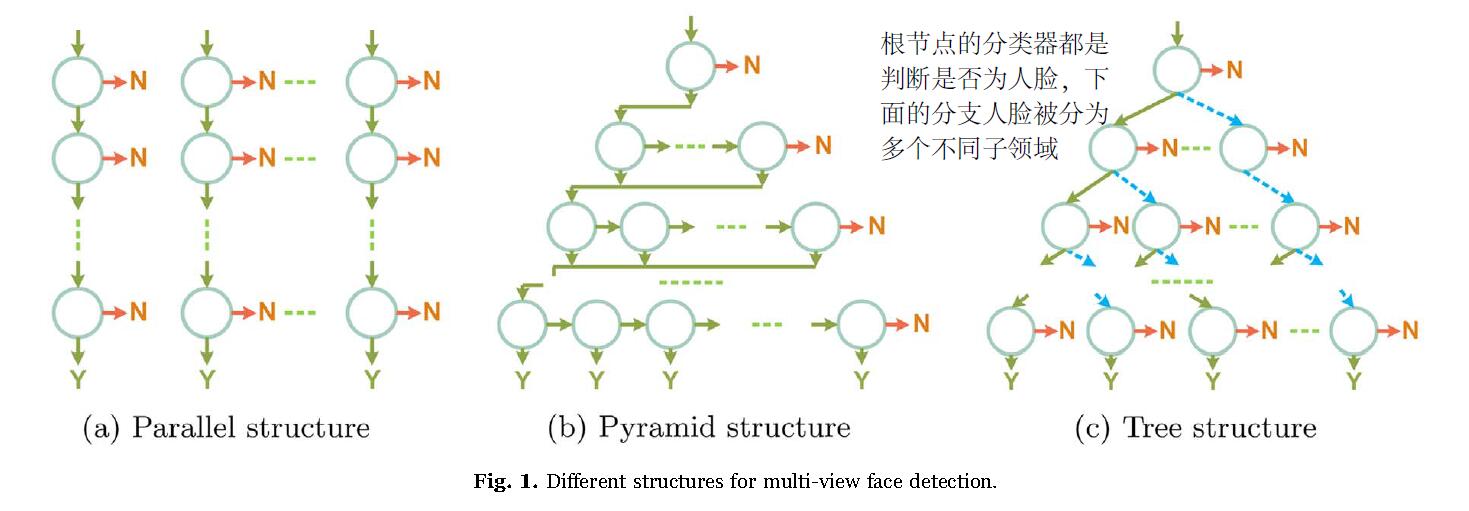
多视角的多模型可以如上图这样组织成树形或金字塔形。这些结构中,根分类器都是区分是否为人脸,接下来的其他分类模型将人脸按照不同的精细粒度分为不同子分类,这里的每个模型都是独立的。金字塔模型实际是将共享了某些高层节点的模型压缩了,因此金字塔模型与并行模型有一样的问题。树形结构分类器不同之处在于,分支的动机是避免在同一层评估所有的分类器,但是这会导致检测错误分类分支。
为此我们提出了一种漏斗形级联的多视角人脸检测结构,获得较高准确率和较快速度。该结构上宽下窄,模型如下图。
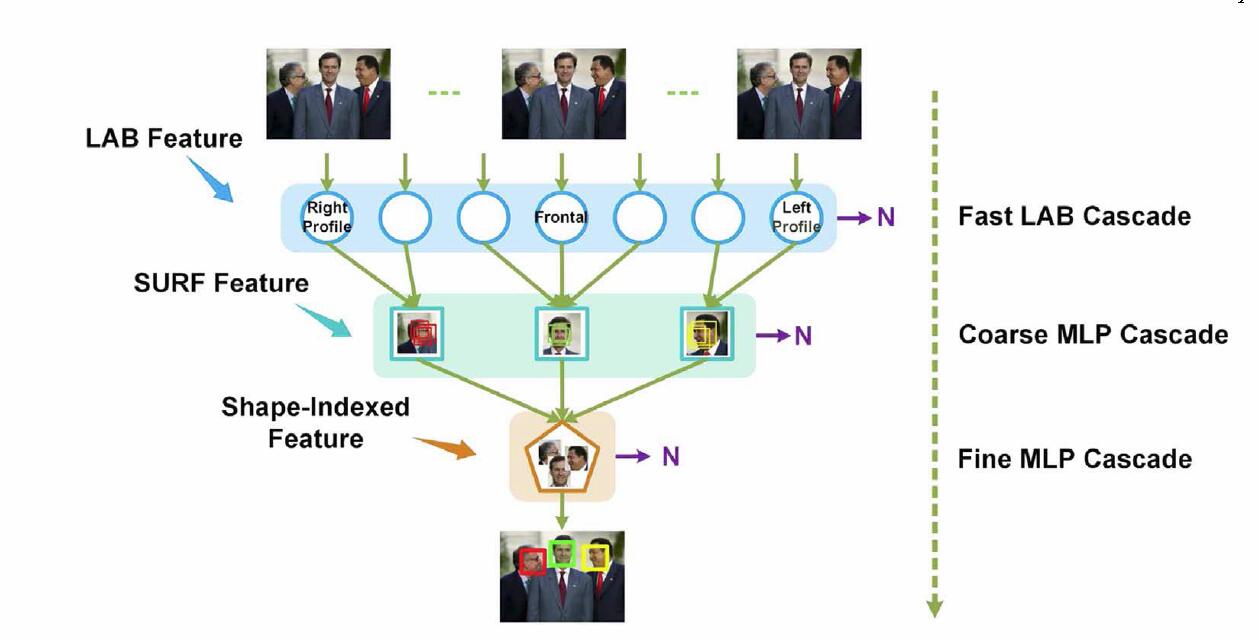
模型的顶层是一些并行运行的,快速而粗粒度的分类器,用来快速地移除非人脸窗口。每个模型都是针对性地使用一小段区间范围的视角的人脸,因而可以保证多角度人脸的较高召回率。越往下,模型的区分能力越强,但是也越耗时,它们被用来筛选符合条件的窗口候选。模型的底部收集最后通过的窗口,最后一阶段是一个统一的多层干感知机。
二 漏斗结构级联的多视角人脸检测器
输入图像根据滑动窗口树状图扫描,然后每个窗口依次分阶段地穿过探测器。
Fast LAB接连分类器用来快速移除大部分非人脸窗口,(LAB(Locally Assembled Binary))同时保证人脸窗口的较高召回率。Coarse MLP Cascade分类器以较低代价来进一步调整候选窗口。最后,统一Fine MLP Cascade分类器使用形状索引特征精确地区分人脸。
2.1 Fast LAB cascade
实时人脸识别时,最大的障碍在于需要检验的滑动窗口树状图的候选窗口太多。在一个640x480的图像上,要检测脸特征尺寸超过20x20的人脸,需要检查超过一百万个窗口。使用增强级联分类器,由Yan et al提出了一种有效的LAB((Locally Assembled Binary),只需要考虑Haar 特征的相对关系,并使用look-up(查阅表)加速。一个窗口中抽取一个LAB特征仅需要访问内存一次。我们可以使用LAB 特征,可以在程序开始时快速地移除占比非常大的非人脸特征。
尽管LAB 特征方法有速度,但是对于多角度人脸窗口的复杂变换表现较差。因此我们采取了一种分而治之的思路,将较难的多视角人脸问题分解为容易的单视角人脸检测问题。多个LAB 级联分类器,每个角度一个分类器,并行处理,然后最终的候选人脸窗口是所有经分类器筛选过后的结果合集。
公式:定义整个包含了多角度人脸的训练集为 S,根据角度划分为 v 个子集,
定义为 $S_i,i=1,2,…v$ 。对每个训练集 $S_i$ ,一个LAB级联分类器 $c_i$ 被训练,它用于检测第 $i$ 个角度的人脸。对于输入图像中的窗口 $x$ ,它是否为人脸取决于如下所有的LAB 级联分类器:
$$
y=c_i(x)\vee c_2(x)…\vee c_v(x)
$$
其中 $y \epsilon \lbrace0,1\rbrace$ ,$c_i(x)\epsilon \lbrace0,1\rbrace$ 表明 $x$ 是否为人脸。使用多模型消耗更多时间,但是所有模型共享相同的LAB特征映射(用来特征抽取)。
2.2 Coarse MLP cascade 粗粒度多层感知机级联
LAB级联阶段之后,大部分非人脸窗口被抛弃,剩下的部分对于单个LAB 特征难以处理。因此,接下来,候选窗口将交给更复杂的分类器来处理,比如带 SURF(Speeded-up Robust Feature) 的MLP。为避免增加太多计算,小型网络被开发为更好,但是依旧粗粒度的校验。
此外,使用SURF特征的MLP用于窗口分类,可以更好的建模非线性多角度人脸和带有等同的非线性激活函数的非人脸模式。
MLP由输入层,输出层和一个或多个隐藏层组成。公式化n层的MLP如下:
$$
F(x)=f_{n-1}(f_{n-2}(…f_1(x)))\quad tag 2\
f_i(z)=\sigma(W_iz+b_i)
$$
其中 $x$ 是输入,比如候选窗口的SURF特征; $W_i$ 和 $b_i$ 分别为链接第 $i$ 层和第 $i+1$ 层的权重和偏置。激活函数 $\sigma$ 形如: $\sigma (x)=\frac{1}{1+e^{-x}}$ ,从上式可以看出,隐藏层和输出都做了非线性变换。MLP的训练目标是最小化预测值和实际值之间的均方误差
$$
min_F\sum_{i=1}^n \mid \mid F(x_i)-y_i \mid \mid ^2
$$
其中 $x_i$ 是第 $i$ 个训练样本, $y_i$ 是对应的标签(0或1)。
由于MLP级联分类器有足够能力建模人脸和非人脸变换,穿过多个LAB级联分类器之间的窗口可以由同一个模型处理,也即MLP级联可以连接多个LAB级联分类器。
2.3 带形状索引特征的细粒度MLP级联
多视角人脸外貌之间存在一些冲突,主要源于非对齐特征,比如基于坐标抽取的特征存在语义不一致问题。比如,一个面向前方的人脸的中央区域包含了鼻子,但是面部外形也是脖子的一部分。为解决这个问题,我们采取了一种基于形状索引的方法在语义相同的位置上抽取特征作为细粒度MLP级联分类器的输入。如下图所示,选择了四个语义位置,分别对应的面部坐标是左、右眼中心,鼻尖和嘴中心。对于侧脸,不可见的眼部被视为与另外一只眼睛处于相同坐标。

对于表情更丰富的基于形状索引的特征,更大、性能更强的非线性变换用来实现面部和非面部微调。与之前的不同的是,更大的MLPs同时预测标签,推测一个候选窗口是否为一张脸,推测其形状。一个额外的形状预测误差项加入到目标函数,新的优化问题变为如下:
$$
min_F \sum_{i=1}^n \mid \mid F_c(\phi (x_i,\hat S_i))-y_i \mid \mid ^2+\lambda \sum_{i=1}^n \mid\mid F_s(\phi (x_i-\hat S_i))-s_i \mid\mid ^2_2
$$
其中 $F_c$ 是面部分类输出, $F_s$ 是预测形状输出。 $\phi (x_i,\hat s_i)$ 代表的是基于形状索引的特征(比如SIFT),它是按照平均形状或预测形状为 $\hat s_i$ 从第 $i$ 个训练样本抽取的,其中 $s_i$ 是实际形状。 $\lambda$ 是平衡两类误差的权重因子,一般设置为 $\frac{1}{d}$,其中d为形状的维度。从上面的等式可以看出,可以获得一个比输入 $\hat s_i$更精确地外形 $F_s(\phi(x_i,\hat s_i))$ (注意看下标)。因此,多个级联的MLPs,用于特征抽取的形状越来越精确,这会获得更加有区分力的基于形状索引的特征,并且最后让多角度人脸与非人脸区域差异更大。下图展示了这一过程: