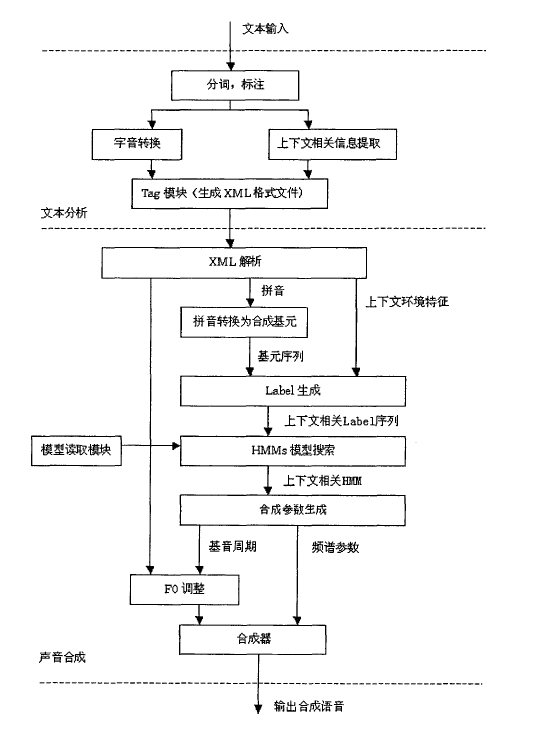
一 概念
从数据中抽取音高(Pitch)之后,我们发现无法对音高建模,因为数据中同时存在离散和连续的值。
1.1 多空间概率分布
多空间概率分布的示意图如下:
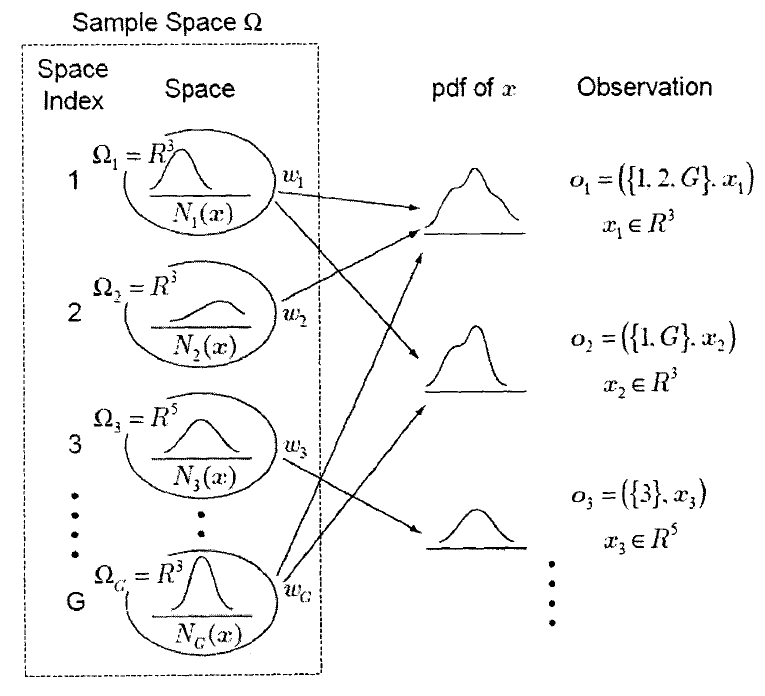
如上图M的一个样本空间由G个空间构成:,其中$\Omega _g^{g=1}$是一个 $n_g$维的空间$R^{n_g}$。每个空间都有自己的维度,其中一些可能有着相同的维度。每个空间$\Omega _g$都有其出现的概率$w_g$,即$P(\Omega)=w_g$,其中$\sum _{g=1} ^Gw_g=1$如果$n_g>0$则每个空间都有一个概率密度函数$N_g(x),x\epsilon R^{n_g}$ 。如果$n_g$=0则认为$\Omega _g$仅包括一个样点,且概率$P(\Omega)$被定义为$P(\Omega)=1$。
一个具体问题来解释这个过程。
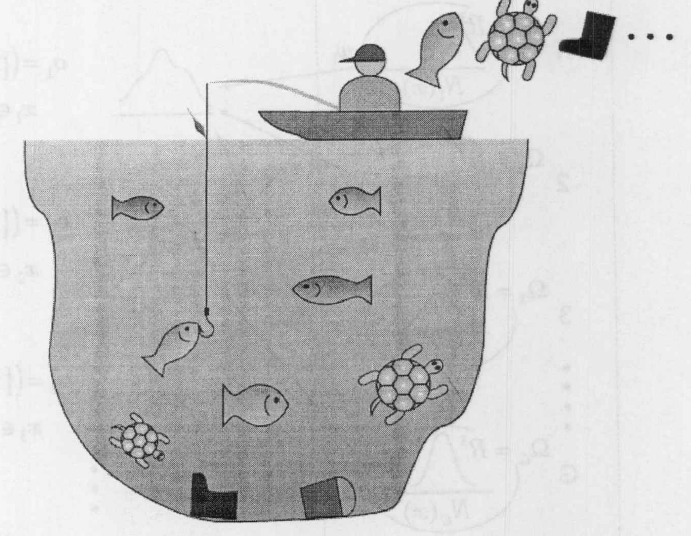
一个人在池塘钓鱼。池塘中有红色的鱼,蓝色的鱼以及乌龟,此外,水中还有一些垃圾。当这个人钓到一条鱼的时候,他会观察鱼的种类和大小,如长度和重量当他钓到一只乌龟,则会观察乌龟壳的直径这里假设乌龟壳是圆形的而当他钓上一些垃圾的时候,则不会关心垃圾的任何属性。在这个例子中,我们可以看到全部的样本空间由四个空间组成。
- $\Omega _1$ ,二维的空间,代表着红色的鱼的长度及重量。
- $\Omega _2$ ,二维的空间,代表着蓝色的鱼的长度及重量。
- $\Omega _3$ ,一维的空间,代表着乌龟壳的直径。
- $\Omega _4$ ,零维的空间,代表垃圾
权重 $w_1,w_2,w_3,w_4$ 由池塘中红鱼蓝鱼,乌龟和垃圾所占的比例所决定。函数$N_1(\dot)$ 和 $N_2(\dot)$ 分别是关于红鱼和蓝鱼大小的二维概率密度函数长度和重量。函数 $N_3(\dot)$ 则是关于乌龟的一维的概率密度函数。例如这个人钓到一条红鱼,则观察向量 $o=(\lbrace 1\rbrace,x)$ 。其中 $x$ 为一个两维的向量,代表红鱼的长度和重量。假设这个人日夜不停的钓鱼,如果在夜晚,他无法区分鱼的颜色,只能丈量鱼的长度和重量,在这种情况下,鱼的观测向量$o=(\lbrace 1,2 \rbrace,x)$
1.2 MSD-HMM
根据上述多空间概率分布的定义,人们提出了一MSD-HMM结构如下图所示。
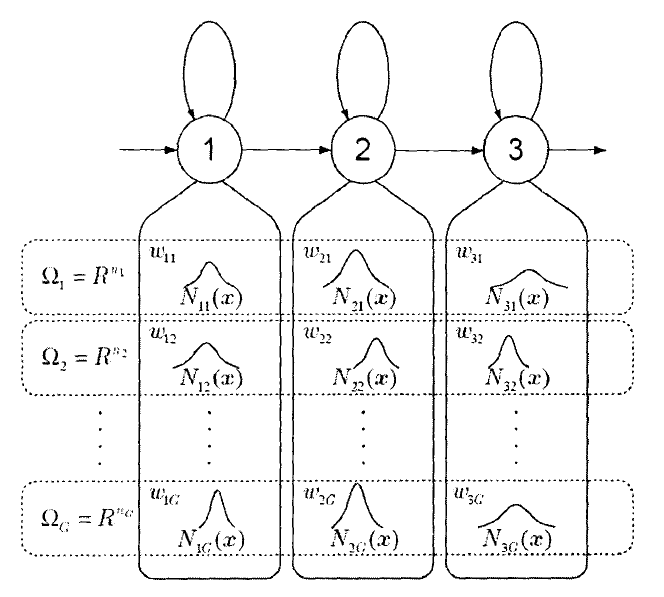
MSD-HMM的初始分布 $\pi$ 二及转移矩阵A都与其他的HMM相同,此处仅给出状态输出分布概率:
$$
b_i(o)=\sum {g\belong S(o)}w{ig}N_{ig}(V(o))
$$
实际上,MSD-HMM同时包含了连续HMM和离散HMM。当 $n_g=0$ 时MSD-HMM与离散HMM是完全相同的。当 $S(o_t)$ 代表且仅代表一个特定的空间时,MSD-HMM则与连续HMM相同。由于MSD-HMM的这个特性,它很适合用于描述语音信号中基音周期。
二 上下文相关的声学建模技术
在连续的语音中,人们的发音普遍会受到上下文的影响而发生变化,这就是连续语音之间的协同发音现象。上下文无关的建模方法对每个识别基元分别独立建模,忽略了这种协同发音的现象,因而采用上下文无关模型的语音合成系统,其合成语音会出现不连贯或一字一顿等现象,所以无法取得较高的自然度。解决这个问题的方法是使用上下文相关的建模方法。上下文相关的建模方法在语音识别中有很多的应用,在语音合成中,我们也可以采用这个方法。与上下文无关的建模方法相比,上下文相关建模方法需要考虑如下的几个问题:
如何选取基本识别基元。对于汉语语音系统而言,常用的基本基元有音节、声韵母和音素。由于汉语有个无调音节,如考虑语调则超过个音节,如果考虑上下文相关的变化,则会由于基元数目太多而导致模型无法实现。而声韵母与音素的数目都相对很少,因此可以用来作为上下文相关模型的基元
如何降低模型的规模。即使采用声韵母或音素作为上下文相关模型的基元,模型的规模仍然非常巨大。假设基元的个数为,则有,个可能的上下文相关基元。如果每个基元分为五个状态,每个状态采用单个高斯分布来描述,系统中仍然有,个高斯分布,如此大规模的模型会导致系统的速度下降,模型存储空间占用巨大,而且在训练数据库不是足够大的情况下,很多基元会存在训练不充分的问题。解决的办法是采用参数共享的技术。例如进行状态共享建模,或者混合密度共享建模。
如何预测在训练数据中没有出现的基元。在上下文相关的声学模型中,由于训练数据的限制,有些基元可能在训练数据中完全不出现,但是可能出现在待合成的数据中。为了保证合成过程的顺利进行,我们必须采取的补救措施保证每个基元都能找到模型描述。通常使用的方法是基于决策树的策略,使用那些可见基元的分布来合成在训练数据中不可见的基元。
在实际中的上下文相关声学建模技术中,通常采用决策树与状态共享相结合的策略,这样既可以降低模型规模,避免训练不充分问题,还可以有效合成那些训练数据中不可见的基元。
2.1 合成基元的选择
音节: 汉语约有个无调音节和多个有调音节。在进行上下文无关的声学建模时,选用音节作为基元可以取得比较好的性能。但如果使用上下文相关的建模,由前接一当前一后续所组成的元组的数目将过于庞大,故采用音节作为基元并不合适。
音素:汉语有大约个音素,但音素并没有反映出汉语语音的特点,而且,相对于声韵母,音素显得十分不稳定,这就给标注带来了困难,进而影响声学建模。
声韵母
声韵结构是汉语音节特有的结构,使用声韵母基元,可以利用已有的语言学知识,进而提高声学模型的性能
使用声韵母作为识别基元,上下文相关信息也变得比较确定
选择声韵母作为基元,使得语音段的长度和基元数目比较适当
声韵母作为基元
基元的定义
| 基元 | 元素 |
|---|---|
| 声母 | b、p、m、f、d、t、n、l、g、k、h、j、q、x、zh、ch、sh、z、c、s 、 y、w、r,_A,_E,_I,_O,_U |
| 韵母 | ai 、ei、 ui 、ao、 ou、 iu 、ie 、ve、 er、 an 、en 、in、 un 、vn 、ang 、eng、 ing 、ong ,an 、en 、in、 un 、vn,ang 、eng、 ing 、ong |
三 基于决策树的状态共享
根据上面定义的基本基元,以这些基本基元为中心,考虑它们上下文相关的情况,我们可以将每个上下文相关的基元表示为 $l-c+r/env$ 的方式,其中 $c$ 为中心基元,$l$ 为左相关信息,$r$ 为右相关信息,$env$ 则表示该基元所在位置的一些环境特征。本系统中,环境特征包括前接音节字调,当前音节字调,后续音节字调,当前音节到前一自然停处的字数,当前音节到后一自然停顿处的字数,前接词的词性,当前词的词性,后续词的词性,当前音节在当前词中的位置,当前词的音节数,音节所在句的长度。
$$
L-C+R/A:a1_a2_a3/B:b1_b2/C:c1_c2_c3/D:d1_d2/E:e
$$
其中 $C$ 代表当前元,$L$ 代表前接基元,$R$ 代表后接基元,$ABCDE$ 几项代表当前基元的上下文相关的一些特征。$a1$ 为前接字字调,$a2$ 为当前字字调,$a3$ 为后接字字调,$b?$ 为基元所在的字在当前停顿段落短语或短句中的位置,$b1$ 为到段落开始字的距离,$b2$ 为到段落结束字的距离,$c1$ 为前接词的词性, $c2$ 为当前词的词性,$c3$ 为后接词的词性,$d1$ 为当前字在当前词中的位置,为 $d2$ 当前词的字数, $e$ 为句子的总字数。为了将发音相似的基元共享到一起。本系统中使用决策树来实现参数共享的策略。这样做的好处是
一是降低模型的规模
二是避免由于训练数据的稀疏性而造成训练不充分的问题
三是可以近似合成那些在训练数据中不存在的基元。
示例
例如“他见了人就甜牙吠咬,咬住就不撒嘴”一句中的“见”字的韵母的标注为:
$$
j-ian4+1/A:1_4_5/B:2_3/C:r_v_u/D:1_1/E:15
$$
3.1 决策树划分特征的确定
决策树的分裂依赖于问题集的设计。为了定义问题集,我们首先来确认划分特征。划分特征包括两大类,发音相似性和基元的上下文相关信息。
其中发音相似性的特征有以下几类,韵母划分特征,声母划分特征,单音划分特征。此划分,每个人不一样
声母的特征划分
| 划分特征 | 描述 | 基元列表 |
|---|---|---|
| Stop | 塞音 | b,d,g,p,t,k |
| Aspirated Stop | 塞送气音 | b,d,g |
| Unaspirated Stop | 非塞送气音 | p,t,k |
| Affricate | 塞擦音 | z,zh,j,c,ch,q |
| Aspirated Affricate | 塞擦送气音 | z,zh,j |
| Unaspirated Affricate | 非塞擦送气音 | C,zh,q |
| Fricative | 擦音 | f,s,sh,x,h,r |
| Fricative 2 | 擦音2 | f,s,sh,x,h,r,k |
| Voiceless Fricative | 擦清音 | f,s,sh,x,h |
| Voice Fricative | 浊清音 | r,k |
| Nasal | 鼻音 | m,n, |
| Nasal 2 | 鼻音2 | m,n,l |
| Labial | 唇音 | B,p,m |
| Labial 2 | 唇音2 | B,p,m,f |
| Apical | 顶音 | Z,c,s,d,t,n,l,zh,sh,r |
| Apical Front | 顶前音 | Z,c,s |
| Apical 1 | 顶音1 | D,t,n,l |
| Apical 2 | 顶音2 | D,t |
| Apical 3 | 顶音3 | N,l |
| Apical End | 顶后音1 | Zh,ch,sh |
| Apical End 2 | 顶后音2 | Zh,ch,sh |
| Tongue Top | 舌前音 | J,q,x |
| Tongue Root | 舌根音 | G,k,h |
| Zero | 零声母 | _A,_E,_I,_O,_U,_V |
| XFuyin | 全部声母(包含零声母) | 全部 |
| Fuyin | 全部声母(不包含零声母) | 不包含零声母 |
韵母的划分特征
| 划分特征 | 描述 | 基元特征 |
|---|---|---|
| Single Yun | 单韵母 | A,I,u,e,v,ic,ih |
| Com Yun | 复合韵母 | An,ai,ang,…vn |
| Type A | 含 a的韵母 | A,ia,an,ang,ai,ua,ao |
| Type E | 含e的韵母 | E,ie,ve,ei,uei |
| Type I | 含I的韵母 | I,ai,ei,uei,ia,ian,iang,iao,ie,in,ing,iong,iou |
| Type O | 含o的韵母 | O,ao,uo,ou,ong,iou |
| Type U | 含u的韵母 | U,ua,uen,u,ueng,uo,iou |
| Type V | 含v的韵母 | V,vn,ve |
为了使得决策树的分裂更加细致,我们将每个声韵母作为一个划分特征,这就是单基元划分特征。最后再加上句首尾静音SIL,句中的由逗号和顿号造成的停顿PAU,句中其他的短停顿sp。
上下文相关信息划分特征
| 上下文相关信息划分特征 |
|---|
| 基基元所在音节的前接音节的声调调 |
| 基基元所在的音节为的声调调 |
| 基基元所在音节的后接音节的声调调 |
| 基基元所在的音节在韵律短语中的位置正向 |
| 基基元所在的音节在韵律短语中的位置反向 |
| 基基元所在词的前接词的词性性 |
| 基基元所在词的词性性 |
| 基基元所在词的后接词的词性性 |
| 基基元在其所在词中的位置置 |
| 基基元所在词的音节数字数 |
3.2 决策树问题集的定义
在确定了划分特征后,我们根据划分特征来定义决策树的问题集。对于发音相似性的特征,每个特征都会对应三个问题左问题,中心问题和右问题。其中,对于单基元特征和声母的划分特征,其对应问题的答案是对称的。例如塞音(Stop)对应的三个问题为:
发音相似的特征
$$
QS’L_Stop’ \quad \lbrace b- ^{\star} ,d- ^{\star},g- ^{\star},p- ^{\star},t- ^{\star},k- ^{\star} \rbrace \
QS’R_Stop’\quad \lbrace ^{\star}+b/ ^{\star} ,^{\star}+d/ ^{\star},^{\star}g/^{\star},^{\star}p+/ ^{\star},^{\star}t+/ ^{\star},^{\star}k+/ ^{\star} \rbrace \
QS’C_Stop’\quad \lbrace b- ^{\star} ,d- ^{\star},g- ^{\star},p- ^{\star},t- ^{\star},k- ^{\star} \rbrace
$$
其中单引号中的部分为问题的标识,而大括号内的部分为问题的答案’,$\star$和”’?‘为通配符,如“$b-\star$”则代表所有以“$b-$”开头的上下文相关基元
部分韵母的划分特征
而对于部分韵母的划分特征,其问题的答案是非对称的。如
$$
QS’L_Type_A’\quad \lbrace a?- ^{\star},ia?-^{\star},ua?-^{\star},A-^{\star}\rbrace \
QS’R_Type_A’\quad \lbrace ^{\star}+a?/^{\star},^{\star}+ai?/^{\star},^{\star}+an?/^{\star},^{\star}+ang/^{\star},^{\star}+ao?/^{\star},^{\star}+_A/^{\star}
$$
因为这类问题的意思是左邻的发音是“$a$”,在这类问题中,复合韵母一般是不对称的。
上下文相关信息的划分特征
对于上下文相关信息的划分特征,问题的设计方式为首先对每个单独的划分特征建立各自的问题,然后,对关系密切的划分特征建立联合的问题。如
$$
QS’C_tone1’\quad \lbrace ^{\star}A:?_1_?/B^{\star} \rbrace
$$
代表所有当前音节为一声的基元
$$
QS’C_tone3_3’\quad \lbrace ^{\star}A:?_3_3?/B^{\star} \rbrace
$$
则代表当前音节为三声而后续音节也为三声的基元。这样设计的好处是可以把汉语中一些变调的规则加入问题集中,经过训练,上下文相关的基元中可以包含变调的声音,最终提高合成语音的自然度。
3.3 决策树的构建
问题集建立后,则开始构造决策树。考虑到合成基元的拓扑结构其第一个状态和最后一个状态分别为起始状态和结束状态,他们不能驻留,只在模型中起辅助作用。其余的状态可以驻留或者转移到下一个状态。因此,真正起作用的是中间的几个状态。因此在构造决策树的时候,我们只考虑中间的几个状态。
决策树的的构造有两种方法
- 方法对每个中心基元的每个状态分别构造决策树。这种方法假设当基元的中心音素不同时,基元之间相互独立,因此首先根据中心音素对所有的基元进行分类,然后在利用决策树来进行状态共享。图一给出了中心基元为的所有基元的状态组成的决策树示意图。
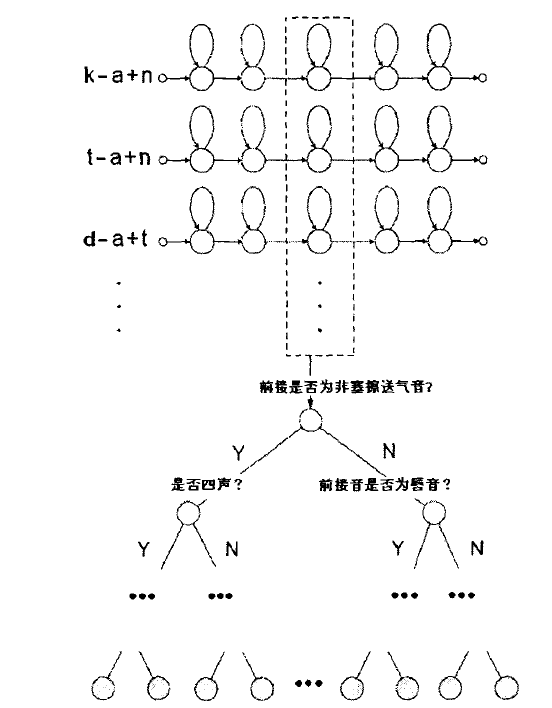
- 方法对所有基元的同一个状态构造决策树。这种方法假设当中心音素不同时,基元之间仍然有一定的重叠。即使基元的中心音素不同,它们之间的状态仍然有可能共享。基元之间的状态共享情况完全依靠基于决策树的分类策略。图一给出了所有基元的状态组成的决策树示意图。

这个树结构的意思是静音是第一个问题,就是对这个树分类影响最大的一个问题,后面的问题依次减弱,然后可能会一直分叉,直到决策树判断截止为止,所以的单元走到那个叶节点就截止了,能走到那个叶节点的单元都共享一个状态了,这个状态用高斯分布描述
于方法1共需要构造基元总数有效状态数棵不同的决策树,这样,只有相同基元的状态才会被共享,这样对保证最后合成语音的单音清晰度有所帮助。而对于方法工,决策树的数量与基元的有效状态数相同,在这里,所有基元的状态进行共享,不同基元中一些发音相似的状态亦被共享到一起,有助于减小最终模型的规模,并且可以在一定程度上提高对训练集中未出现基元的鲁棒性。实验表明,当训练数据较少时句,方法的清晰度明显高于方法工,但在训练数据增加后句,两种方法合成语音的质量十分接近。考虑到方法近似合成未知基元的能力较好,本系统最终选择使用方法2进行决策树的构建。
决策树由自顶而下的顺序生成,首先,将所有的状态放入根节点中,然后进行节点分裂。节点分裂依赖于评估函数。决策树评估函数用来估计决策树的节点上的样本相似性。这里,我们定义对数似然概率作为为节点分裂的评估函数。在每个节点进行分裂的时候,我们从问题集中选择一个问题,然后根据此问题把节点分成两个子节点并且计算评估函数的增量,我们选择具有最大增量的问题,并且根据此问题把节点划分成两部分。当所有问题的增量都低于某个闭值的时候,节点上的分裂过程将停止。最终,同一个叶子节点中的状态将被共享到一起。
四 模型的训练流程
训练部分主要依靠HTK工具包(加入HTS1.1补丁)加入补丁和SPTK3.0工具包完成。
- 从语音文件中提取基音周期参数(使用auto-corelation方法)。
- 使用SPTK工具提取语音文件的MFCC及能量
- 将上述两步中得到的数据组合,计算差分,最终加入HTK文件头,得到格式的训练文件
- 使用上下文无关标注文件和训练文件进行上下文无关基元的HMM训练(使用HTK工具包中的HInit和HRest工具)
- 使用上下文相关标注文件和训练文件进行5次嵌入式训练。使用HeRest工具
- 引入问题集,对频谱HMM和基音周期HMM进行基于决策树的状态共享。使用HHed工具
- 使用上下文相关标注文件和训练文件进行5次嵌入式训练,在最后一次
迭代中,根据HMM的状态转移矩阵得到基元状态时长的HMM。使用HeRest工具 - 引入问题集,对状态时长HMM进行基于决策树的状态共享。使用HHed工具
- 输出二进制的模型文件
五 语音合成流程
- 使用进行分词,标注。
- 音字转换,同时获得声韵母基元的上下文环境信息
- 生成合成模块所需的格式文件
- 解析文字处理模块的文件,将其转换为带有环境信息的上下文相关基元序列
- 根据每个带有环境信息的上下文相关基元搜索并得到其相应的状态时长、基音周期和频谱的HMM。
- 由状态时长HMM得到基元个状态的持续时长。
- 根据状态的时长、基音周期HMM和频谱HMM,进行参数生成,得到每祯的基音周期、对数能量和MFCC参数。
- 将每祯的基音周期、对数能量和MFCC参数送入基于MSLA滤波器的合成器,得到合成语音