一 概览
经典的统计参数语音合成方法的三步
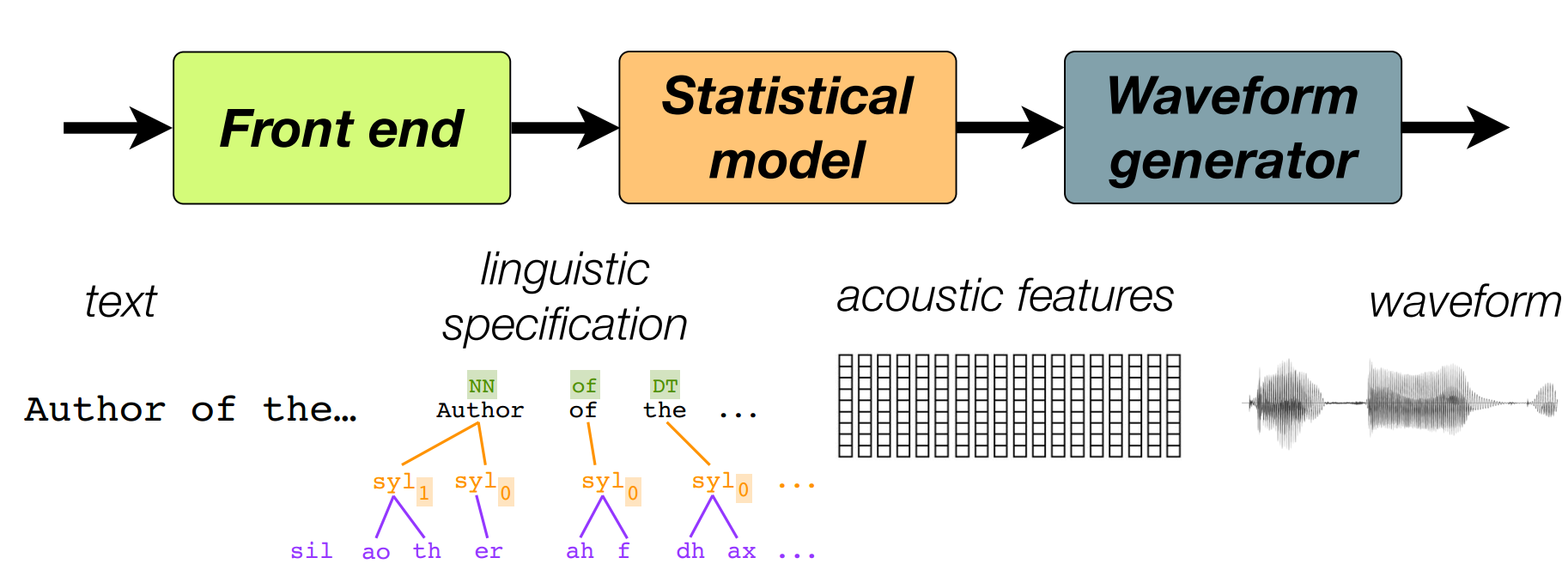
单独看前端和后端
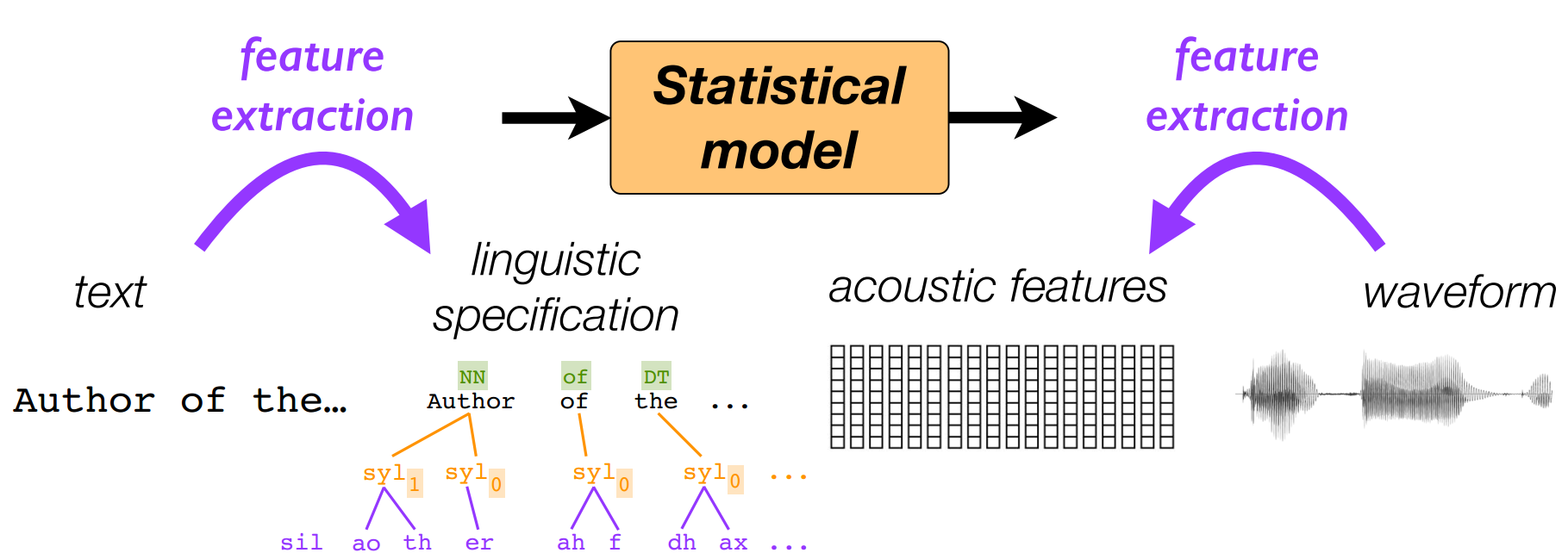
那么统计模型的任务是
可以看到其实统计模型的任务就是做一个sequence-to-sequence的回归
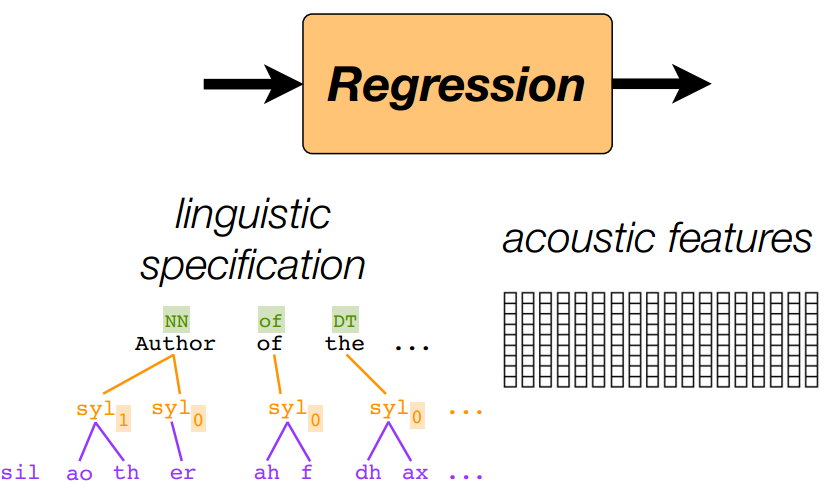
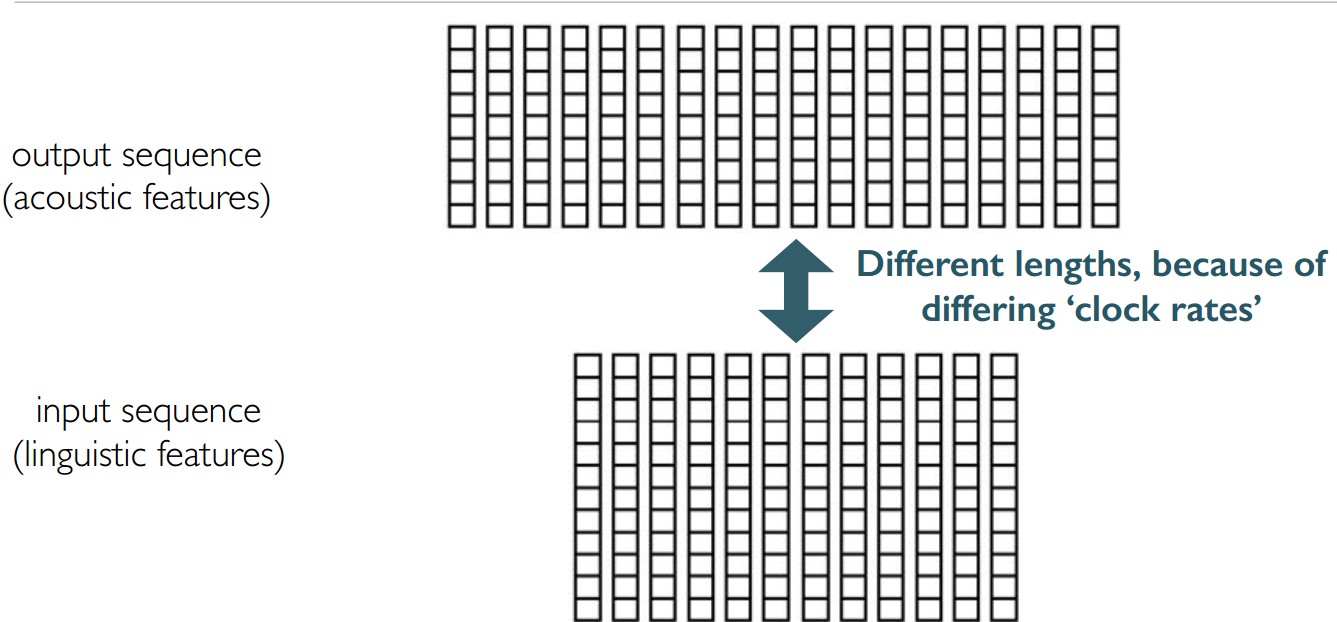
即:输入序列(语义特征)回归到输出序列的声学特征。但是由于二者之间不同的声学始终频率而导致长度不一。
三 TTS的三个方向
- 目前为止
将TTS问题设置为一个sequence-tosequence的回归问题。这是一个有意为之的通用方法,这样易于理解- 用不同的方法来做回归,神经网络或者机器学习方法
- 选取不同的输入输出特征
接下来
TTS是如何完成的,使用一个pre-built系统。可以快速完成整个pipeline,从文本到波形输出进一步
如何构建上面说的pre-built系统。一个缓慢的,一步一步的运行整个pipeline,关注在如何创造一个新系统(对任何语言)
4 术语
- 前端
即text$\rightarrow$linguistic specification - 统计模型回归
linguistic specification$\rightarrow$acoustic features - waveform geneator(波形语音生成)
acoustic features$\rightarrow$waveform
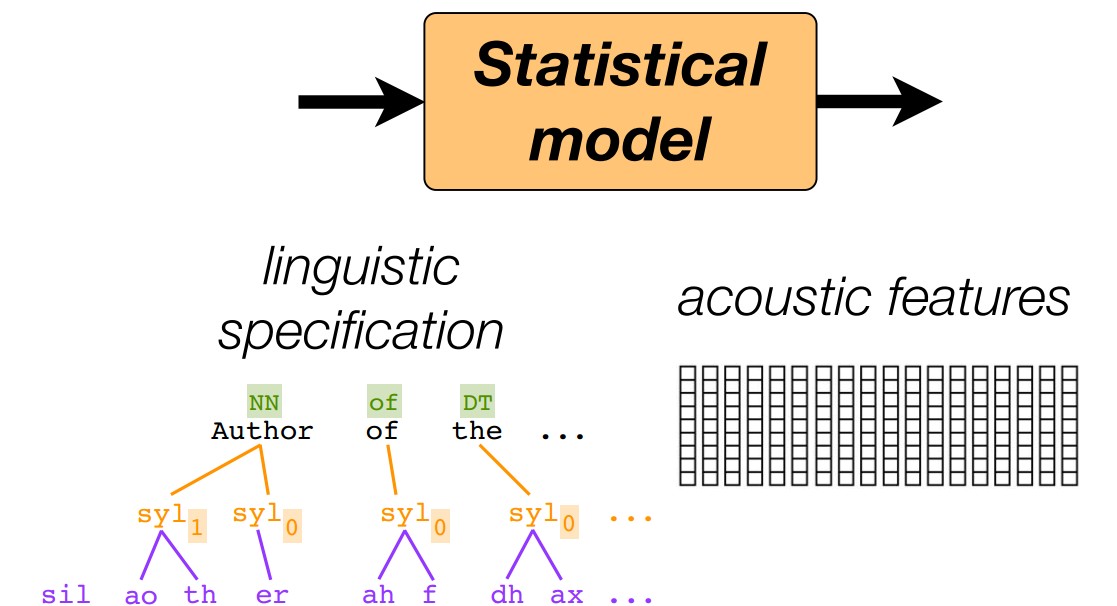
4.语言规范(Linguistic specification)
完整的事物
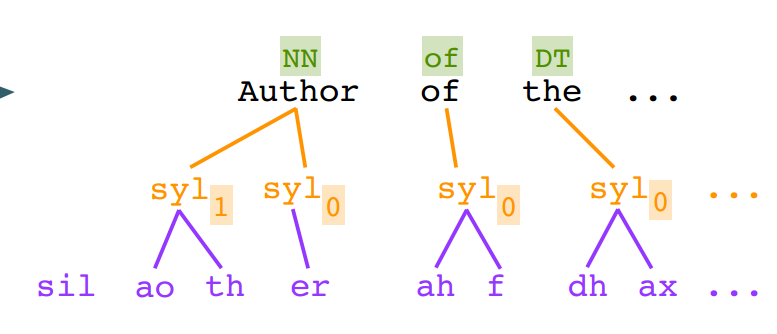
- 语言特征
独立的元素。
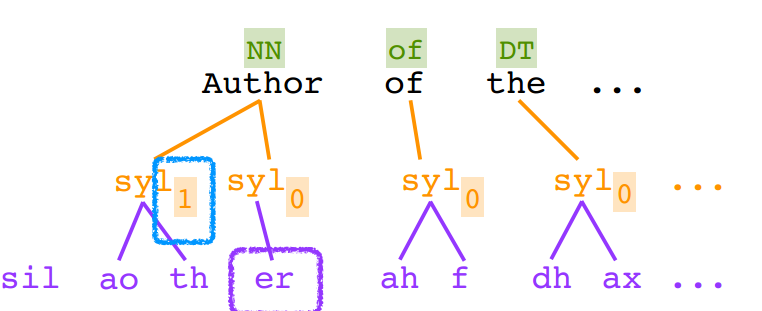
- 声学特征
帧序列
4 从文本到语音
- 文本处理
- pipeline 架构
- 语言规范
- 回归
- 时域模型
- 声学特征
- 波形生成
- 声学特征
- 信号处理
4.1 语言规范
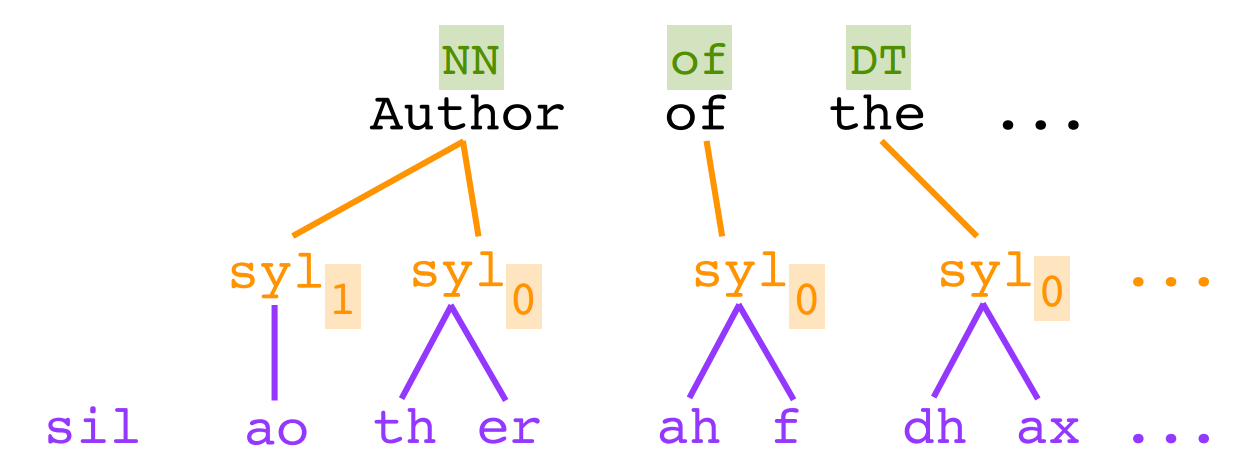
使用前端工具从文本中抽取特征
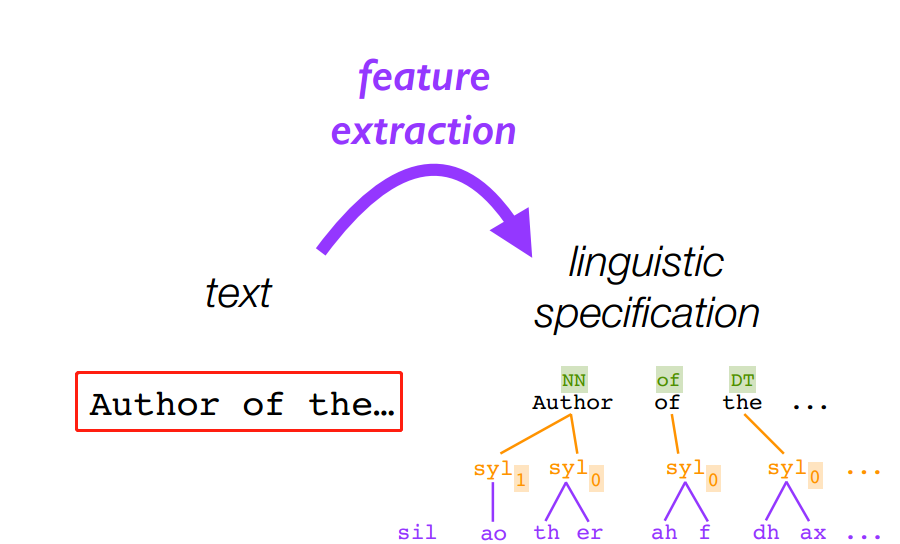
4.2 文本预处理
对应的文本处理pipeline为
而前端之中的文本预处理详细的划分为: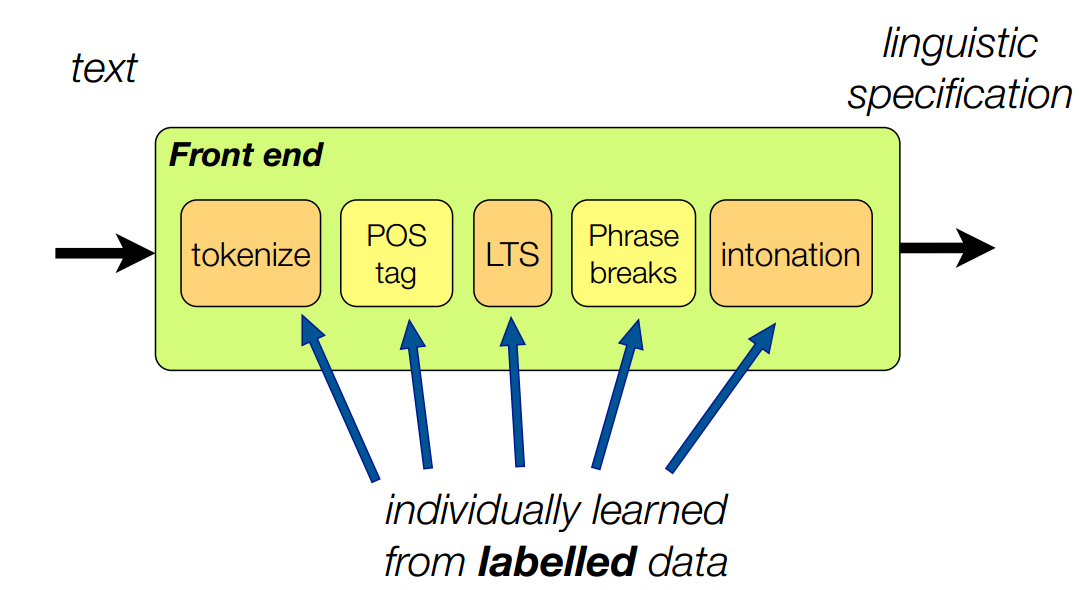
需要注意的是,tokenize,POS tag,LTS,Phrase breaks,intonation等都是从标记数据中独立学习得到的。
4.2.1 Tokenize & Normalize
- 第一步:将输入流划分为token,即潜在的单词
- 对于英语和其他语言
- 基于规则
- 空格和标点都是很好的特征
- 对于许多其他语言,特别是没有使用空格的
- 可能i更困难
- 需要其他技术
- 第二步:对每个token分类,找到非标注词(Non-Standard Words),需要做进一步预处理

3. 第三步: 对每一类非标准词(NSW),使用一些特殊模块来处理。
4.2.2 POS tagging 词性标注
- Part-Of-Speech tagger
- 准确率可能很高
- 在标注过的数据集上训练
- 类别是为文本设计的,而非语音

4.2.3 Pronuncication /LTS
- 发音模型:
- 查找词典,等等
- 单词到声音的模型
- 但是:
- 需要深层次的语言知识来设计发音集合
- 需要人类专家来撰写词典
发音词典示例

4.2.4 语言规范
得到语言规范如下
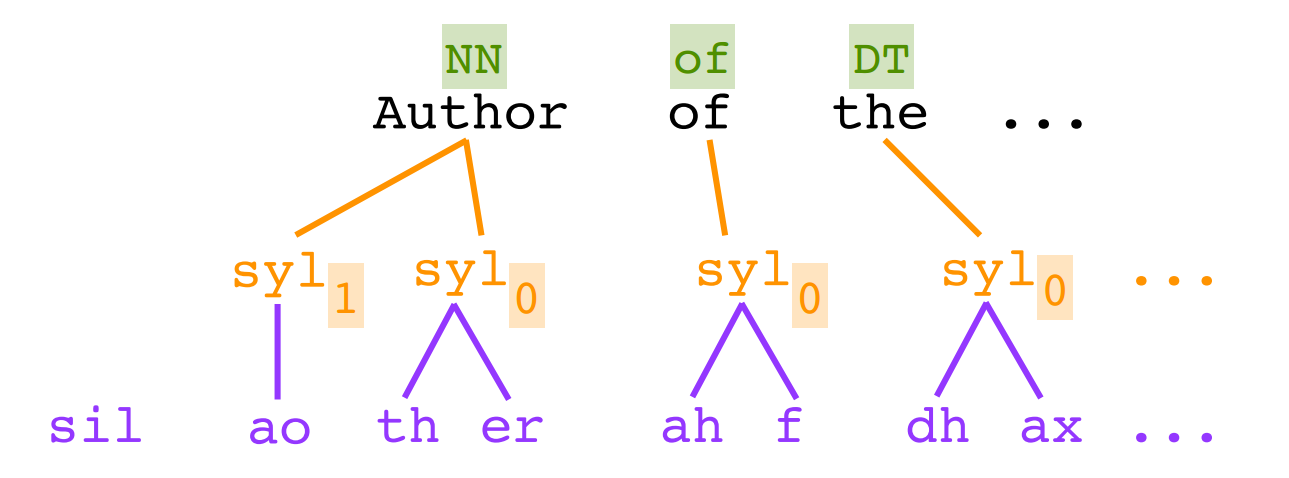
5 语言特征工程
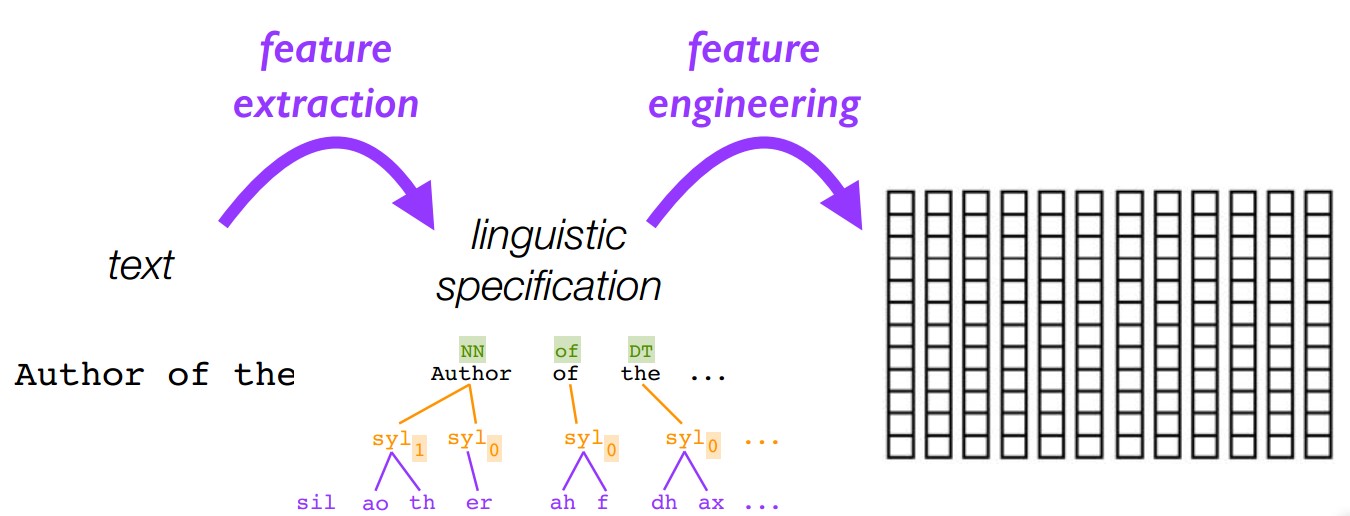
5.1 术语
- Flatten:
语言规范$\rightarrow$上下文依赖的音素序列 - Encode:
上下文依赖的音素序列$\rightarrow$向量序列 - Upsample:
向量序列$\rightarrow$在声学特征framerate帧率上的向量序列
5.2 Flatten & encode:将语言规范转换为向量序列
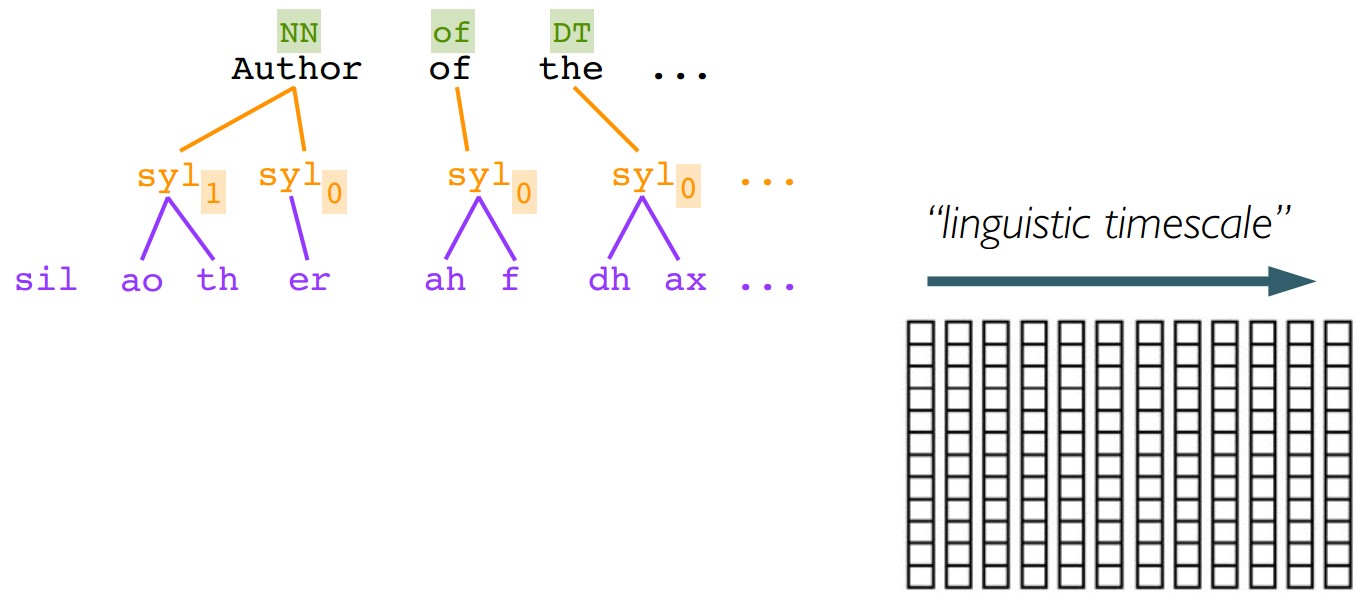
5.3 Upsample:添加时域信息
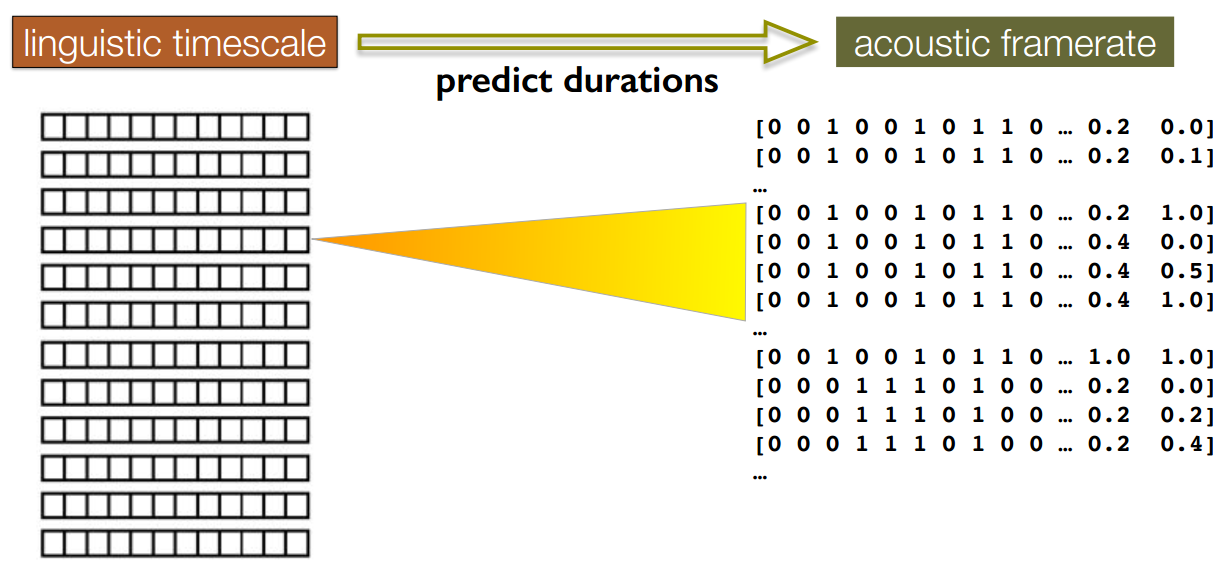
6 统计模型
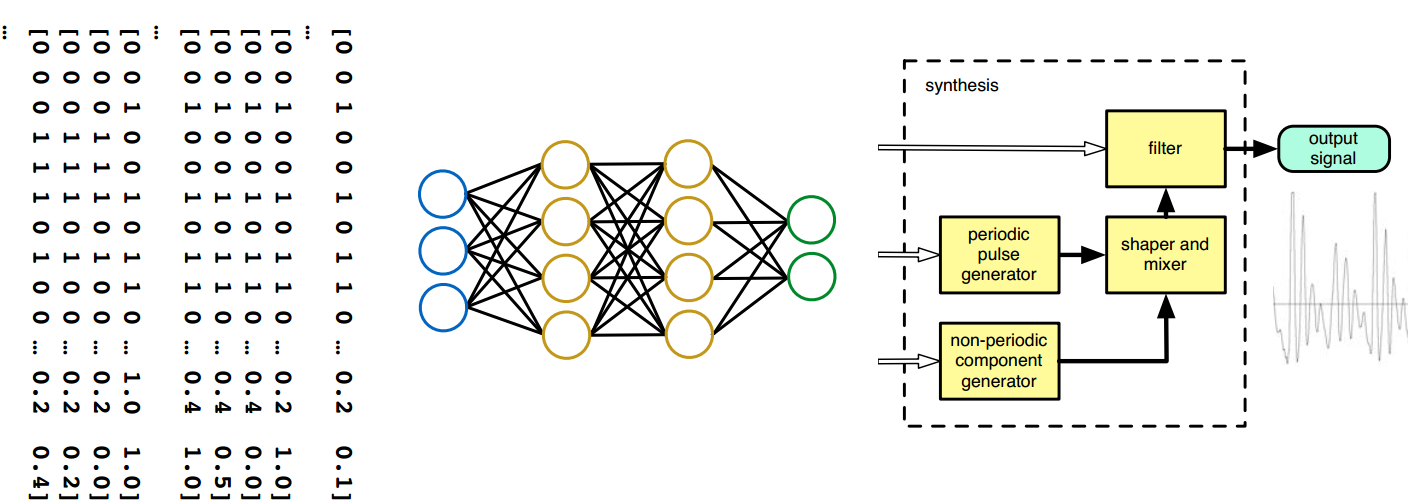
6.1 声学模型:一个简单的前馈神经网络
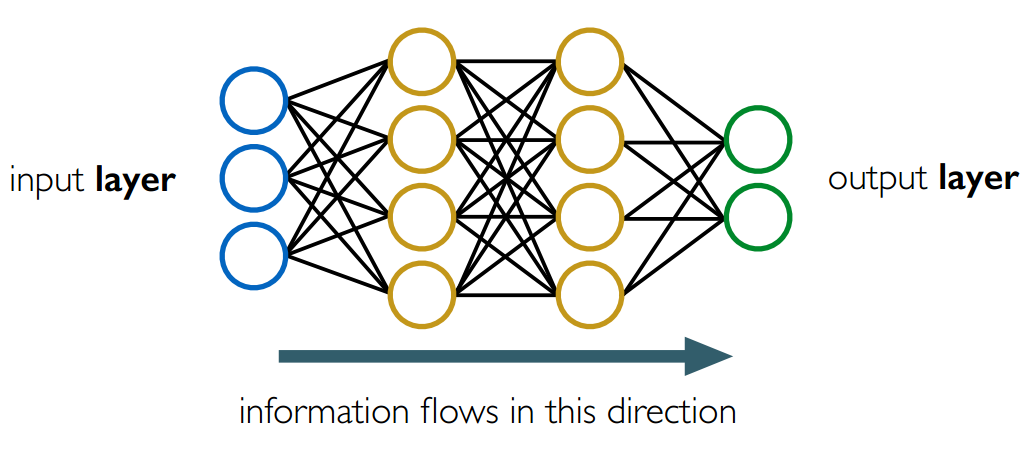
有向权重连接
这些网络层的不同作用:
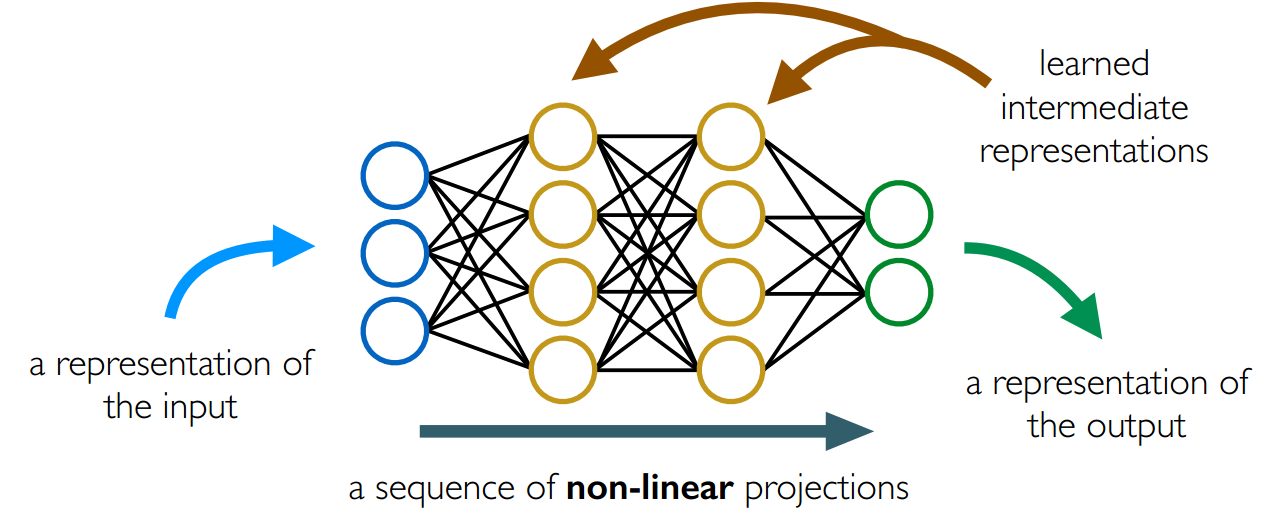
6.2 用神经网络来合成
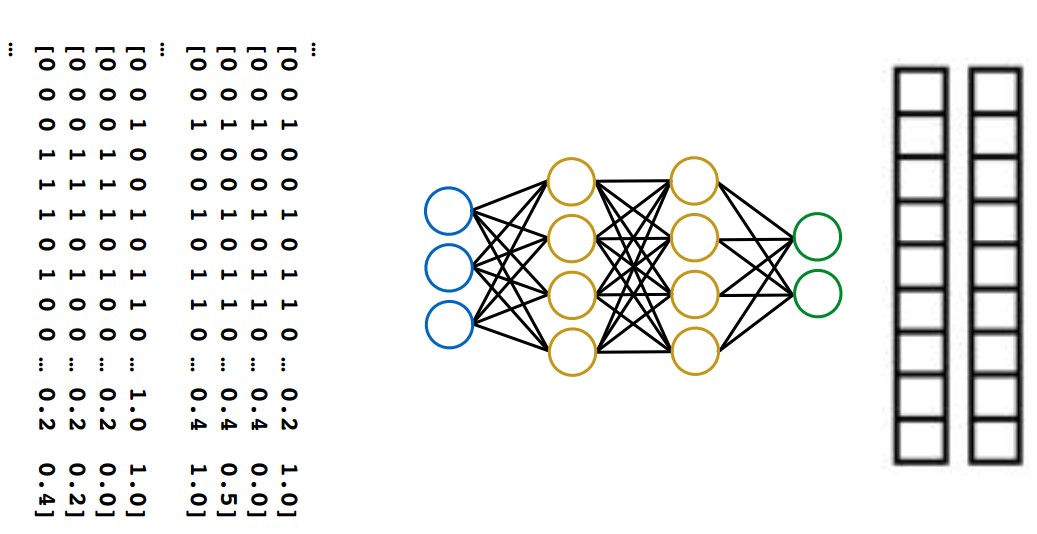
7 波形生成(waveform generator)
7.1 声学特征是什么
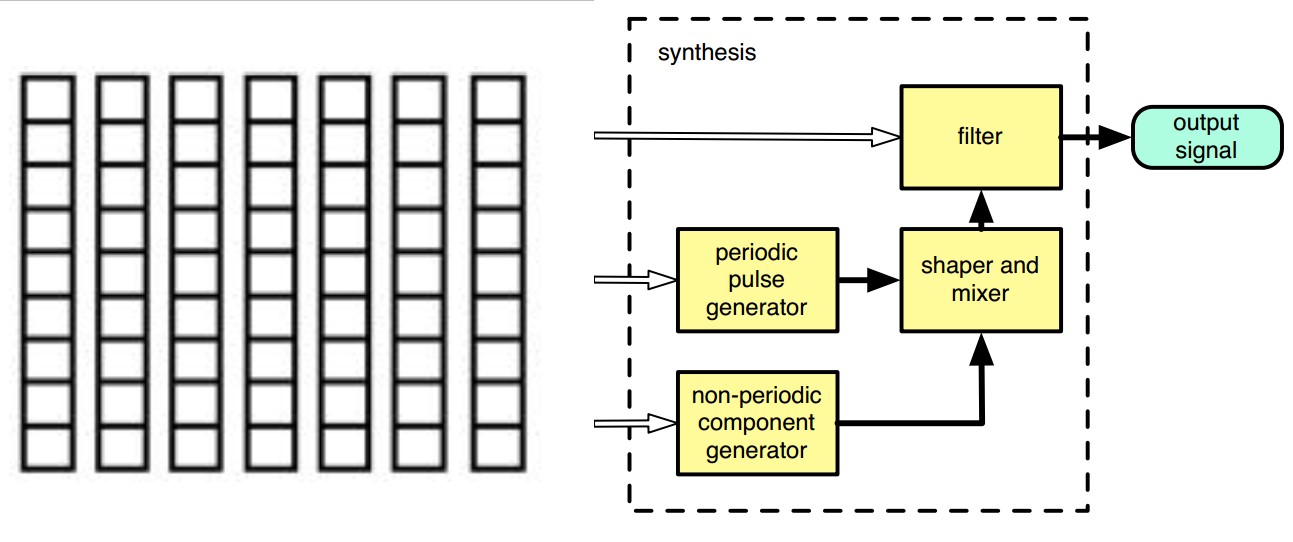
8 使用神经网络的TTS系统
如果我们把所有的这一切综合起来的示意图如下:
第一步: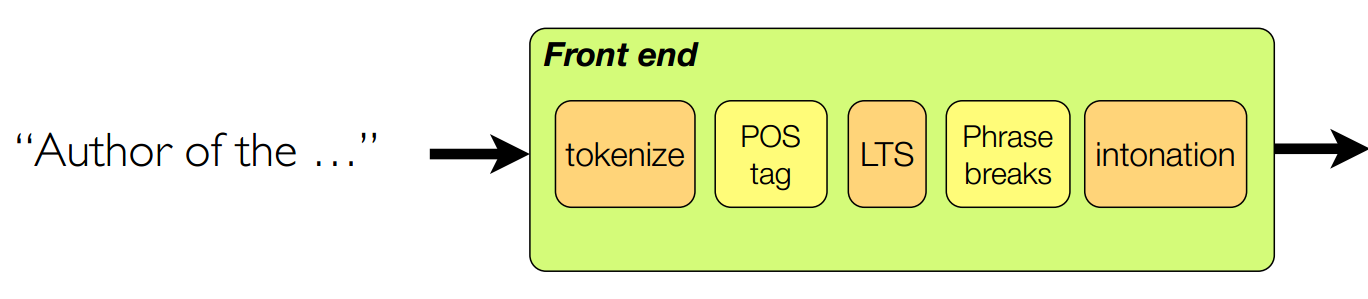
第二步: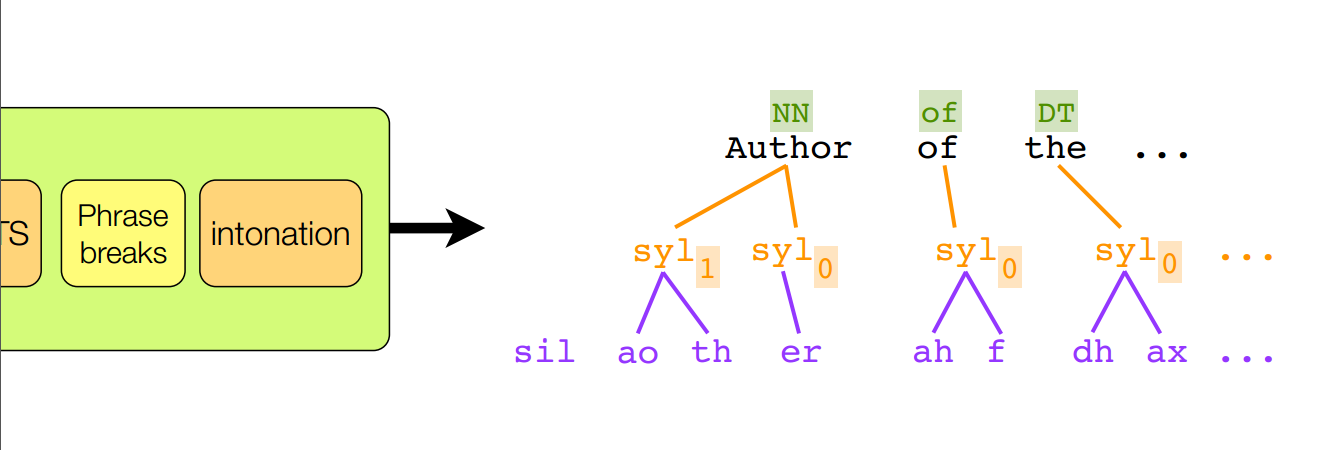
第三步: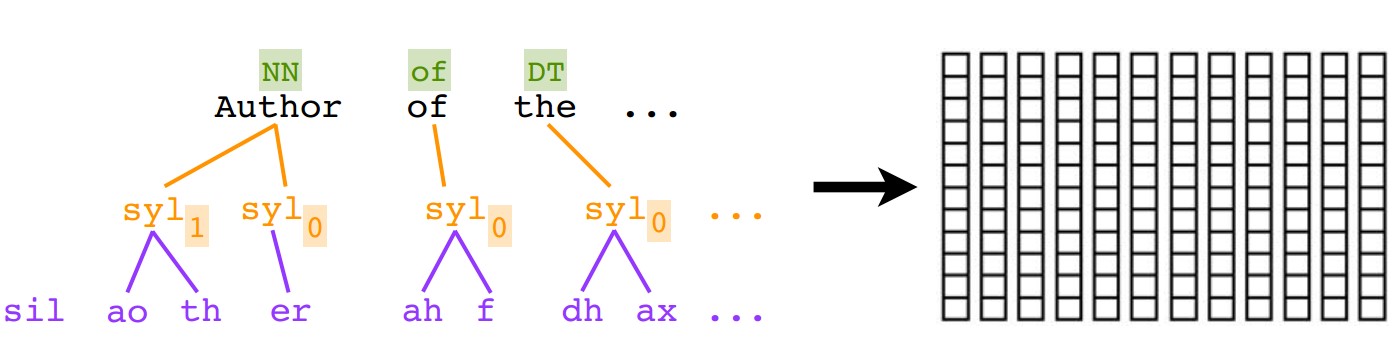
第四步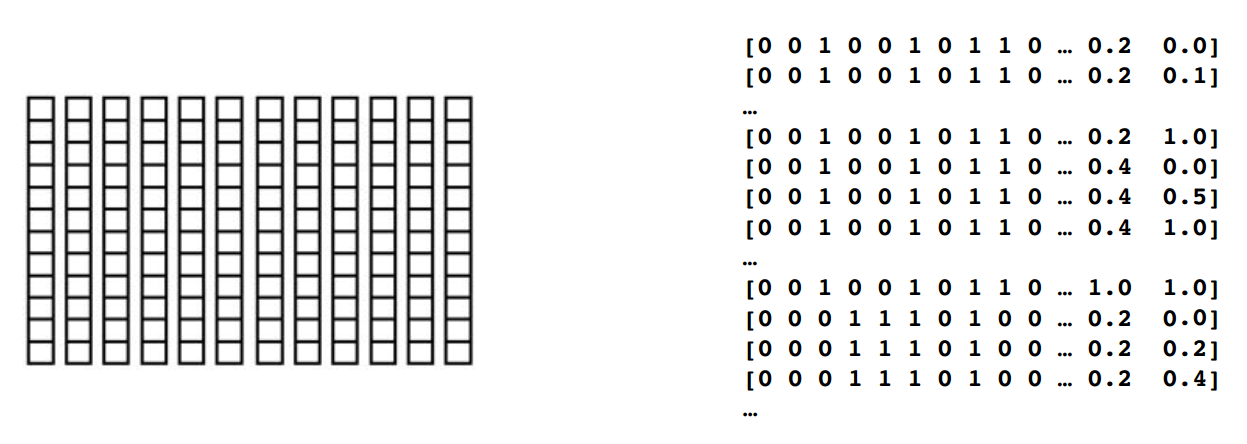
第五步