0 概览
本文详细解释Merlin Mandarin_voice下脚本一步一步所做的事。
01_setup
脚本merlin/egs/mandarin_voice/s1/01_setup.sh
主要工作是创建一个目录,做好准备工作。主要创建了如下文件夹:
- experiments
1 | ─ mandarin_voice(voice name) |
- database
1 | feats |
将一些基本参数写入到conf/global_setting.cfg文件中
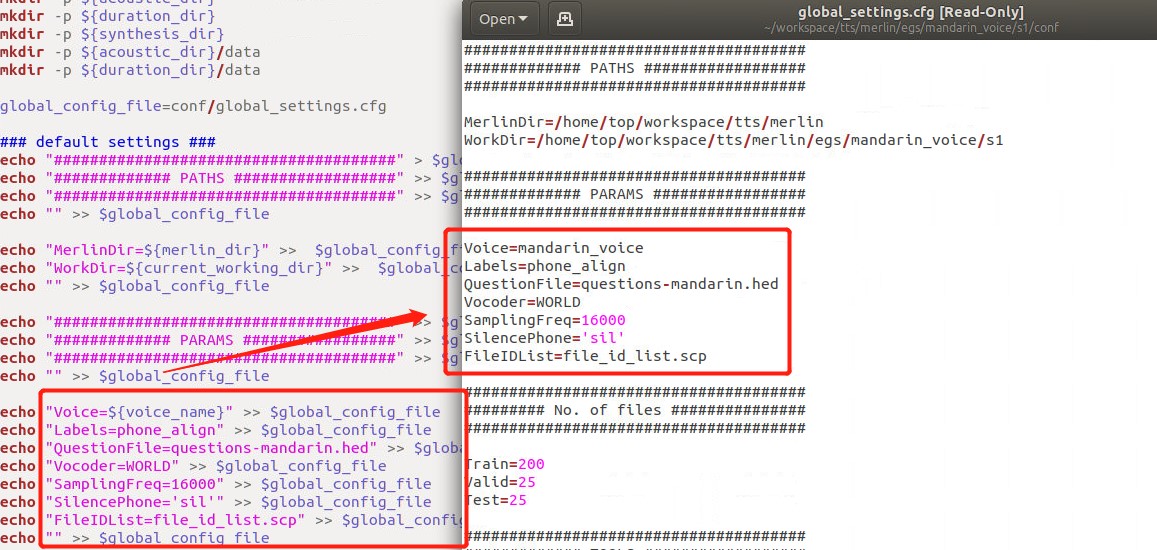
注意:一定要在setup.sh里面定义好train,valid,test的数量,不然修改global_config.cfg里面的值也没用。这三者相加的值要等于(duration_model/FileIdList下)file_id_list.scp总行数
02_prepare_lab
需要两个参数:
- lab_dir: 第一步中的标注目录
database/labels - prompt_lab_dir :第一步中生成的
database/prompt-lab
2.1 准备文件夹
将
database/labels目录下的lab_phone_align下的lab文件分别复制到experiments/mandarin_voice/duration_model/data(时域模型)和experiments/mandarin_voice/acoustic_model/data(声学模型)下。【用于训练】将
database/prompt-lab下的lab文件复制到experiments/mandarin_voice/test_synthesis下【用于测试(合成)】
2.2 生成文件列表
将
database/labels目录下的lab_phone_align下的lab文件列表写入到experiments/mandarin_voice/duration_model/FileIdList'和experiments/mandarin_voice/acoustic_model/FileIdList’。并移除文件后缀【训练集文件列表】将
database/prompt-lab下的lab文件列表写入到experiments/mandarin_voice/test_synthesis/test_id_list.scp文件中,并移除文件后缀【用于合成语音的文本列表】
03_prepare_acoustic_feature
需要两个参数
- wav_dir: 使用的是第一步中的
database/wav,下面存放的是所有的wav音频文件 - feat_dir:输出文件目录
database/feats,是当前脚本输出的特征存放文件目录
3.1 使用声码器抽取声学特征
使用merlin/misc/scripts/vocoder/world/extract_features_for_merlin.py脚本抽取,注意,其中的声码器可以是WORLD也可以是其他的,比如straight,WORLD_2。其实依然是在python中调用以下脚本:
1 | world = os.path.join(merlin_dir, "tools/bin/WORLD") |
生成的特征目录如下:
1 | sp_dir = os.path.join(feat_dir, 'sp' ) |
如果我们使用world作为vocoder的话,会使用misc/scripts/vocoder/world/extract_features_for_merlin.py脚本,生成步骤其实是:
- 直接从原始wav文件,使用
world analysis抽取sp,bapd特征。straightvocoder 会产生ap,如果使用reaper会产生f0特征。 f0$\rightarrow$lf0,bapd$\rightarrow$bap,sp$\rightarrow$mgc
3.2 复制特征到声学特征目录下
将所有feat_dir下的所有文件,包括sp,mgc,ap,bap,f0,lf0复制到experiments/mandarin_voice/acoustic_model/data下。
04_prepare_conf_files
执行./scripts/prepare_config_files.sh
duration相关配置
先从
merlin/misc/recipes/duration_demo.conf复制一份到conf/duration_mandarin_voice.conf,并修改conf/duration_mandarin_voice.conf中的一些目录- MerlinDir
- WorkDir
- TOPLEVEL
- FileIdList
修改Label相关的配置项【Labels】
- silence_pattern:修改为
['*-sil+*'] - label_type:
state_align或phone_align,修改之后为phone_align - label_align: 即配置音素对齐文件的目录
/experiments/mandarin_voice/duration_model/data/label_phone_align - question_file_name:
/misc/questions/questions-mandarin.hed问题集
- silence_pattern:修改为
修改输出配置【Outputs】,label_type有
state_align或phone_align,如果是state_align会在【outputs】处指定dur=5,如果是phone_align则指定dur=1神经网络的架构配置,如果当前声音文件是
demo则修改hidden_layer_size【architechture】修改训练、验证、测试数据数量。【data】
- train_file_number: 200
- valid_file_number: 25
- test_file_number: 25
acoustic相关配置
- 复制文件
conf/acoustic_mandarin_voice.conf,修改变量,label配置都和duration相关配置一样。 - 修改输出配置【outputs】
- mgc
- dmgc
- bap
- dbap
- lf0
- dlf0
- 波形文件设置【waveform】
- framelength
- minimum_phase_order
- fw_alpha
- 其他的【architechture】和【data】都和duration相关配置一样。
执行./scripts/prepare_config_files_for_synthesis.sh配置测试(或合成)语音相关的参数。基本和上面的./scripts/prepare_config_files.sh 一样,需要配置duration和ascoustic参数。新增了【Processes】
1 | DurationModel: True |
05_train_duration_model
实际执行的是./scripts/submit.sh merlin/src/run_merlin.py conf/duration_mandarin_voice.conf
其中./scripts/submit.sh是theano相关参数的配置。
06_train_acoustic_model
训练声学模型,实际执行的是./scripts/submit.sh merlin/src/run_merlin.py conf/acoustic_mandarin_voice.conf
07_run_merlin
需要两个参数
- test_dur_config_file: 语音合成的时域配置文件
- test_synth_config_file:语音合成的