0 数据示例
以 THSCH-30数据集为例子。THSCH-30数据集分为两部分音频和文本。音频文件列表如下:
文本内容,全部文本存放在一个文件内。内容如下:
1 数据预处理
我们先处理文本内容,第一步是数据预处理。主要完成以下操作:
- 去除所有标点符号。
- 去掉所有数字和字母
- 替换所有句子结束的标点符号为
#4,即re.sub('[,.,。]', '#4', txt)。其中的逗号,点号,句号,都替换为符号#4,此处的#4代表了不同的韵律标注层次。具体的不同层次,参考下面的说明
- #0: stands for word segment
- #1 : stands for prosodic word
- #2: stands for stressful word (actually in this project we regrad it as #1)
- #3: stands for prosodic phrase
- #4: stands for intonational phrase
以 下面这句为示例
1 | 'A11_0 绿是阳春烟景大块文章的底色四月的林峦更是绿得鲜活秀媚诗意盎然' |
经过第一步的处理,其中A11_0是句子编号,不会被处理。以空格分割之后会处理后面的中文文本,经过处理,后面的文本没有变化。没有数字和字母,也没有标点符号。
2 添加拼音
第二步是给每个中文添加拼音标注。使用的是pypinyin。示例代码如下:
1 | numstr, txt = line.split(' ') |
这样,上面的一句中文对应的拼音内容为:
1 | lv4 shi4 yang2 chun1 yan1 jing3 da4 kuai4 wen2 zhang1 de5 di3 se4 si4 yue4 de5 lin2 luan2 geng4 shi4 lv4 de2 xian1 huo2 xiu4 mei4 shi1 yi4 ang4 ran2 |
可以看到,每个字都有对应的拼音。其中,有一步处理是给没有音调的字统一添加为音调5。有些词比如的是没有音调的,统一被添加音调5。这一步会将拼音内容写入一个标注文本A11_0.lab
3 强制对齐
这一步使用了语音识别模型,对语音进行强制对齐。语音识别模型的作用是识别语音中每个字的发音起止时间,并存储为TextGrid格式,这个格式是语音标注软件Praat的标注格式。
此步骤依赖以下内容:
3.1 拼音词典
此步骤依赖的拼音词典是 mandarin_mtts.lexicon,其中的内容如下:
1 | a1 a1 |
3.2 强制对齐工具
MTTS所使用的强制对齐工具为 Montreal-Forced-Aligner
3.3 强制对齐模型
预备知识
汉字按照长度可以划分为:句子,短语,汉字(音节),音素。而音素由声母,韵母,元音,静音组成。
对齐模型使用的是由THSCH-30数据集所训练的中文语音识别模型,下载地址为 THSCH-30语音识别模型
3.4 输出结果
这一步主要是对语音音频文件处理,并得到识别结果。识别的结果是直接到音素,存储为TextGrid格式,示例文本对应的音频文件 A11_0.wav所得到的TextGrid标注文件内容如下:
1 | File type = "ooTextFile" |
可以看到,一共识别到了64个字。其中解析如下:
- **xmin **:当前字的开始时间,单位为秒
- xmax:当前字的结束时间,单位为秒
- text:当前字的拼音和音调。
4 TextGrid标注格式转换为SFS格式
SFS即为声韵母标注,主要将每个字的音素标注为以下三类:
| 类型 | 说明 | 示例 |
|---|---|---|
| s | 时长超过100ms的静音 | sil,sp |
| d | 时长短于100ms的静音 | - |
| a | 辅音 | 包含```b’, ‘p’, ‘m’, ‘f’, ‘d’, ‘t’, ‘n’, ‘l’, ‘g’, ‘k’, ‘h’, ‘j’, ‘q’, ‘x’, ‘zh’, ‘ch’, ‘sh’, ‘r’, ‘z’, ‘c’, ‘s’, ‘y’, ‘w’ |
| b | 元音 | - |
同时将发音起止时间的单位从秒更改为 纳秒,即乘以10的6次方。上一步得到的TextGrid格式的标注转换为sfs格式之后,内容如下:
1 | 11000000 s |
5 sfs到真实标注文件
此步骤依赖于sfs标注文件和原始中文文本。上面的步骤示例中的A11_0文本和sfs标注即可。得到的标注结果如下:
1 | 0 11000000 xx^xx-sil+l=v4@xx@/A:xx-xx^xx@/B:xx+xx@xx^xx^xx+xx#xx-xx-/C:xx_xx^xx#xx+xx+xx&/D:xx=xx!xx@xx-xx&/E:xx|xx-xx@xx#xx&xx!xx-xx#/F:xx^xx=xx_xx-xx! |
5.1 中文分词,词性标注,韵律标注
如果原中文内容里没有进行韵律标注,韵律标注以**#分割。就会默认所有的分词结果里的每个词都是#0**,但是最后一个是#4,即最后一个代表当前语句结束。参照第数据预处理部分的韵律不同值代表的不同意义。
第一步是对输入的原始中文进行分词,还是以上面步骤的示例文本为例,使用jieba分词的posseg分词和词性标注得到的结果如下:
- 分词结果:
1 | ['绿', '是', '阳春', '烟景', '大块文章', '的', '底色', '四月', '的', '林峦', '更是', '绿', '得', '鲜活', '秀媚', '诗意', '盎然'] |
词性标注结果:
1
['a', 'v', 'n', 'n', 'n', 'u', 'n', 'm', 'u', 'n', 'd', 'a', 'u', 'a', 'a', 'n', 'z']
韵律标注结果:
1
['#0', '#0', '#0', '#0', '#0', '#0', '#0', '#0', '#0', '#0', '#0', '#0', '#0', '#0', '#0', '#0', '#4'] (当前没有预标注韵律,默认所有分词都是#0,且最后一个为#4)
音节分解结果:
1 | [('l', 'v4'), ('sh', 'ih4'), ('y', 'iang2'), ('ch', 'un1'), ('y', 'ian1'), ('j', 'ing3'), ('d', 'a4'), ('k', 'uai4'), ('w', 'uen2'), ('zh', 'ang1'), ('d', 'e5'), ('d', 'i3'), ('s', 'e4'), ('s', 'ic4'), ('y', 've4'), ('d', 'e5'), ('l', 'in2'), ('l', 'uan2'), ('g', 'eng4'), ('sh', 'ih4'), ('l', 'v4'), ('d', 'e2'), ('x', 'ian1'), ('h', 'uo2'), ('x', 'iu4'), ('m', 'ei4'), ('sh', 'ih1'), ('y', 'i4'), ('ang4',), ('r', 'an2')] |
5.2 获取音素类型和时间
分为两种情况,有sfs标注文件的和没有的。
使用sfs标注文件
sfs标注文件中每一行都是如下内容:
1 | 11000000 s |
每一行以空格分割,分别代表了当前第i个音素的开始时间和音素类型。音素类型参考第4节的表。分别读取并保存
1 | 音素类型列表:phs_type = ['s', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 's', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'b', 'a', 'b', 's'] |
音素起止时间列表(63)比音素类型列表(62)多一个,开始时间0。
没有sfs标注文件
如果没有sfs标注的时间,程序可以自动生成,方法是计算得到语句的所有因素长度,并将默认起止时间都设置为0.,音素类型都默认设置为a。
参考韵律列表。韵律列表其实就是当前语句被分词之后,每个词的停顿间隙。以**#0,#1,#2,#3,#4**标识,分别代表了不同层次的韵律。当前示例语句被分词为如下

原始语句如下,没有带任何标点符号:
1 | 绿是阳春烟景大块文章的底色四月的林峦更是绿得鲜活秀媚诗意盎然 |
分词结果如下:
1 | 语句分词结果: ['绿', '是', '阳春', '烟景', '大块文章', '的', '底色', '四月', '的', '林峦', '更是', '绿', '得', '鲜活', '秀媚', '诗意', '盎然'] |
对应的韵律列表如下:
1 | ['#0', '#0', '#0', '#0', '#0', '#0', '#0', '#0', '#0', '#0', '#0', '#0', '#0', '#0', '#0', '#0', '#4'] |
比如对分词结果 阳春得到的音素为列表
1 | [('y', 'iang2'), ('ch', 'un1')] |
长度为4,向音素类型列表中添加对应长度的默认值a。
1 | phs_type = ['a', 'a', 'a', 'a', 'a', 'a', 'a', 'a'] (后面四个是当前词`阳春`的音素对应的音素类型) |
最后得到的音素起止时间列表和音素类型列表分别为:
1 | time= [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] |
可以看到,与有sfs对比,长度一致。都是对应音素数目的长度,只不过没有sfs文件的都是默认值。
6 音素状态决策树
上面已经得到了音素对应的起止时间和音素类型,下一步是构建音素状态决策树。以英文为示意图,如下:
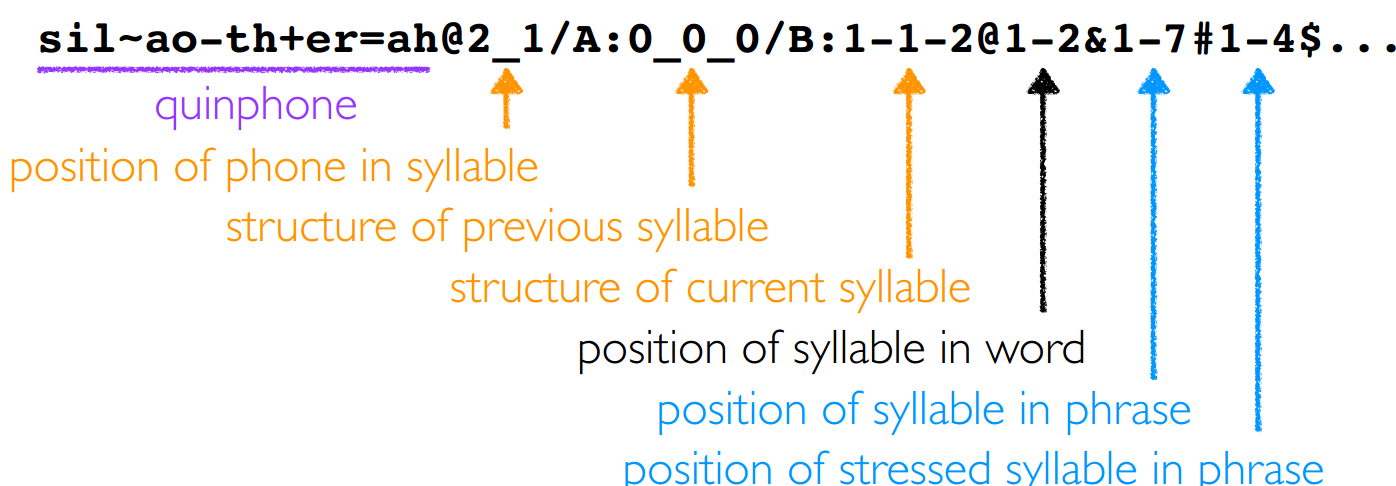
- 首先,一整句话是有前后承接关系的,当绿是阳春这几个词出现时,
绿字是是前缀,阳字是是字的后缀。这只是字面上的上下文关系,当前需要构建音素级别的上下文承接关系。所以需要进一步细化。
2.韵律标注层次有 ,由小到大(以MTTS前端为例,其他标注格式不一定,标贝数据只有,#1,#2,#3,#4)。
- 音素: phn
- 音节:syllables
- 词: #0
- 短语: #1
- 句子: #3
- 句子结束: #4
6.1 MTTS的上下文标注
说明
- 没有设计语调短语层和段落层
- 也没有设置重音标注
- @&#$!^-+=以及/A:/B:…的使用主要是为了正则表达式匹配方便,10个符号(@&#$!^-+=)共有100个匹配组合,即可以匹配100个属性
- 如果前后位置的基元不存在的话,用xx代替,例如 xx^sil-w+o=sh
标注文件会标记不同韵律层次所有的上下文信息,详细可以参考下面的两张表:
不同层级和对应的标注格式
| 层级 | 标注格式 |
|---|---|
| 声韵母层 | p1^p2-p3+p4=p5@p6@ |
| 声调层 | /A:a1-a2^a3@ |
| 字/音节层 | /B:b1+b2@b3^b4^b5+b6#b7-b8- |
| 词层 | /C:c1_c2^c3#c4+c5+c6& |
| 韵律词层 | /D:d1=d2!d3@d4-d5& |
| 韵律短语层 | /E:e1 |
| 语句层 | /F:f1^f2=f3_f4-f5! |
更加细致的划分(基元代表了不同层次的单元,可以是音素,也可以是音节,声调等)
| 标号 | 含义 |
|---|---|
| p1 | 前前基元 |
| p2 | 前一基元 |
| p3 | 当前基元 |
| p4 | 后一基元 |
| p5 | 后后基元 |
| p6 | 当前音节的元音 |
| —- | —- |
| a1 | 前一音节/字的声调 |
| a2 | 当前音节/字的声调 |
| a3 | 后一音节/字的声调 |
| —- | —- |
| b1 | 当前音节/字到语句开始字的距离 |
| b2 | 当前音节/字到语句结束字的距离 |
| b3 | 当前音节/字在词中的位置(正序) |
| b4 | 当前音节/字在词中的位置(倒序) |
| b5 | 当前音节/字在韵律词中的位置(正序) |
| b6 | 当前音节/字在韵律词中的位置(倒序) |
| b7 | 当前音节/字在韵律短语中的位置(正序) |
| b8 | 当前音节/字在韵律短语中的位置(倒序) |
| —- | —- |
| c1 | 前一个词的词性 |
| c2 | 当前词的词性 |
| c3 | 后一个词的词性 |
| c4 | 前一个词的音节数目 |
| c5 | 当前词中的音节数目 |
| c6 | 后一个词的音节数目 |
| —- | —- |
| d1 | 前一个韵律词的音节数目 |
| d2 | 当前韵律词的音节数目 |
| d3 | 后一个韵律词的音节数目 |
| d4 | 当前韵律词在韵律短语的位置(正序) |
| d5 | 当前韵律词在韵律短语的位置(倒序) |
| —- | —- |
| e1 | 前一韵律短语的音节数目 |
| e2 | 当前韵律短语的音节数目 |
| e3 | 后一韵律短语的音节数目 |
| e4 | 前一韵律短语的韵律词个数 |
| e5 | 当前韵律短语的韵律词个数 |
| e6 | 后一韵律短语的韵律词个数 |
| e7 | 当前韵律短语在语句中的位置(正序) |
| e8 | 当前韵律短语在语句中的位置(倒序) |
| —- | —- |
| f1 | 语句的语调类型 |
| f2 | 语句的音节数目 |
| f3 | 语句的词数目 |
| f4 | 语句的韵律词数目 |
| f5 | 语句的韵律短语数目 |
以英文单词 author为例
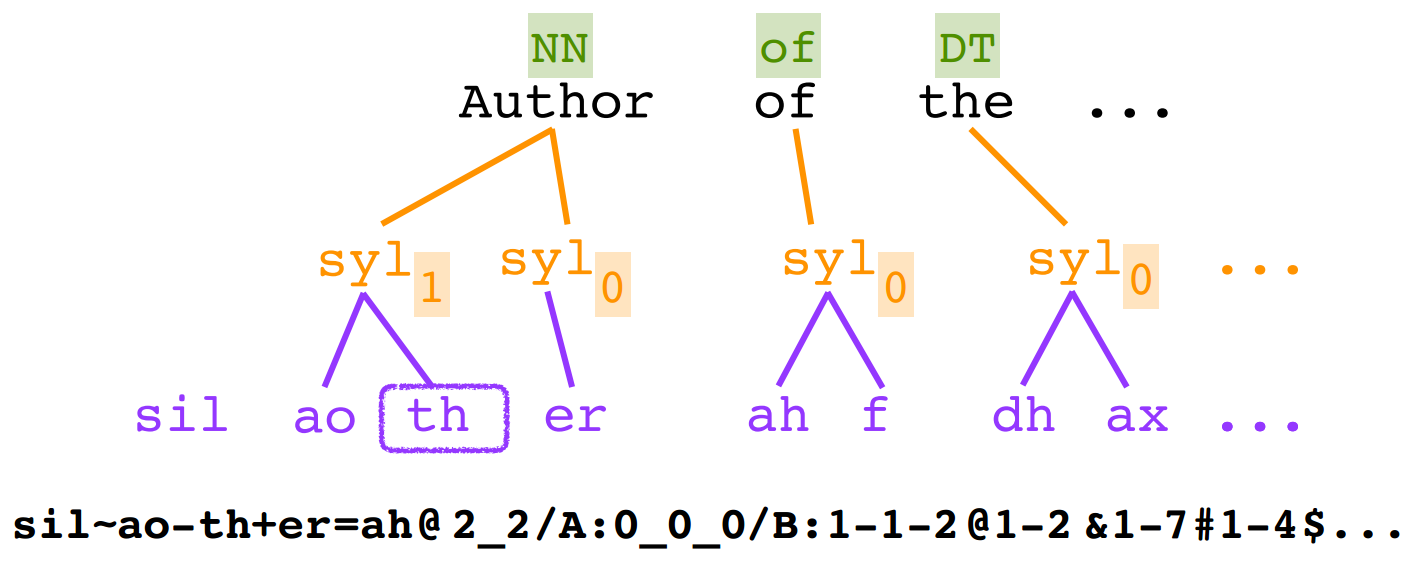
体现在代码里面的标准公式化字符串如下:
1 | formation=[ |
示例中文的标注结果如下:
1 | 0 11000000 xx^xx-sil+l=v4@xx@/A:xx-xx^xx@/B:xx+xx@xx^xx^xx+xx#xx-xx-/C:xx_xx^xx#xx+xx+xx&/D:xx=xx!xx@xx-xx&/E:xx|xx-xx@xx#xx&xx!xx-xx#/F:xx^xx=xx_xx-xx! |
以第一行和第二行为例:
1 | 0 11000000 xx^xx-sil+l=v4@xx@/A:xx-xx^xx@/B:xx+xx@xx^xx^xx+xx#xx-xx-/C:xx_xx^xx#xx+xx+xx&/D:xx=xx!xx@xx-xx&/E:xx|xx-xx@xx#xx&xx!xx-xx#/F:xx^xx=xx_xx-xx! |
注意:第一行其实是静音。因为任何一句话的开头都是静音,所以第一行的所有标注基元都是xx,代表了不存在的基元。
第二行才是字绿的开始,首先绿字被拆分为音素l和v4
11000000和12400000代表了该字的开始和结束时间。
xx^sil-l+v4=sh@v,是声母韵母层级的标注,(上表中的p)依次是:
前前基元(不存在,以xx代表)连接符:^前一基元:sil(一句话的开始都是sil)连接符:-当前基元:l连接符:**+*后一基元: v4连接符:=后后基元:sh)连接符:@当前音节的元音:v
@/A:xx-4^4,是声调层级标注(上标中的a): 依次是
字调标注的开始:@/A前一音节的字调: xx (不存在的xx)连接符:-当前音节的字调:4((绿)4)连接符:^后一个音节的字调:4((是)4)