概览图
0 说明
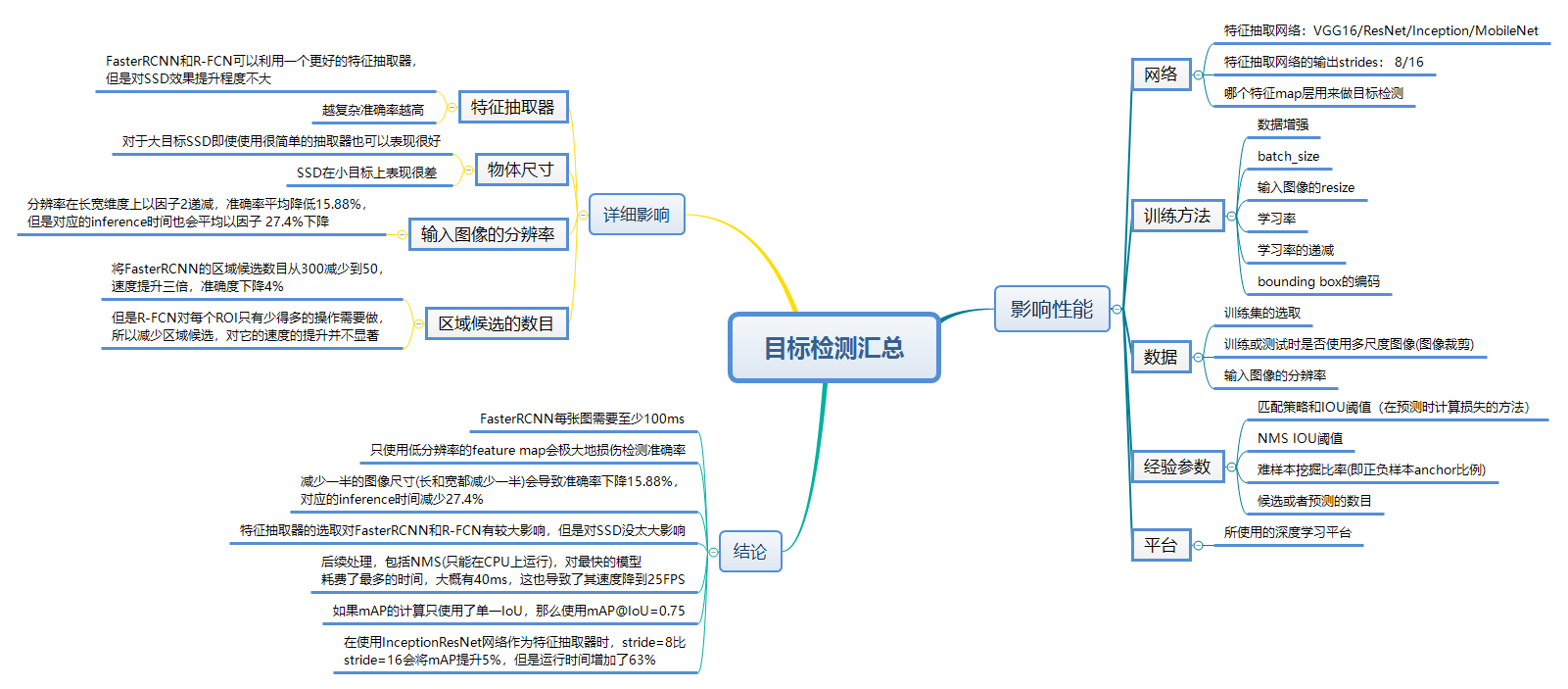
关于目标检测的好坏,很难有一个统一明确的比较。我们一般都是在速度和准确率之间妥协,除此之外,我们还需要注意,以下因素会影响性能
- 特征抽取网络(
VGG16,ResNet,Inception,MobileNet) - 特征抽取网络的输出strides
- 输入图像的分辨率
- 匹配策略和IOU阈值(在预测时计算损失的方法)
- NMS IOU阈值
- 难样本挖掘比率(即正负样本anchor比例)
- 候选或者预测的数目
- bounding box的编码
- 数据增强
- 训练集
- 训练或测试时是否使用多尺度图像(图像裁剪)
- 哪个特征map层用来做目标检测
- 定位损失函数
- 所使用的深度学习平台
- 训练配置包括batch_size,输入图像的resize,学习率,以及学习率的递减
1性能评测结果
1.1 FasterRCNN
在PASCAL VOC 2012测试集上的表现
| 方法 | 生成的区域候选数目 | 测试数据 | mAP(%) |
|---|---|---|---|
| SelectiveSearch | 2000 | voc2012 | 65.7 |
| SelectiveSearch | 2000 | voc2007+voc2012 | 68.4 |
| RPN+VGG,shared | 300 | voc2012 | 67.0 |
| RPN+VGG,shared | 300 | voc2007+voc2012 | 70.4 |
| RPN+VGG,shared | 300 | voc2007+voc2012+coco | 75.9 |
coco数据集

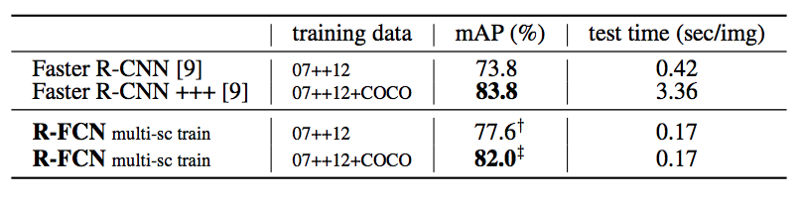
1.2 R-FCN
voc数据集
| 方法 | 训练集 | mAP(%) | 测试时间(sec/image) |
|---|---|---|---|
| FasterRCNN | voc 2007+voc2012 | 73.8 | 0.42 |
| FasterRCNN++ | voc 2007+voc2012+coco | 83.8 | 3.36 |
| F-FCN多尺度训练 | voc2007+voc2012 | 77.6 | 0.17 |
| F-FCN多尺度训练 | voc2007+voc2012+coco | 82.0 | 0.17 |
coco数据集
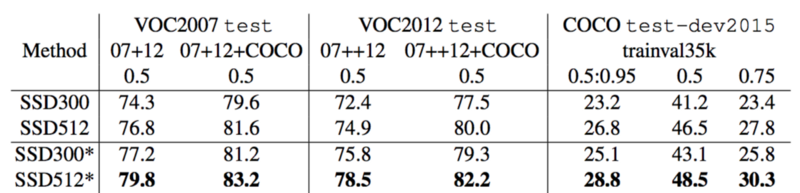
1.3 SSD
voc数据集
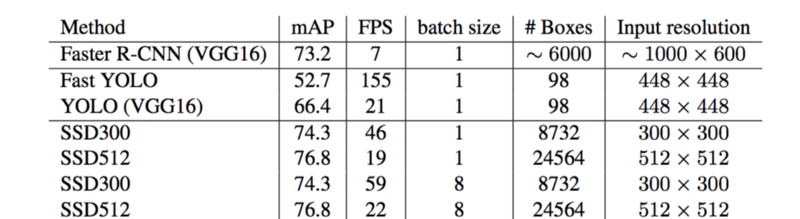
性能
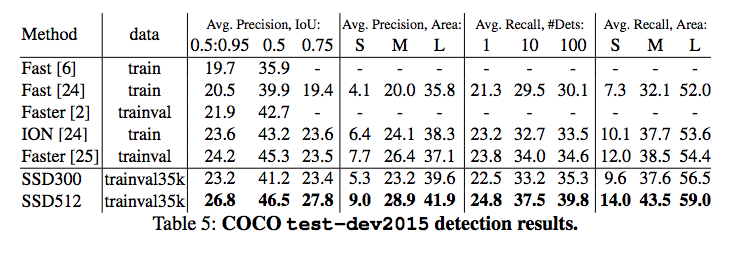
coco数据集
1.4 YOLO
voc2007
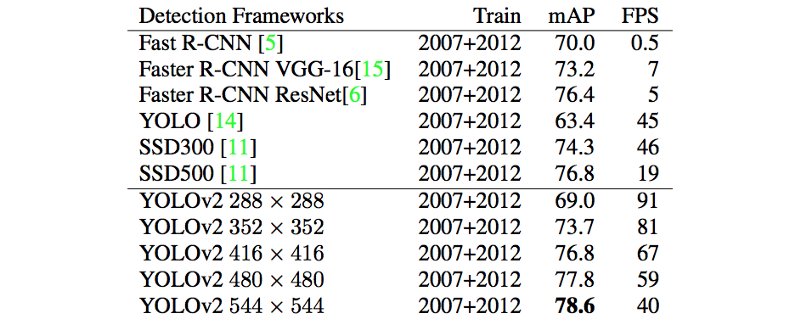
coco数据集
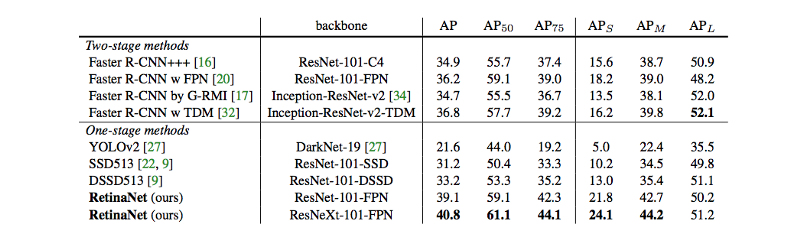
1.5 yolov3
coco数据集
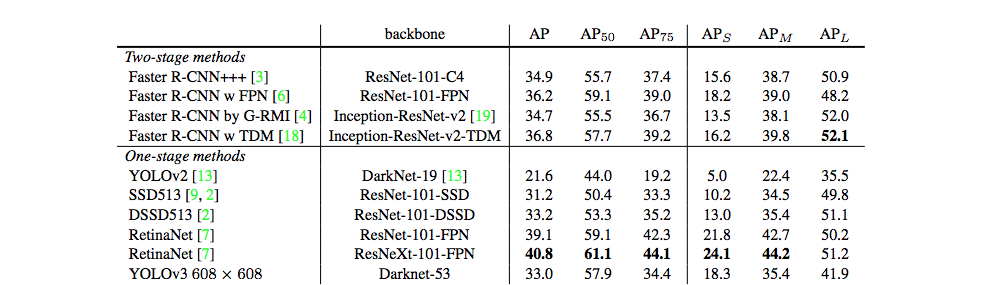
性能
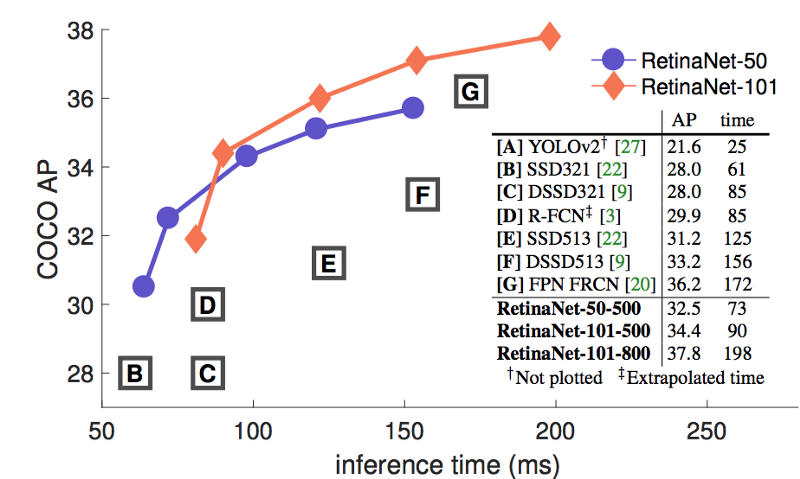
1.6 FPN
coco数据集

1.7 RetinaNet
coco数据集
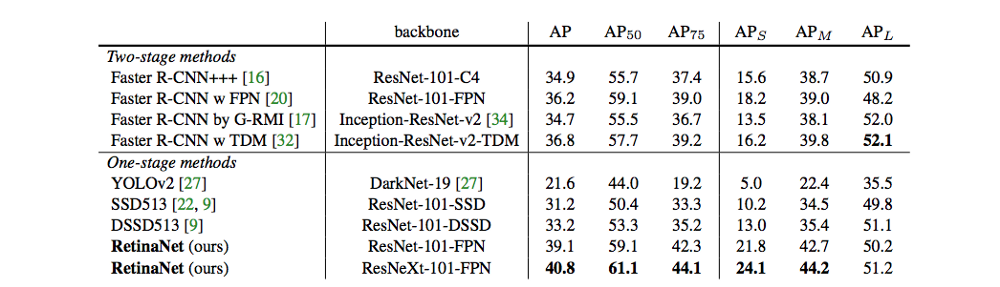
性能
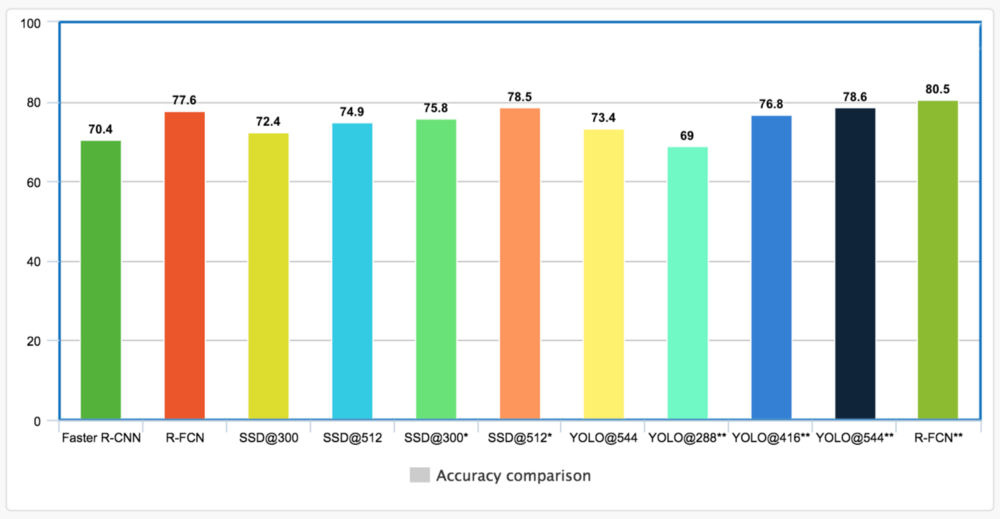
2 论文结果比较
下图是用VOC2007+voc2012的数据集训练的,mAP的计算方式是VOC2012。
- 对于SSD,输入图像尺寸有300x300和512x512
- 对于yolo,输入图像尺寸有288x288,416x416,544x544
更高的分辨率可以得到更好的准确率,但是速度会相应下降。
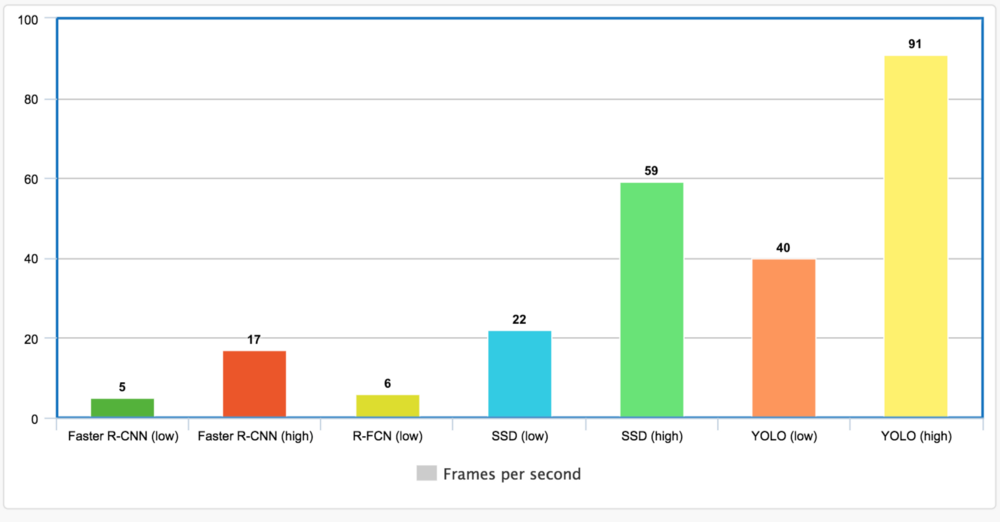
输入图像的分辨率和特征抽取对速度有极大影响。下面是最高和最低的FPS,当然下图可能在使用不同mAP时结果有较大出入
coco数据集的表现
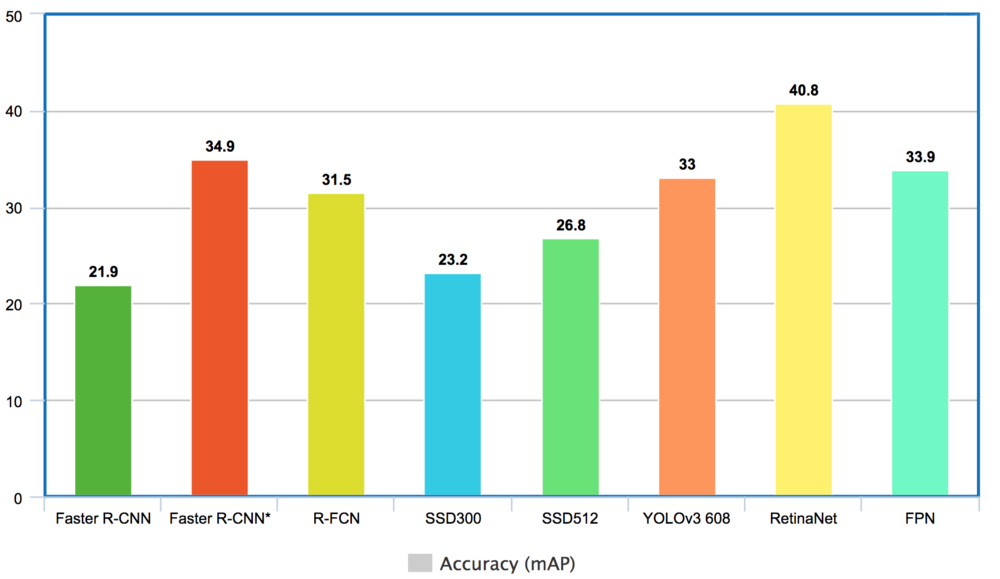
可以看到,FPN和FasterRCNN有很高的准确率,但是RetinaNet最高。取得最高准确率的RetinaNet是借助了
- 金字塔特征
- 特征抽取器的复杂
- Focal Loss
3 google的研究结果
3.1 特征抽取器
研究了特征抽取器对准确率的影响,其中FasterRCNN和R-FCN可以利用一个更好的特征抽取器,但是对SSD效果提升程度不大。
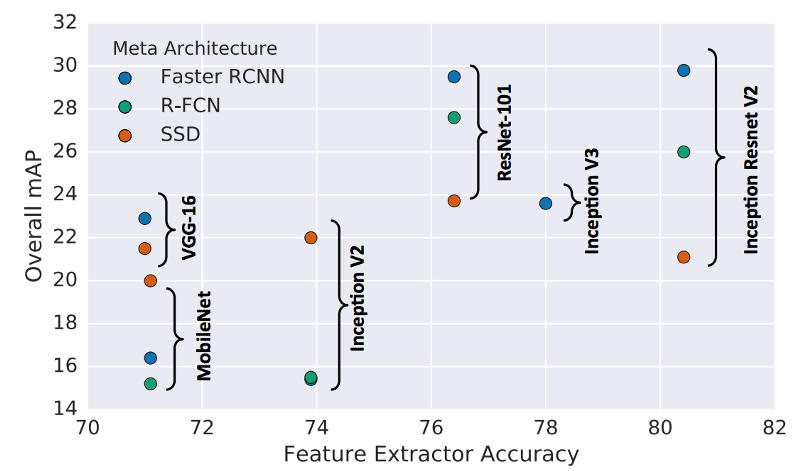
上图中x轴 是每个特征抽取器在分类上的top1的准确率。
3.2 物体尺寸
对于大目标SSD即使使用很简单的抽取器也可以表现很好,如果使用更好的抽取其,SSD甚至可以达到其他分类器的准确率。但是SSD在小目标上表现很差
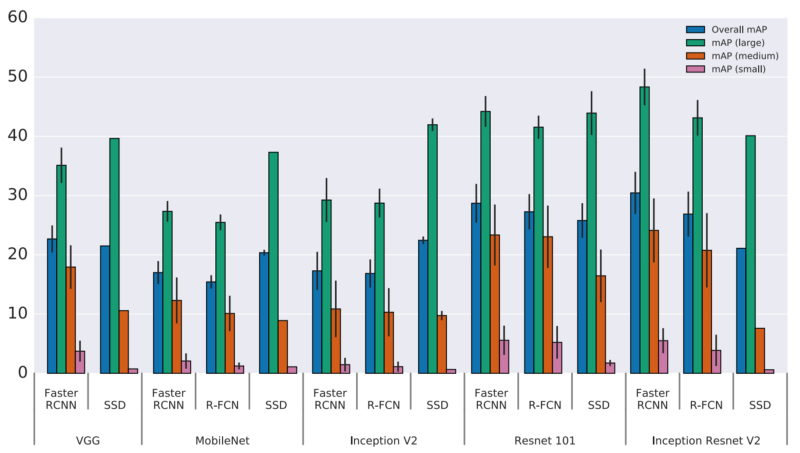
3.3 输入图像的分辨率
更高的分辨率有利于提升小目标的检测准确率,对大目标也有帮助。对分辨率在长宽维度上以因子2递减,准确率平均降低15.88%,但是对应的inference时间也会平均以因子 27.4%下降。
3.4 区域候选的数目
区域候选的数目可以极大地影响FasterRCNN(FRCNN),而对准确率不会有太大降低。例如,Inception ResNet,FasterRCNN可以提升三倍速度,如果使用50个区域候选而不是300个的话,对应的准确率只降低了4%。但是R-FCN对每个ROI只有少得多的操作需要做,所以减少区域候选,对它的速度的提升并不显著。
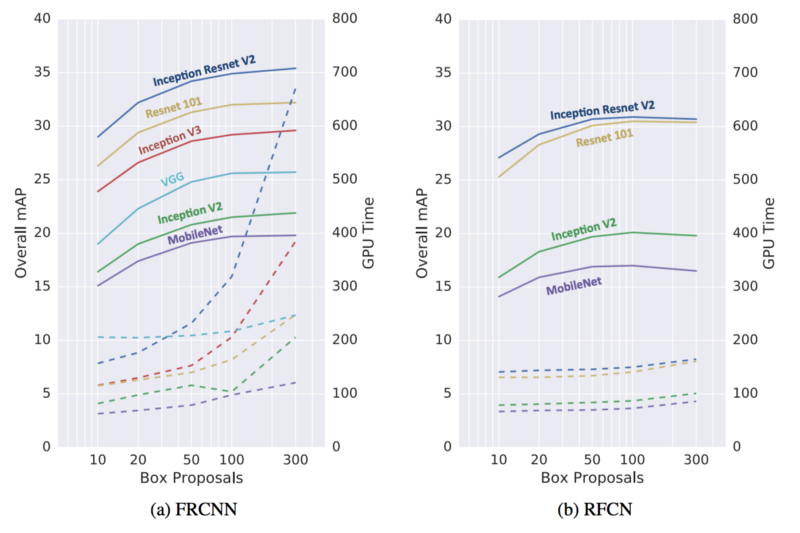
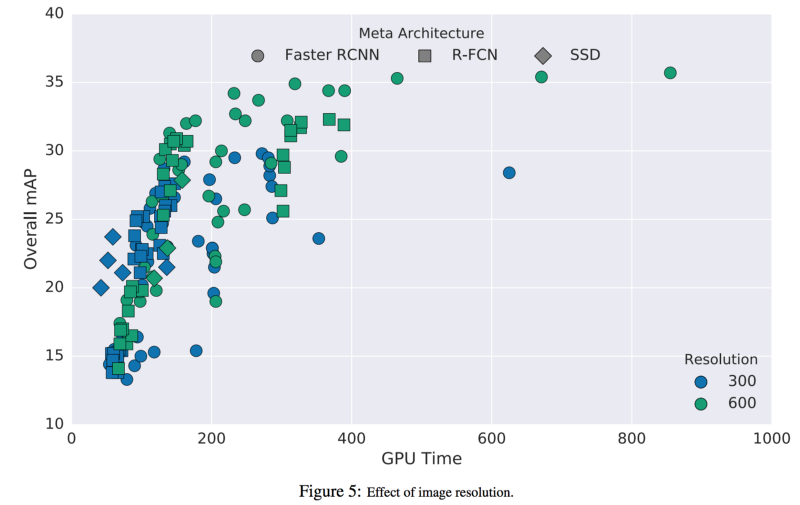
3.5 GPU时间
下面是不同模型使用不同特征抽取器的GPU时间
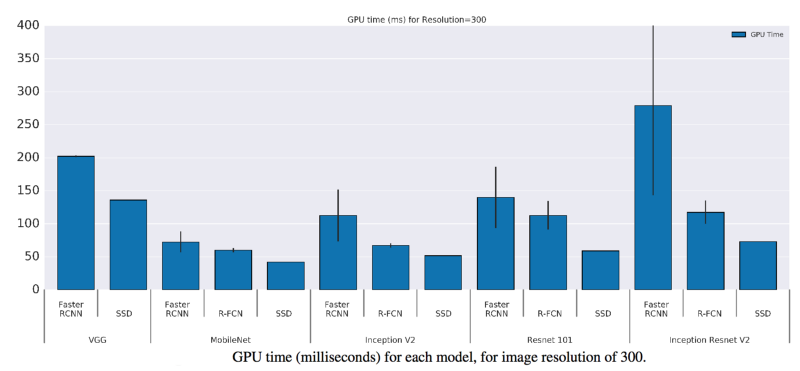
大部分论文使用FLOPS(浮点运算)来衡量模型复杂度,但是这个没法反映准确的速度。模型密度(稀疏和稠密模型)影响的是所耗费的时间。讽刺的是,欠稠密模型通常平均需要更长的时间来完成一个浮点运算。
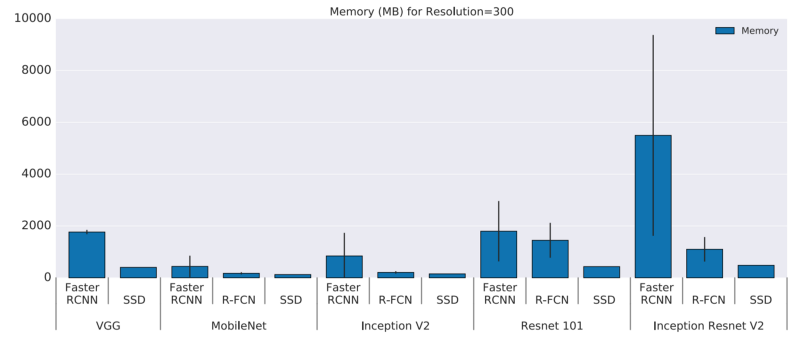
3.6 内存
MobileNet有最少的参数,它需要不到1GB的内存。
4 结论
- R-FCN和SSD模型平均速度更快,但是如果不考虑速度,它们准确率不如FasterRCNN
- FasterRCNN每张图需要至少100ms
- 只使用低分辨率的feature map会极大地损伤检测准确率
- 输入分辨率极大的影响准确率。减少一半的图像尺寸(长和宽都减少一半)会导致准确率下降15.88%,对应的inference时间减少27.4%
- 特征抽取器的选取对FasterRCNN和R-FCN有较大影响,但是对SSD没太大影响。
- 后续处理,包括NMS(只能在CPU上运行),对最快的模型耗费了最多的时间,大概有40ms,这也导致了其速度降到25FPS
- 如果mAP的计算只使用了单一IoU,那么使用mAP@IoU=0.75
- 在使用InceptionResNet网络作为特征抽取器时,stride=8比stride=16会将mAP提升5%,但是运行时间增加了63%。
最准确的模型
- 最准确的单一模型,使用FasterRCNN,使用InceptionResNet,和300个候选。一张图片的检测需要1秒钟。
- 最准确的模型是一个多次裁剪inference的模型集合。它使用平均准确率向量来选取5个最不同的模型
最快的模型
- 使用mobilenet的SSD是在最快速度和最佳准确率之间一个最好的均衡
- SSD表现卓越,但是对小目标较差
- 对于大目标,SSD可以达到与FasterRCNN和R-FCN一样的准确率,但是用的是更小更轻的特征抽取器。
速度与准确率之间的均衡
- FasterRCNN如果只使用50个区域候选的话,它可以达到与R-FCN和SSD一样的速度,准确率为32mAP