1 引入
目前大多数从语义分割mask生成照片的方法要么是使用从粗糙到精细的级联网络,要么是设计特定的损失函数来增加模型稳定性。目前,使用语义分割mask为指引合成包含丰富局部特征高分辨率的图像依然有难度。
本文就提出了一种关联提供的语义分割mask,同时保留了丰富的局部细节的合成图像方法。
图像翻译模型如Pix2Pix使用Unet风格的生成器直接映射图像的抽象表征,但是没有合理的机制来随机特征的实现。这通常会导致模型的输出是特征空间不同分辨率之间的模棱两可的特征,如下图。通常这会导致模糊的图像和糟糕的纹理细节。解决方案之一是Pix2PixHD论文中,使用了一个粗糙到精细的方法,以及风格损失函数来修正图像的输出质量。但是这个方法需要很大的模型,但仍然没解决特征映射的基础问题。一个更加合理的解决方案是Tub-GAN,使用了latent向量z(选中的分布的噪音)和一个语义分割的mask作为条件输入,允许模型学习其联合分布。虽然他们提出了一个融合策略:投影latent特征以及投影mask特征并不能保证是天然关联的,因而此模型也是受限的仅仅能生成背景空间的低频信息。

图说明:生成的样本图像和卡通示例了:训练期间一个mask引导的面部生成会遇到的采样空间映射的挑战:图像翻译模型会被训练着映射相同的圆形模式到各种各样的球形模式上。模可能学习到了训练数据集的平均的篮球模式而不能完整的独立地映射它们。相同的问题存在于训练一个生成器使用相似的mask表征来复制完全不同的脸。
本文提出了当前可用的以mask为指引像素级语义输入的生成模型的两种主要问题
- 合成的结果中的精细的纹理细节缺乏多样性,源于mask到图像域的不充分的映射。
- 当前的多条件输入架构设计中的低参数效率
对于第一个问题,我们认为带语义分割map输入的多个latent向量会取得更好的样本空间映射,这也会使得合成结果里纹理细节的多样性。对于第二个问题,我们的解决方案是在初始的特征投影之前将mask embeding反射回latent向量输入中,此操作显著提升了合成结果中的纹理细节。将mask embeding 向量和latent向量结合起来是一个有效的方法来添加mask限制,因为它允许初始的特征投影可匹敌于像素级别mask限制。与Tube-GAN相反,我们使用的是投影的mask特征作为latent特征的主要限制,使得网络的上采样路径能够保留其大部分能力来实现精细的局部纹理特征。
2 相关工作
2.1 (Conditional)条件GAN
条件GAN可以通过联合latent向量和条件输入来控制生成器的输出。许多研究使用了cGAN,使用的是向量形式(比如标签)的图像属性来控制图像合成。Pix2Pix和Pix2PixHD首次提出在编码器-解码器风格的图像到图像翻译的结构中使用语义分割为输入。有些研究应用输入embeding来转换高维属性,如将语义分割mask转换成压缩的低维形式。CCGAN提出使用包含图像特色的句子embeding作为特征来进行cycle-GAN训练。他们的研究表明,凝练的文本信息可以被用来与生成器latent特征融合作为条件来做图像合成。Disentangling Multiple Conditional Inputs in GANs使用binary(二值)mask embeding作为条件输入的部分来控制生成的服饰的形状。但是这个论文表明,mask embedding向量不足以完成像素级以mask为指引的受限图像合成。它们的结构中输出的形状并不总是与输入的mask一致的。
2.2 State-of-art的Pix2Pix的风格生成器
Pix2Pix在图像翻译时,无法生成稳定多样的精细纹理特征。Pix2Pix-HD模型提出从粗糙到精细的级联结构,加上风格损失和多尺度的判别器。主要思想是使用额外的损失项来正则惩罚膨胀的模型能力,尤其是拼接的精修网络(refinedment networks)。尽管此模型有通过样例级别的特征embedding来随机纹理的机制,局部纹理细节的多样性依然取决于实例标签映射的镜像扰动。某种程度上来说,此机制允许随机纹理生成,但是纹理映射仅与物体的形状扰动相关。换句话说,此图像翻译模型仍然受限于一对一的映射(如上图),由于这种原因,图像质量和多样性依然相当低。
2.3 ProGAN(Progressive Growing )
ProGAN是一种训练方法:它渐进式地给生成器和判别器增加卷积层来获得更好的稳定性和更快的收敛。此技术使得使用轻量级的修改的DCGAN来合成高清图像成为可能。
3 生成器中的Mask Embedding
为了控制生成器的输出的形状,mask经常被用来作为编码器-解码器形式网络的中生成器的仅有输入来增强像素级限制。此类图像翻译模型的主要定律是构建一种翻译$G(v)\rightarrow \lbrace r \rbrace$,其中一对一的翻译由输入$v$限定的。使用诸如dropout或者噪音z覆盖作为输入$v$的机制,一对多的关联$G(v,z)\rightarrow \lbrace r_1,r_2,…r_m \rbrace$ 原理上就称为可能。然而,受限于卷积操作和目标函数,Pix2Pix表明,覆盖的噪音常常会被模型忽视。模型输出严重依赖于语义分割输入的mask和dropout,使得高频纹理特征的多样性也是受限的。话句话说,给定一个局部最优的图像到图像的翻译网络$G`$,其采样形式在实际中可能变成了$G’(v,z)\rightarrow \lbrace r_1,r_2,..r_n \rbrace,其中n<<m$。映射的样本空间就变得非常稀疏了。如下图(不同映射机制下,可达的采样空间)所示,我们复制了不同的策略(Pix2Pix,Pix2Pix-HD)以及我们的策略,允许模型的采样空间增加到更大的子集,直至整个域空间,反过来证明了越大的生成器在多样性、分辨率和实现上更好。

3.1 像素级的Mask限制和模型设计
我们提出的生成器架构如下图所示,借用了PGAN生成器的架构,其中的生成器投影了一个latent向量到latent空间,然后接着几个上采样和卷积层来生成输出图像。为了插入语义分割信息,我们构建了一系列的mask特征并拼接二者到对应的latent特征中。这种形式的UNet架构与Pix2Pix的实现很像,但是没有Pix2Pix没有latent向量的输入。
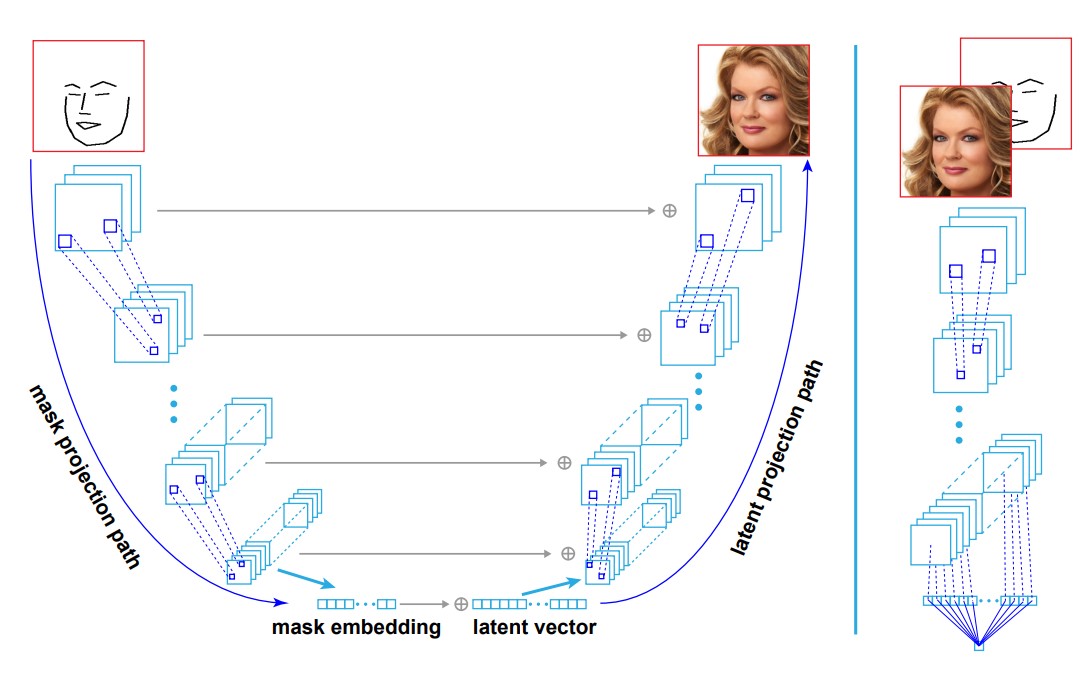
然而,我们观察到此方案的初始的实现,与原始的PGAN架构相比,带有严重的质量下滑。我们将此问题看做是一个空间采样问题,即mask引入了特征投影路径上的限制,从早期层到后续层的特征映射变得越来越不依赖于带mask为输入所引入的在空间和形态学上的限制了,这也导致了模型的训练过程的不稳定和模型能力的衰退。解决方案是,实现一种机制,允许初始的latent特征映射基本与mask限制吻合。然后模型可以使用mask特征的短连接(上图中的水平的箭头)仅作为一种办法来增强像素级限制,而不必抵消过多的模型能力来完成全局的图像结构。我们通过构建一个mask embedding向量并将其嵌入到latent输入向量中来完成此操作(上图左下方)。
3.2 公式
尽管在空间采样问题中同时出现了mask限制和局部精修的纹理细节问题,此条件下上采样大部分由卷积层督导完成。mask输入并不能识别真实图像数据集中某一张图像,但是与一簇真实图片相关。因此,从数据集中收集的mask定义了一部分的真实图像的manifolds(副本)。下图中左上的椭圆说明了一个两部分的猫和狗的mask。我们也展示了由更小的椭圆设定的低分辨率特征。由一系列的卷积层链接,是一个限定接收域的局部操作,扇区是层次继承的并且每个manifold获得了类似的几何结构。我们的结构首先分两步正确地在最低分辨率的manifold上采样了一个mask限制点(1)通过mask embedding定位准确的扇区。(2)通过一个latent 特征向量在扇区内采样一个点。然后一个上采样步骤精修了细节并通过垂直的mask信息注射增强了mask限制。两部分,latent特征向量和mask embedding,是我们的方法与其他方法的根本区别。

图示说明:展示了使用一个狗的mask为指引的图像生成过程。左边:展示了图像生成过程中使用一系列卷积层处理的特征空间。右边:使用和未使用mask embeding的两个生成狗照片的示例。在inference时,带mask embeding的完美的模型投影基础特征到正确的manifold并使用卷积层执行合适的上采样。然而,没有mask embeding的模型学习到的是(1)只投影平均的基础图像(2)即便按照mask 限制,也只能低效地映射基础图像到狗。
现在着重说说latent特征向量和mask embedding。如果没有latent 特征向量,Pix2Pix或Pix2Pix-HD这类模型只有mask输入,而没有足够的随机性。因此,其生成的图像几乎完全没mask限定到唯一了。没有latent特征向量的模型生成的图像的多样性是十分有限的。相反,我们的模型有latent向量,它编码了一个大的多样性的细节。给定一个mask,我们可以生成十分不同的图像,并保有精良的细节。
如果没有mask embeding,比如Tube-GAN,其限制在低维特征得不到重视,以及后面层中的参数可能需要纠正分辨率图像的一些错误,这限制了它在表达细节的能力。而我们的模型使用mask embedding潜在地找到了正确的扇区,big生成正确的latent空间表征。因此,所有的后续层可以更集中在生成细节上。上图就用卡通图展示了这种对比。蓝色点线,是我们模型的处理过程并从第二列到最优列生成以不同分辨率生成狗的图像。后续的网络层,卷积层和mask嵌入将图像从猫纠正到狗。不幸的是,最后的图像看起来像狗,但是分辨率太低。上图并不是真实的,但是在现实场景中我们观察到类似的场景。这些观测说明,嵌入mask embedding显著提升了特征映射效率。
3.3 架构
我们提出的模型由mask 投影路径和latent投影路径分别对应了UNet的contracting和expanding路径。输入到mask投影路径是一个二值面部边缘map。mask经过一系列blocks之后,每个block由2个卷积层,strides分别为1和2.每个block输出一个递增数目的特征到接下来的网络层,并仅连接前面的8个特征到latent投影路径来形成mask限制。
mask投影路径有两个主要的函数。第一个给latent投影路径上的特征上采样过程提供空间限制。第二个,输出mask embedding告知latent投影层其特征特征聚类簇,极可能与特定mask关联。为了反映事实:左边的contracting路径上的mask特征主要扮演着限制者角色,只有8个mask特征被拼接到网络的latent投影路径上。此设计基于两点
- 更多的特征需要更大的模型能力来将它们合适的融合到投影的latent特征上
- 我们之前的实验表明一个训练过的模型会基本上将mask特征相差无几地投影到特定模式上。
4 训练
三个模型都是用WGAN-GP的损失函数等式。Pix2Pix的baseline直接以目标分辨率训练了25个epochs。我们的带mask embedding和不带mask embedding模型都是用了渐进式progressive growing训练策略(源于pGAN)。我们从第一个输出分辨率$8\times 8$开始,训练了45k步,然后在新卷积blocks中fade加倍输入和输出分辨率。鉴于mask投影路径的轻量的权重,没有实现其fading连接。
为了对比mask embedding机制的效果,训练过程的超参数batch size,learing rate和每个生成器的判别器的优化数目都是一样的。是用了$batch size=256$,输出分辨率$8\times 8$。每次加倍输出分辨率的时候缩减一半的batch size。学习率初始设定为0.001,并且在模型的输出分辨率达到256时,增加到0.002.使用Tensorflow写的代码,每个模型在4块Nvidia V100上训练2天达到最终的分辨率512.
5 实验
我们对比了Pix2Pix baseline(23.23M)的生成器,和我们的不带embedding的baseline(23.07M),和我们带embedding的模型,在图像合成任务中,使用Celeba-HQ数据集。没有对比Pix2Pix-HD,因为其个体实例级的特征embedding机制依赖于mask的perturbation来生成多样图像。而我们的模型在latent’投影路径上(对Pix2Pix来说是上采样路径)来说是保持相似的。我们的两个模型的baseline的判别器和模型相同都包含了23.07M个参数。生成器的性能使用切片的Wassertein 距离来衡量(SWD)。
5.1 Celeba-HQ数据集
使用此数据集,我们使用python的Dlib包抽取了每个面部的68个关键点,关键点的检测是在分辨率为1024的图像上做的。面部关键点与原始标注的属性严重不符的图像被删掉,最后总共有27000张图像被选做训练集。
5.2 量化评估
我们使用切片的SWD距离来评估模型的效果,下表展示了之前的一些参数设置。由于内存限制,SWD在批量的每一对合成图和真实上计算平均值。玩魔兽先计算240对(真图-合成图)图像,然后重复直至覆盖了8192对。我们首先生成图像从$512\times 512$到$16\times 16$分辨率的拉普拉斯金字塔。每个层级的金字塔我们抽取128个$7\times 7$的patches,正则化然后计算与每一层的真图的平均距离。下图,SWD指标集中于我们的方法和其他方法的不同表现。
| Configurations | 512 | 256 | 128 | 64 | 32 | 16 | avg |
|---|---|---|---|---|---|---|---|
| Real | 10.82 | 9.98 | 10.14 | 9.75 | 9.83 | 7.52 | 9.67 |
| Pix2Pix | 67.74 | 27.72 | 25.08 | 20.46 | 19.05 | 151.78 | 65.52 |
| 不带embedding | 58.20 | 27.7722.19 | 18.25 | 17.58 | 70.49 | 35.57 | |
| 带embedding | 43.74 | 22.46 | 17.48 | 14.83 | 13.65 | 37.57 | 24.96 |
可以看到使用mask embedding可以取得更好的合成图像质量。
5.3 量化对比

- a: 输入的mask
- b: 使用Pix2Pix合成的图。【只能生成十分相似的粗糙的风格】
- c: 使用我们的不带mask embedding baseline模型合成的效果【无法生成高保真的纹理特征】
- d: 使用我们的带mask embedding模型合成的效果
不带embedding的模型无法生成高稳定性的纹理特征。生成的图像包含了主要的噪音实现和上采样的人工痕迹或多或少地增加了模型能力。观测结果也符合我们的假设,即不带embedding的模型会被强制投影出示的特征到样本分布的重叠空间,这就导致了模糊的特征纹理以及模棱两可的结构。生成器能力不充分的结果便是模型会生成明显的人工痕迹,比如对角直线和棋盘纹理模式。
5.4 改变Latent输入

- a: 输入的mask
- b: 原图
- c,d,e: 使用相同mask,但是不同latent 向量合成的图
上图展示了,相同的mask输入可以与不同的latent向量并生成不同的人脸。我们也注意到latent向量和mask embedding并不完全是不关联的。latent向量更多的是侧重图像风格,即头发、皮肤、面部头发。另一方面,面部关键点标记应该是由提供的mask图决定的。不足之处是,与各种各样的不同的面部相比图像数量过少。我们观察到一些面部mask与某些特性粘合,比如性别、皮肤颜色等与我们给定的面部mask不是明显相关的。后续可以增加更多的抽象mask和对应的数据集可能可以克服这个问题。并且,实现随机模糊和mask特征的dropout可以帮助增加输出的多样性。
5 代码逻辑
