https://www.analyticsvidhya.com/blog/2019/02/outlier-detection-python-pyod/
1 什么是离群点
一个极大的偏离正常值的数据点。下面是一些常见的离群点
- 一个学生的平均得分超过剩下90%的得分,而其他人的得分平均仅为70%。显然的离群点
- 分析某个顾客的购买行为,大部分集中在100-块,突然出现1000块的消费。
有多种类型的离群点
- 单变量的: 只有一个变量的值会出现极端值
- 多变量的: 至少两个以上的变量值的综合得分极端。
2 为什么需要检测离群点
离群点会影响我们的正常的数据分析和建模,如下图左边是包含离群点的模型,右边是处理掉离群点之后的模型结构。
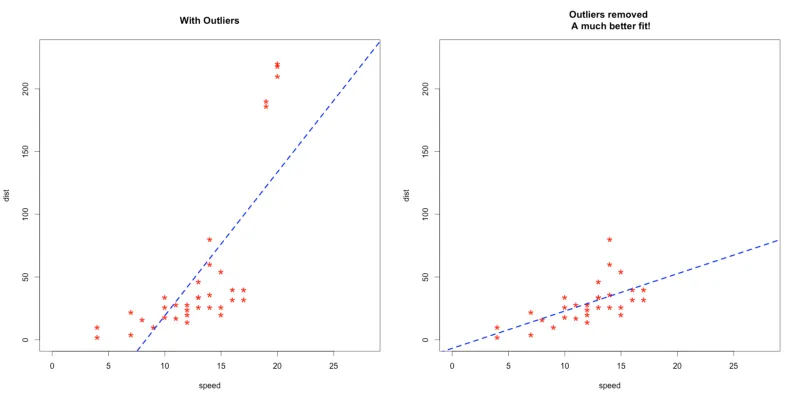
但是,离群点并非一直都是不好的。简单的移除离群点并非明智之举,我们需要去理解离群点。
现在的趋势是使用直接的方式如盒图、直方图和散点图来检测离群点。但是在处理大规模数据集和需要在更大数据集中识别某种模式时,专用的离群点检测算法是非常有价值的。
某些应用,如金融欺诈识别和网络安全里面的入侵检测需要及时响应的以及精确的技术来识别离群点。
3 为什么要使用PyOD 来做离群点检测
现有的一些实现,比如PyNomaly,并非为了做离群点而设计的(尽管依然值得一试)。PyOD是一个可拓展的Python工具包用来检测多变量数据中的离群点。提供了接近20种离群点检测算法。
4 PyOD的特征
- 开源、并附有详细的说明文档和实例。
- 支持先进的模型,包括神经网络,深度学习和离群点检测集成学习方法
- 使用JIT优化加速,以及使用numba和joblib并行化
- python2 和3 都可以用
5 安装使用PyOD
1 | pip install pyod |
注意,PyOD包含了一些神经网络模型,基于keras。但是它不会自动安装Keras或者Tensorflow。需要手动安装这两个库,才能使用其神经网络模型。安装过程的依赖有点多。
6 使用PyOD来做离群点检测
注意,我们使用的是离群得分,即每个模型都会给每个数据点打分而非直接根据一个阈值判定某个点是否为离群点。
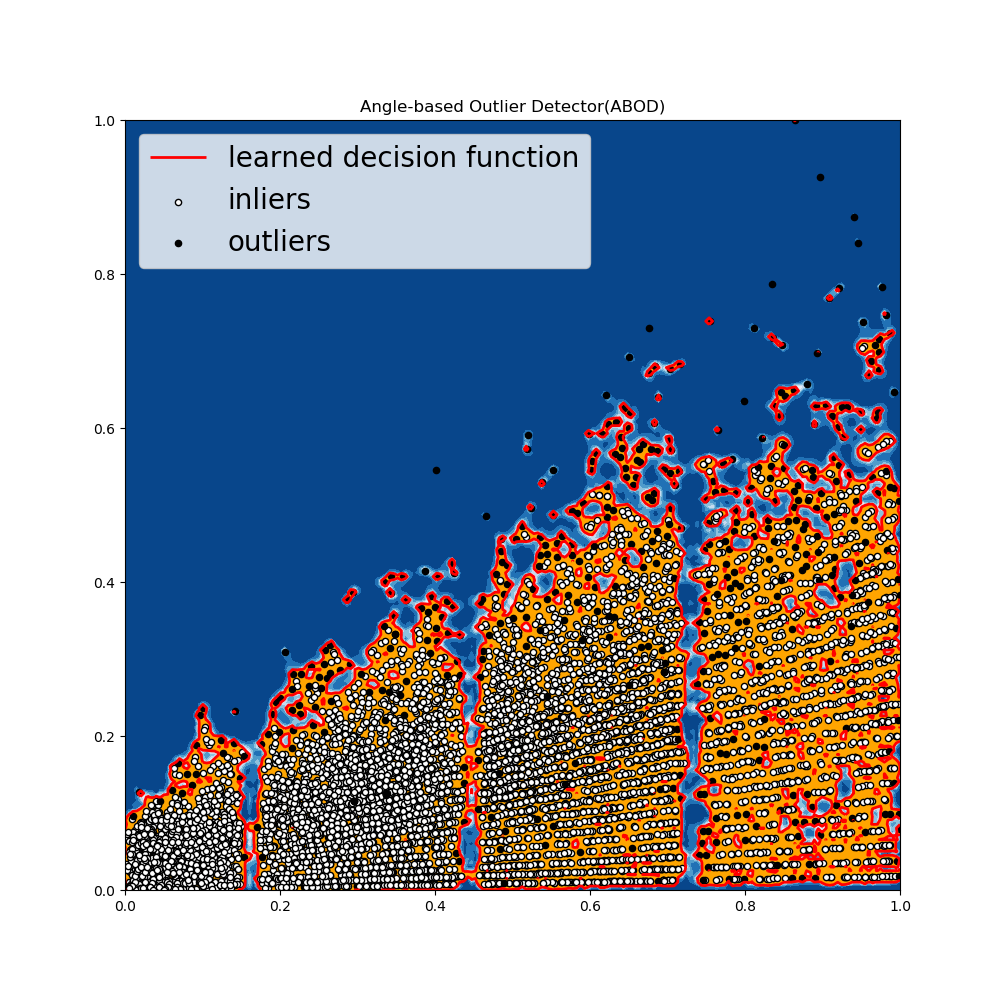
Angle_Based Outlier Detection (ABOD)
- 它考虑了每个数据点和其邻居的关系,但是不考虑邻居之间的关系。
- ABOD在多维度数据上表现较好
- PyOD提供了两种不同版本的ABOD
- Fast ABOD:使用KNN来近似
- Original ABOD:以高时间复杂度来考虑所有训练数据点
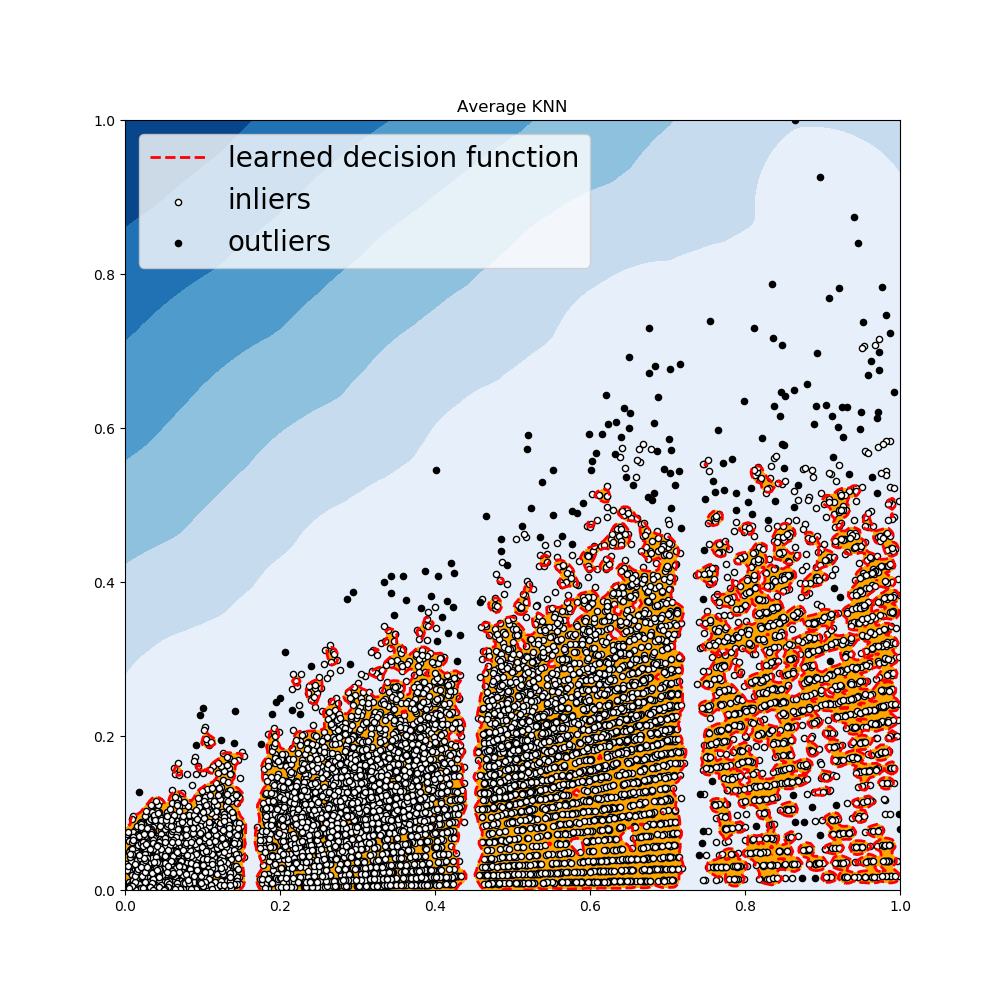
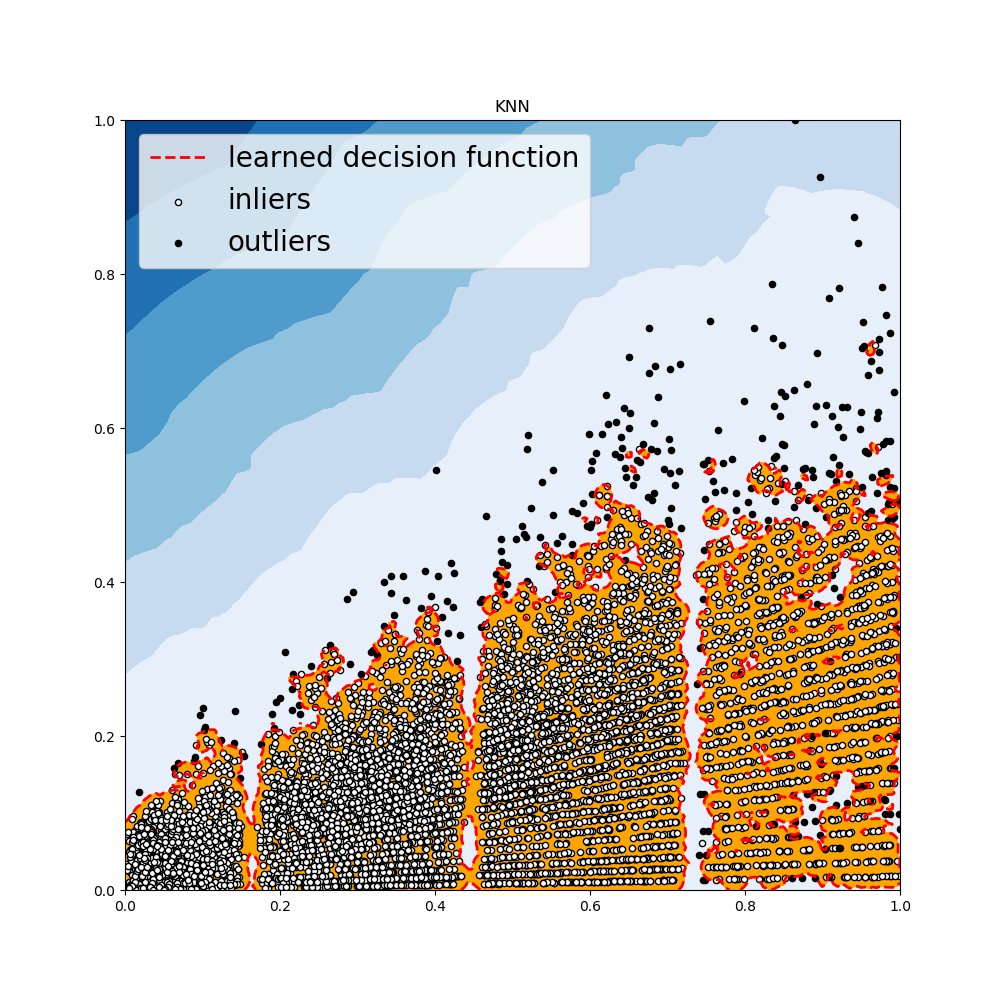
KNN 检测器
- 对于任意数据点,其到第k个邻居的距离可以作为其离群得分
- PyOD提供三种不同的KNN检测器
Largest: 使用第k个邻居的距离来作为离群得分Mean: 使用全部k个邻居的平均距离作为离群得分Median:使用k个邻居的距离的中位数作为离群得分
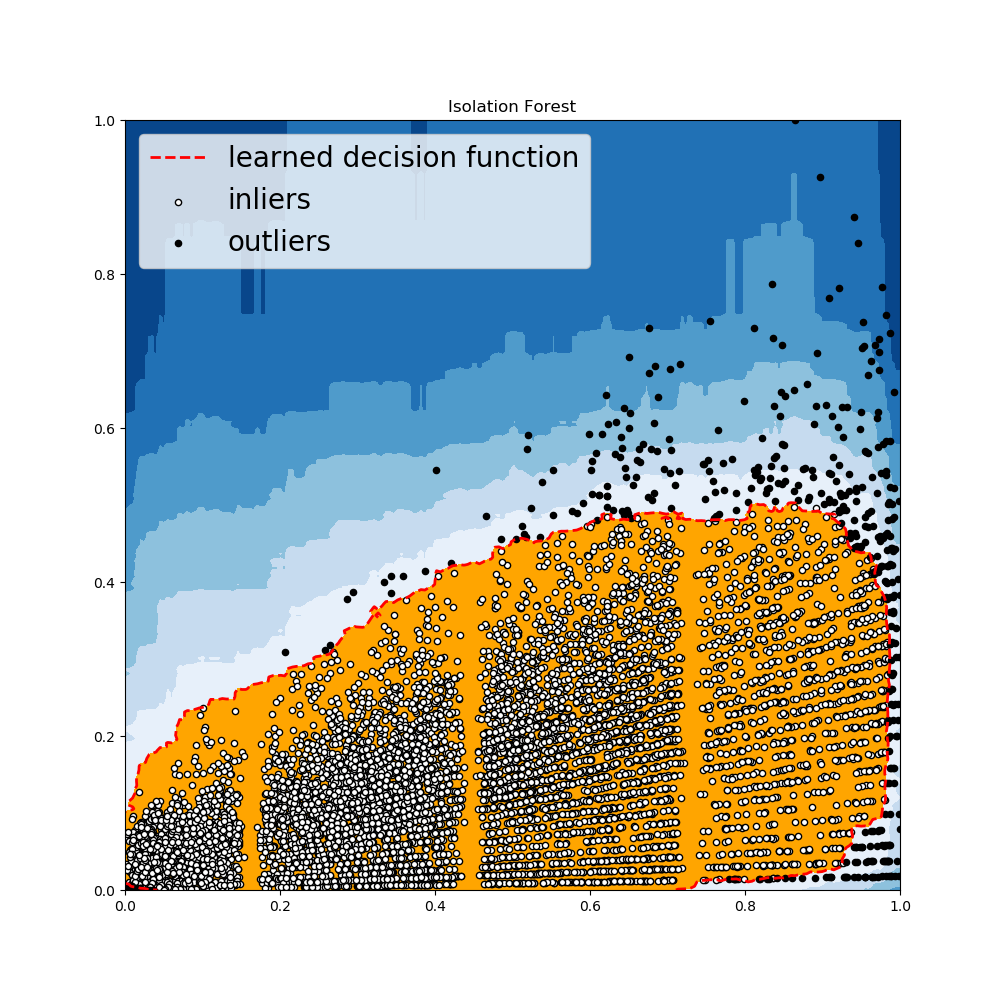
- 内部使用sklearn,此方法中,使用一个集合的树来完成数据分区。孤立森林提供农一个离群得分来判定一个数据点在结构中有多孤立。其离群得分用来将它与正常观测数据区分开来。
- 孤立森林在多维数据上表现很好
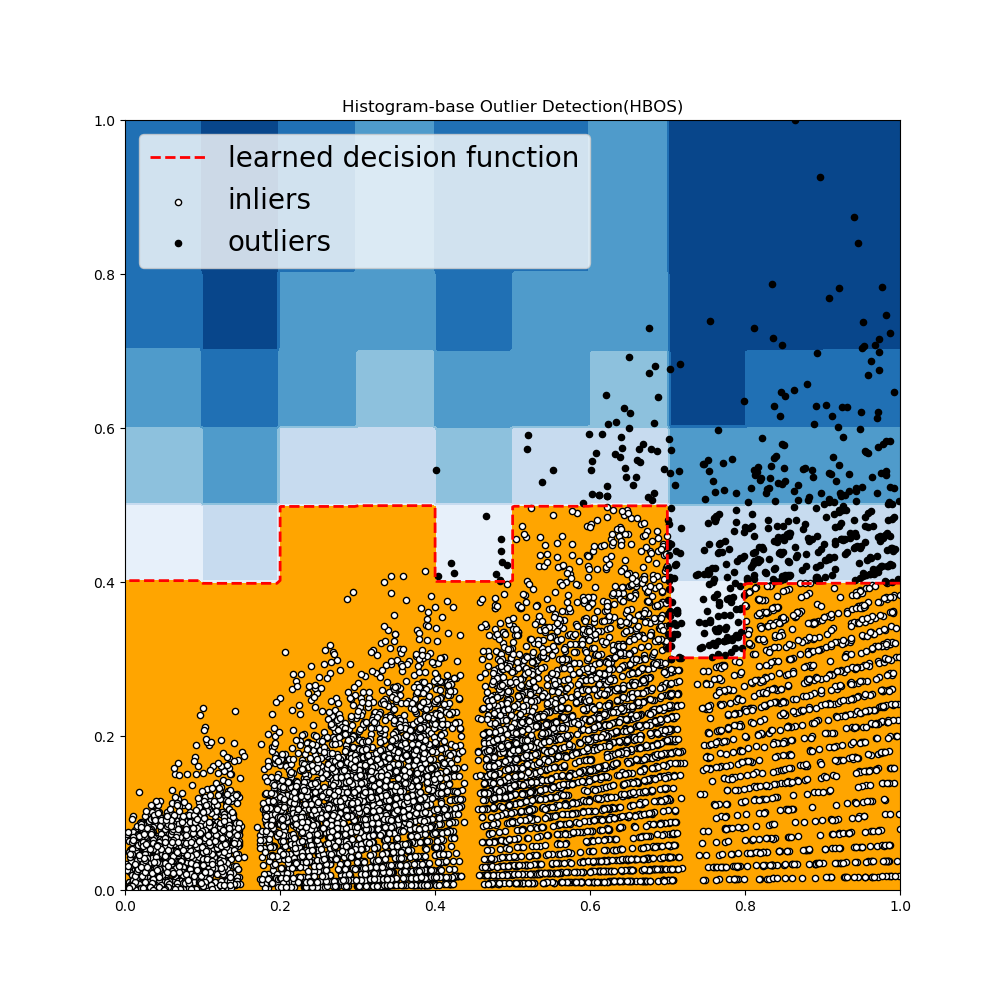
Histogram-based Outiler Detection
- 一种高效的无监督方法,它假设特征之间独立,然后通过构建直方图来计算离群得分
- 比多变量方法快得多,但是要损失一些精度
Local Correlation Integral(LOCI)
- LOCI在离群检测和离群点分组上十分高效。它为每个数据点提供一个LOCI plot,该plot反映了数据点在附近数据点的诸多信息,确定集群、微集群、它们的半径以及它们的内部集群距离
- 现存的所有离群检测算法都无法超越此特性,因为他们的输出仅仅是给每个数据点的输出一个单一值。
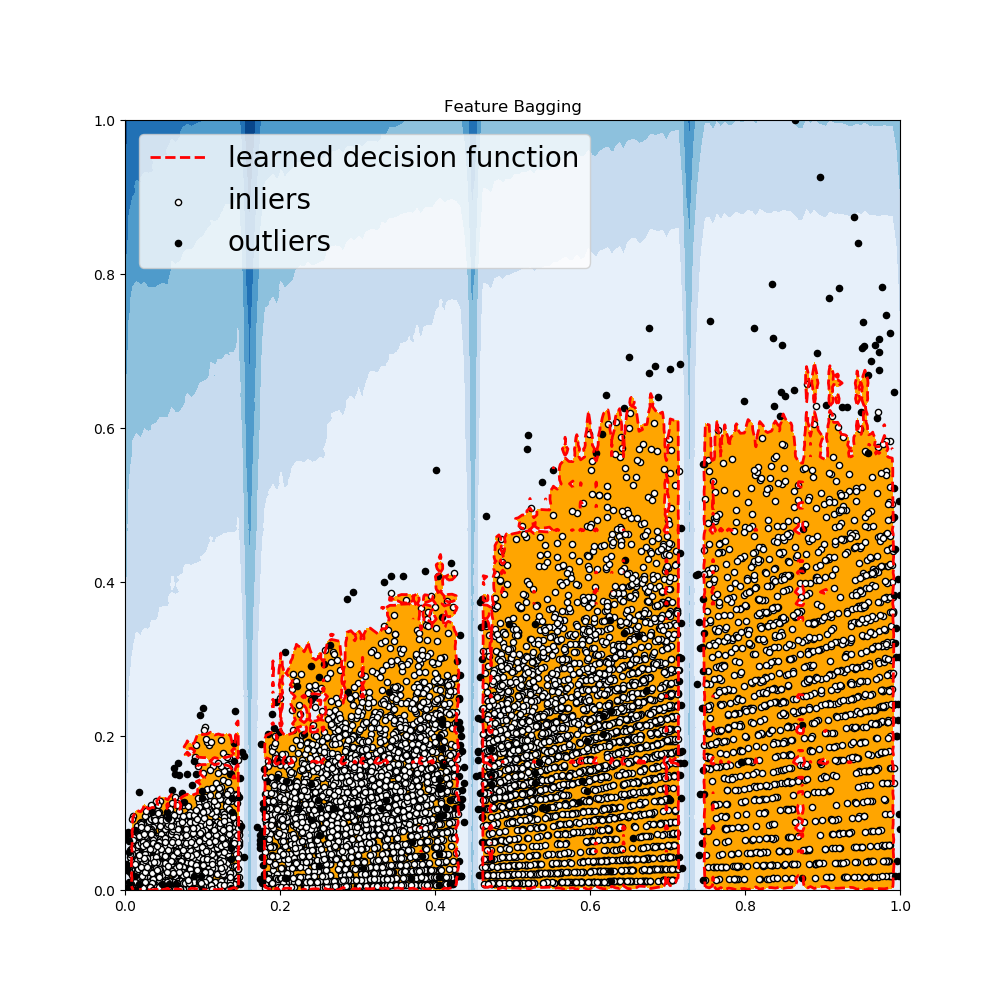
Feature Bagging
- 一个特征集合检测器,它在数据集的一系列子集上拟合了大量的基准检测器。它使用平均或者其他结合方法来提高预测准确率
- 默认使用LOF(Local Outiler Factor)作为基准评估器。但是其他检测器,如KNN,ABOD都可以作为基准检测器
- Feature Bagging首先通过随机选取特征子集来构建n个子样本。这带来了基准评估器的多样性。最终,通过取所有基准评估器的平均或者最大值来预测得分。
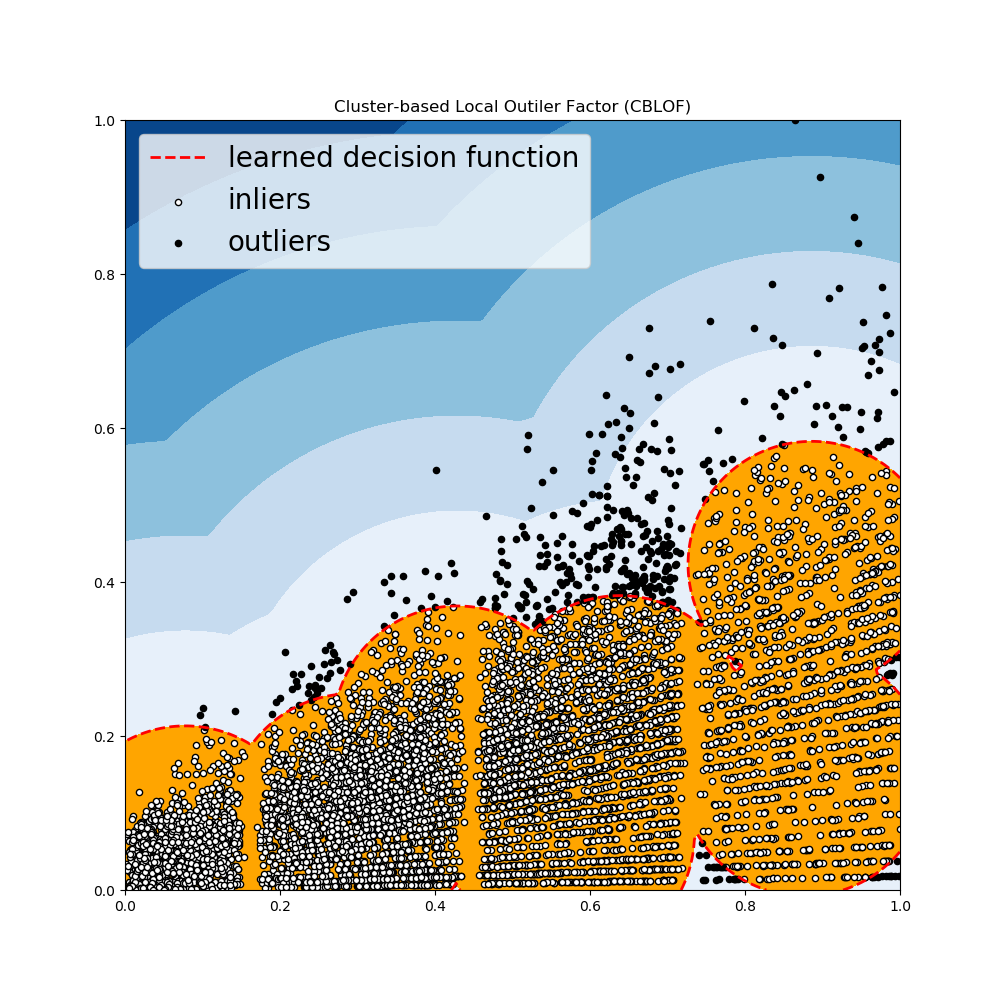
*Clustering Based Local Outiler Factor
- 它将数据分为小聚类簇和大聚类簇。离群得分基于数据点所属的聚类簇的大小来计算,距离计算方式为到最近大聚类簇的距离。
7 PyOD在 Big Mart Sales 问题上的表现
Big Mart Sales Problem。需要注册然后下载数据集,附件中有
1 | import pandas as pd |
结果如下;