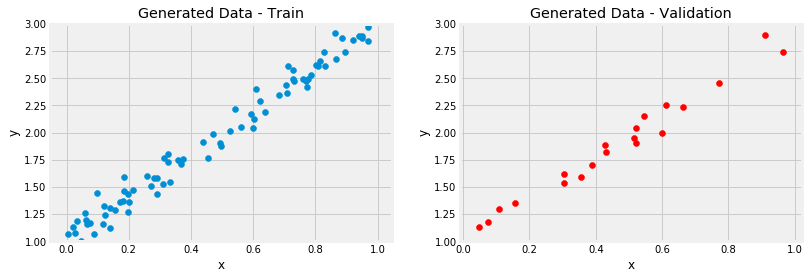
# 初始化线性回归的参数 a 和 b np.random.seed(42) a = np.random.randn(1) b = np.random.randn(1) print("初始化的 a : %d 和 b : %d"%(a,b)) leraning_rate = 1e-2 epochs = 1000 for epoch in range(epochs): pred = a+ b*x_train # 计算预测值和真实值之间的误差 error = y_train-pred # 使用MSE 来计算回归误差 loss = (error**2).mean() # 计算参数 a 和 b的梯度 a_grad = -2*error.mean() b_grad = -2*(x_train*error).mean() # 更新参数:用学习率和梯度 a = a-leraning_rate*a_grad b = b -leraning_rate*b_grad
a = torch.randn(1, dtype=torch.float).to(device) b = torch.randn(1, dtype=torch.float).to(device) # and THEN set them as requiring gradients... a.requires_grad_() b.requires_grad_() print(a, b)
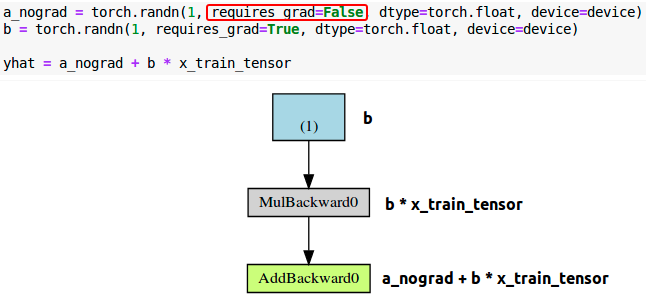
最佳策略当然是初始化的时候直接赋予requires_grad=True属性了
1 2 3 4 5
# We can specify the device at the moment of creation - RECOMMENDED! torch.manual_seed(42) a = torch.randn(1, requires_grad=True, dtype=torch.float, device=device) b = torch.randn(1, requires_grad=True, dtype=torch.float, device=device) print(a, b)
torch.manual_seed(42) a = torch.randn(1, requires_grad=True, dtype=torch.float, device=device) b = torch.randn(1, requires_grad=True, dtype=torch.float, device=device)
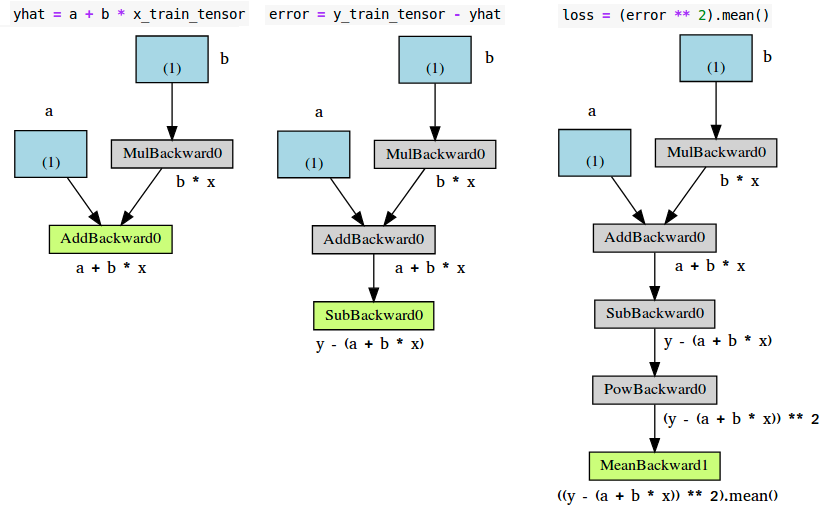
for epoch in range(n_epochs): yhat = a + b * x_train_tensor error = y_train_tensor - yhat loss = (error ** 2).mean()
# 这个是numpy的计算梯度的方式 # a_grad = -2 * error.mean() # b_grad = -2 * (x_tensor * error).mean() # 告诉pytorch计算损失loss,计算所有变量的梯度 loss.backward() # Let's check the computed gradients... print(a.grad) print(b.grad) # 1. 手动更新参数,会出错 AttributeError: 'NoneType' object has no attribute 'zero_' # 错误的原因是,我们重新赋值时会丢掉变量的 梯度属性 # a = a - lr * a.grad # b = b - lr * b.grad # print(a) # 2. 再次手动更新参数,这次我们没有重新赋值,而是使用in-place的方式赋值 RuntimeError: a leaf Variable that requires grad has been used in an in- place operation. # 这是因为 pytorch 给所有需要计算梯度的python操作以及依赖都纳入了动态计算图,稍后会解释 # a -= lr * a.grad # b -= lr * b.grad
# 3. 如果我们真想手动更新,不使用pytorch的计算图呢,必须使用no_grad来将此参数移除自动计算梯度变量之外。 # 这是源于pytorch的动态计算图DYNAMIC GRAPH,后面会有详细的解释 with torch.no_grad(): a -= lr * a.grad b -= lr * b.grad # PyTorch is "clingy" to its computed gradients, we need to tell it to let it go... a.grad.zero_() b.grad.zero_() print(a, b)
torch.manual_seed(42) a = torch.randn(1, requires_grad=True, dtype=torch.float, device=device) b = torch.randn(1, requires_grad=True, dtype=torch.float, device=device) print(a, b)
lr = 1e-1 n_epochs = 1000
# Defines a SGD optimizer to update the parameters optimizer = optim.SGD([a, b], lr=lr)
for epoch in range(n_epochs): # 第一步,计算损失 yhat = a + b * x_train_tensor error = y_train_tensor - yhat loss = (error ** 2).mean() # 第二步,后传损失 loss.backward() # 不用再手动更新参数了 # with torch.no_grad(): # a -= lr * a.grad # b -= lr * b.grad # 使用优化器的step方法一步到位 optimizer.step() # 也不用告诉pytorch需要对哪些梯度清零操作了,优化器的zero_grad()一步到位 # a.grad.zero_() # b.grad.zero_() optimizer.zero_grad() print(a, b)
torch.manual_seed(42) a = torch.randn(1, requires_grad=True, dtype=torch.float, device=device) b = torch.randn(1, requires_grad=True, dtype=torch.float, device=device) print(a, b)
class ManualLinearRegression(nn.Module): def __init__(self): super().__init__() # To make "a" and "b" real parameters of the model, we need to wrap them with nn.Parameter self.a = nn.Parameter(torch.randn(1, requires_grad=True, dtype=torch.float)) self.b = nn.Parameter(torch.randn(1, requires_grad=True, dtype=torch.float)) def forward(self, x): # Computes the outputs / predictions return self.a + self.b * x
# Now we can create a model and send it at once to the device model = ManualLinearRegression().to(device) # We can also inspect its parameters using its state_dict print(model.state_dict())
for epoch in range(n_epochs): # 注意,模型一般都有个train()方法,但是不要手动调用,此处只是为了说明此时是在训练,防止有些模型在训练模型和验证模型时操作不一致,训练时有dropout之类的 model.train()
# No more manual prediction! # yhat = a + b * x_tensor yhat = model(x_train_tensor) loss = loss_fn(y_train_tensor, yhat) loss.backward() optimizer.step() optimizer.zero_grad() print(model.state_dict())
def make_train_step(model, loss_fn, optimizer): # Builds function that performs a step in the train loop def train_step(x, y): # Sets model to TRAIN mode model.train() # Makes predictions yhat = model(x) # Computes loss loss = loss_fn(y, yhat) # Computes gradients loss.backward() # Updates parameters and zeroes gradients optimizer.step() optimizer.zero_grad() # Returns the loss return loss.item() # Returns the function that will be called inside the train loop return train_step
然后在每个epoch时迭代模型训练
1 2 3 4 5 6 7 8 9 10 11 12
# Creates the train_step function for our model, loss function and optimizer train_step = make_train_step(model, loss_fn, optimizer) losses = []
# For each epoch... for epoch in range(n_epochs): # Performs one train step and returns the corresponding loss loss = train_step(x_train_tensor, y_train_tensor) losses.append(loss) # Checks model's parameters print(model.state_dict())