特征工程有点用,模型构建基本没说
0 引言
当前检测人机的方法分为两类,客户端检测和服务端检测。客户端的检测主要是图灵测试。但是图灵测试类,比如验证码识别无法应用于工业界,因为比较影响游戏体验,频繁的校验也容易导致系统崩溃。服务端的方法主要是识别人机的独特特征。过往的数据挖掘的方法有一些短板。首先,没有通用性,一个游戏的方法无法应用于另外一个游戏。再者,人机的开发者也会改变人机的行为策略绕过算法检测。
考虑到人机最终要将它们在游戏中的财富汇聚到特定RMTer,我们开发了基于金融数据分析的方法,分析游戏中金币和财产流动。这在两个方面很高效。首先,人机无法回避金融行为模式,如果人机之间不断进行交易特定的金融模式一定存在。其次,金融分析可以应用不同游戏。
使用RNN分析游戏Aion游戏中玩家日志,评估模型在检测人机金融模式的精确性,并表现出以下优势。
- 稳定性:因为角色的金融模式序列不可回避,即便其改变模式或者装成普通玩家,依然有被识别
- 通用性:可以应用于多种游戏
- 独立性:训练一次即可检测人机
- 安全性:神经网络是一类黑盒模型,人机开发者很难识别其中判定模式的阈值
1 过往检测方法梳理
以前的服务端检测方法主要集中在分析人机独特的行为模式,如下表所示,分为充分条件(可能由人机产生的但不绝对)和必要条件。由于充分条件包括了人机独特的行为模式,我们可以识别一段时间内的人机,但是充分条件的分析需要重复更新,因为这些条件是不连续的。如果人机的开发者发更新了策略,模型也需要跟着更新。而必要条件是人机一定会出现的特征,由于人机就是用来积累游戏财富的,特定行为如人机之间交易一定会发生。即便人机开发者改变了策略,财富积累模式也不会改变。
充分条件的分析检测方法分两种数据类型:行为动作和社交动作。行为动作描述的是角色的物理活动,比如移动、攻击、使用技能等。分析用户的动作序列要借助大数据平台。特定的行为序列和简单的积分算法和朴素贝叶斯算法可以检测人机。同时也可以根据角色行为的相似性来检测人机。它们将行为序列按照时间窗口划分,然后嵌入到特征向量中。论文表明,使用逻辑回归根据角色的自相似性可以判定人机在游戏中的行为模式由类似的行为模式。
社交动作也表现出独特的行为模式。玩家之间聊天,组团完成任务,创建公会等。论文1根据聊天内容分析文本的词法、语义来做文本挖掘。人机有相似的聊天模式来规避检测规则,使用机器学习做文本特征分析取得不错效果。论文2根据组团游戏日志分析来做人机检测,在一个短时间内人机与人类玩家在组团(party play)时的模式有较大差异。并发布了一些检测人机的阈值。
上述基于充分条件的方法有较好性能,但是稳定性不够。如果人机开发者改变算法,检测方法也需要跟着改变,而且现在的人机已经很智能,能有效模拟一些人类行为。所以,提出了使用必要条件的检测方法。金融特征,如角色资产等级和交易活动都可以使用。论文3分析了人机之间的交易地理位置,表明其显示出相似的模式。论文分析了一个地图内金融交易的特定坐标,使用Density-Based Spatial Clustering with Noise(基于密度的带噪音的频谱聚类方法)。论文4构建了虚拟世界中的交易的拓扑网络来识别人机之间的特定的交易模式,表明人机为了高效地采集游戏中地物资会出现不同地角色。
必要条件地分析表明金融特征对于区分人机是十分有意义地,但是如果人机地开发者改变了交易的场所。如果人机使用邮件交易物品、金币,那么将不会留下交易的位置坐标信息。拓扑网络虽然可以解释人机交易的宏观逻辑,但是没法揭示单个人机大的。构建一个网络需要大量资源,并且需要根据交易频繁更新。
本文使用的是基于金融分析的方法,分析了角色的金融状态(如金币数量、拥有物品等),人机活动的必要条件。使用金融状态而非其他特征,是因为这些金融状态本身不能被修改,是人机开发者无法规避的。为详细解释单个人机的金融数据,外面使用了LSTM算法。因为神经网络方法相比于拓扑网络需要更少的资源,使得经济模型易于构建。
服务端人机检测方法
| 类别 | 数据类型 | 模型 |
|---|---|---|
| 充分条件 | 行为动作 | $序列模式\自相似动作\动作序列$ |
| 充分条件 | 社交动作 | $聊天日志分析\组团游戏日志分析$ |
| 必要条件 | 交易 | 网络分析 |
| 必要条件 | 游戏中资产增减的坐标 | DBSCAN |
2 方法
2.1 数据收集
使用的是游戏AION 2010年5月份第一周的数据集。
- 特征选取。去掉不必要的信息,下表是我们从日志中抽取的金融相关信息,揭示了角色状态的金融信息。
| 类型 | 详细特征 |
|---|---|
| ID | 角色ID,账户ID |
| 位置 | 位置坐标,地图数量 |
| 玩家信息 | 血量,魔法值状态,经验点数 |
| 社交信息 | $组团ID\盟友ID$ |
| 金融信息 | 金币状态,物品状态,库存状态 |
- Ground-Truth确认:需要标记哪些是真人机,哪些是普通用户。真实表情由人工去确认疑似人机的账户。
2.2 特征工程
特征工程分两步:
- 剔除没有影响的特征:为使用神经网络方法,模型需要学习到人机和普通用户动态数据的差异。因此我们设定了下面一些规则来过滤掉不重要的特征。剔除之后的重要特征表2
- 规则1表明,模型无法学习模式差异。如果人机和人类的某个特征值相同,它便是没有区分力的,可以删去。
- 规则2证明,如果特征值为0,其标准差也为0,会带来训练数据集稀疏性。剔除满足规则2的特征,以减少稀疏性。
| 序号 | 类型 | 特征 | 描述 |
|---|---|---|---|
| 1 | 物品 | 物品数量 | 一个角色拥有的全部物品数量 |
| 2 | 金币 | $总金币数\ 账户中金币余额\ 角色银行中的金币\ 在供应商手里的金币$ | $角色拥有的总金币数\ 角色在库存(inventory)中持有的总金币数\ 角色寄存在warehouse(账房)的总金币数\与供应商或者拍卖行交易的金币数量$ |
| 3 | 评估的资产值 | $评估的资产值\ 邮件中资产估值\ 角色银行资产估值\ 账户银行资产估值$ | $所有物品和金币的总价值估价\ 所有经过邮件发送和接受到的物品的估值\ 角色存储在warehouse中所有物品和金币总估值\账户存储在warehouse中所有物品和金币总估值$ |
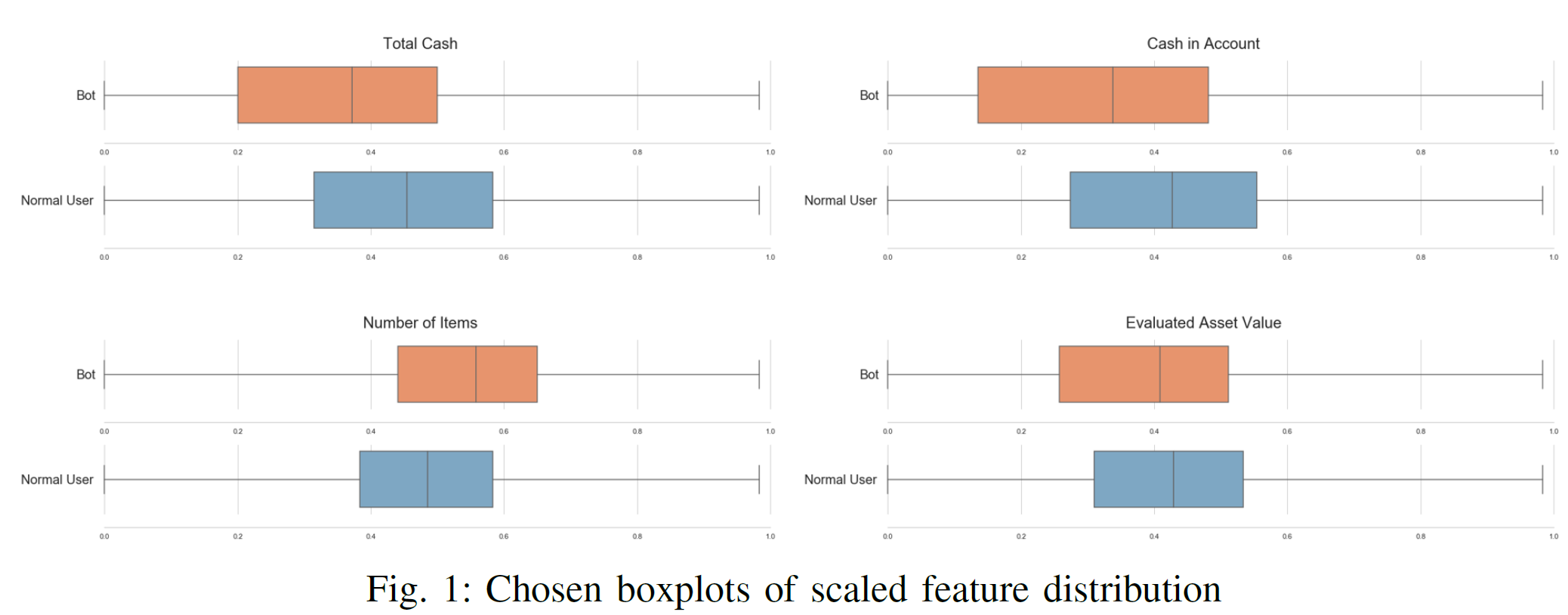
- 缩放的时间滑窗。日志级别的数据需要做一些处理来训练神经网络。神经网络擅长从固定长度的数据中学习规律,长的时间序列数据需要剪切。我们设定固定长度的时间窗口,并做不同缩放以不同规模的数据。根据公式$X_{normalization}=\frac{X_i-Min(X_i)}{Max(X_i)}$ ,我们将数据缩放到0-1之间。我们比较了特征的统计差异看它们是否与标签一致。如下表1,特征如总金币数,账户中金币数,物品数以相同缩放尺寸是表现出不同分布。考虑到这些差异,我们认为金融特征可以用来区分人机和普通玩家。
2.3 模型
我们使用的是LSTM模型,使用固定batchsize,同时使用正则化技术防止过拟合。
2.4 实验结果
为获得足够的训练数据,我们将每个月的数据按照周划分。我们随机混合数据,并进行10-折交叉验。下表是一些结果
| 实验数据 | 准确率 | 精确率 | 召回率 | F1-score |
|---|---|---|---|---|
| 第一周 | 0.9494 | 0.9385 | 0.9759 | 0.9490 |
| 第二周 | 0.9401 | 0.9168 | 0.9831 | 0.9488 |
| 第三周 | 0.9487 | 0.9237 | 0.9886 | 0.9551 |
| 第四周 | 0.9509 | 0.9103 | 0.9861 | 0.9476 |
| 平均 | 0.9473 | 0.9223 | 0.9834 | 0.9501 |
参考论文
- Chatting pattern based game bot detection: do they talk like us?” KSII Transactions on Internet & Information Systems,
- Online game bot detection based on party-play log analysis,” Computers & Mathematicswith Applications
- H. M. Song and H. K. Kim, “Game-bot detection based on clustering of asset-varied location coordinates,” Journal of the Korea Institute of Information Security and Cryptology
- E. Lee, J. Woo, H. Kim, and H. K. Kim, “No silk road for online gamers!: Using social network analysis to unveil black markets in online games,” in Proceedings of the 2018 World Wide Web Conference on World Wide Web.