一 语音的基础概念
1.1 什么是语音
语音是一个连续的音频流,它是由大部分的稳定态和部分动态改变的状态混合构成
1.2 声音如何产生
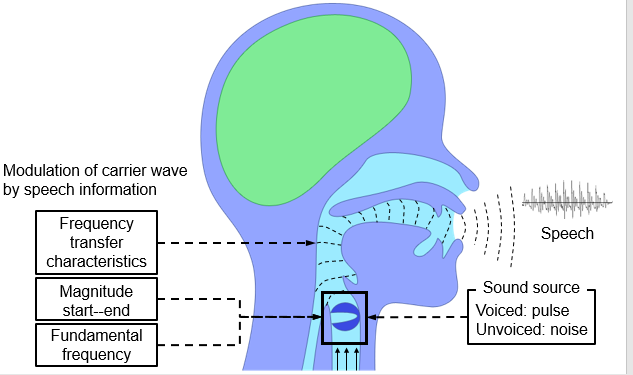
声音由肺部气流并经过声带,此为声源。当我们发元音时,声带被气流震动并生成脉冲序列。此脉冲决定了语音的基准频率。
当我们发出辅音时,声带没有被震动,并产生噪音。然后脉冲或噪声被声带转换或者个性化。
1.3 语音的组成
最小单元是音素,音素组合为音节。
1.3.1 音素
音素是最小的语音单位,它是从音色的角度划分出来的。例如,汉语里的 ɑ、i、u都是音素。一种语言的语音系统大都是由几十个不同的音素组成的
音素分为元音和辅音
元音: 如ɑ、o、e、i、u。
辅音:如b、p、d、t、ɡ、k、s、r。
元音和辅音的区别
- 元音发音时,气流不受阻碍;辅音发音时,气流通过口腔、鼻腔时要受到阻碍
2.元音发音时,发音器官各部位保持均衡的紧张状态;辅音发音时,构成阻碍的部位比较紧张,其他部位比较松弛
3.元音发音时,气流较弱;辅音发音时,气流较强。
4.元音发音时,声带要颤动,发出的声音比较响亮;辅音发音时,有的声带颤动,声音响亮,如m、n、l、r,有的不颤动,声音不响亮,如b、t、z、c。
1.3.2 音节(只适用于汉语)
音节是由音素构成的。如啊”(ā)(1个音素),“地”(dì)(2个音素),“民”(mín)(3个音素)。
音节示例:如“建设”是两个音节,“图书馆”是三个音节,“社会主义”是四个音节。汉语音节和汉字基本上是一对一,一个汉字也就是一个音节。
音节包含了声母、韵母、音调三个部分。
声母: 声母指音节开头的辅音,共有23个。如dā(搭)的声母是d
韵母: 韵母指音节里声母后面的部分,共38。jiǎ(甲)的韵母是iǎ
音节: 声调指整个音节的高低升降的变化。普通话里dū(督)、dú(毒)、dǔ(赌)、dù(度)
根据《现代汉语词典》,汉语标准音节共 418 个
2 音频的表示
2.1 波形表示
波形表示是大家很熟悉的波形表示,就是直接表示出在观测点上所测量到的振幅和时间的关系。当然为了能够将连续的波形记录为数字形式,我们需要对这个波形进行采样(每隔一个固定的时间采取一次测量)和数字化(将连续的数字转化为可用二进制表达的格式)。
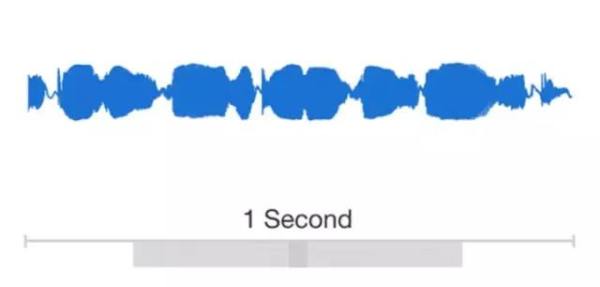
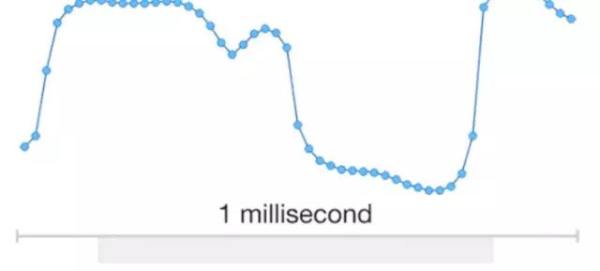
在上面的图中,展示了一秒钟的人声音频片段,以及截取其中一毫秒的数据的放大图
我们最熟悉的CD音频,每秒钟采样44100次(这是因为,根据Nyquist采样定理,如果要完美重现20kHz的音频,那么我们最少需要每秒采样40k次,而20kHz是人类的听觉上限),而每个样本都用16位的二进制来表示。
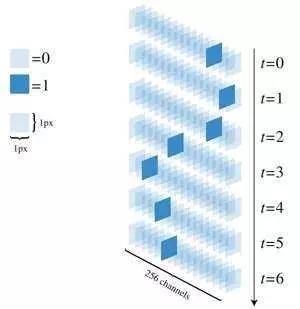
这样每一个样本可以表示最多65,536种不同的振幅。如果假定每一个时间点采用8位的二进制数字来表示,那么总共可能会有256种可能的值,我们就用一个256位的one-hot向量来表示它,最后在计算机中保存的声音片段,就可能是这样的。
2.2 频域表示
如果对输入的波形做一次傅立叶变换,会发现,一个复杂的sine波形,实际上在转换后的“频谱”上,可以被很简单的表示出来。
转换后的音频,是一种频率的表示——我们只关心这个波形到底是以什么样的频率在震动,而恰好,我们人类对于声音的认知,也是基于频率而不是振幅的——实际上这样的表示,更加符合人类对于声音的认知,也更容易对其进行数字处理(DSP)。
3 语音的初步处理
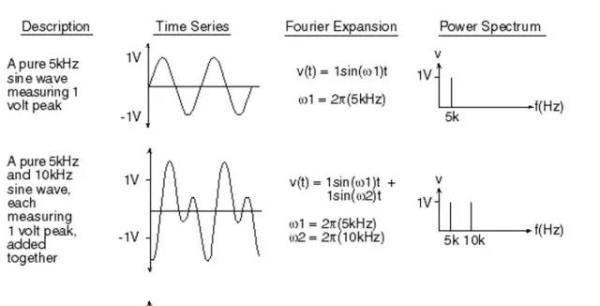
我们知道声音实际上是一种波。常见的mp3等格式都是压缩格式,必须转成非压缩的纯波形文件来处理,比如Windows PCM文件,也就是俗称的wav文件。wav文件里存储的除了一个文件头以外,就是声音波形的一个个点了。下图是一个波形的示例。
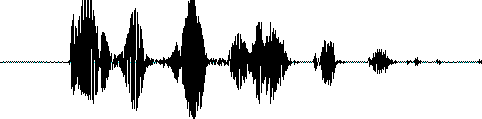
在开始语音识别之前,有时需要把首尾端的静音切除,降低对后续步骤造成的干扰。这个静音切除的操作一般称为VAD,需要用到信号处理的一些技术。要对声音进行分析,需要对声音分帧,也就是把声音切开成一小段一小段,每小段称为一帧。分帧操作一般不是简单的切开,而是使用移动窗函数来实现。帧与帧之间一般是有交叠的,就像下图这样:
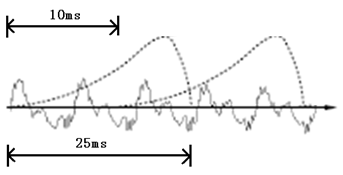
图中,每帧的长度为25毫秒,每两帧之间有25-10=15毫秒的交叠。我们称为以帧长25ms、帧移10ms分帧。
分帧后,语音就变成了很多小段。但波形在时域上几乎没有描述能力,因此必须将波形作变换。常见的一种变换方法是提取MFCC特征,根据人耳的生理特性,把每一帧波形变成一个多维向量,可以简单地理解为这个向量包含了这帧语音的内容信息。这个过程叫做声学特征提取。实际应用中,这一步有很多细节,声学特征也不止有MFCC这一种,具体这里不讲。
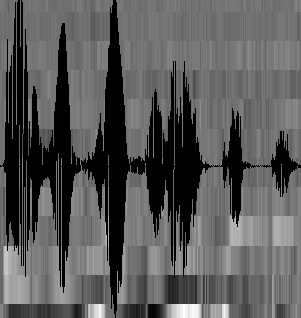
至此,声音就成了一个12行(假设声学特征是12维)、N列的一个矩阵,称之为观察序列,这里N为总帧数。观察序列如下图所示,图中,每一帧都用一个12维的向量表示,色块的颜色深浅表示向量值的大小。
接下来就要介绍怎样把这个矩阵变成文本了。首先要介绍两个概念:
音素:单词的发音由音素构成。对英语,一种常用的音素集是卡内基梅隆大学的一套由39个音素构成的音素集,参见The CMU Pronouncing Dictionary。汉语一般直接用全部声母和韵母作为音素集,另外汉语识别还分有调无调,不详述。
状态:这里理解成比音素更细致的语音单位就行啦。通常把一个音素划分成3个状态。
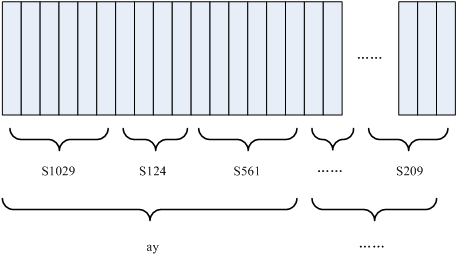
图中,每个小竖条代表一帧,若干帧语音对应一个状态,每三个状态组合成一个音素,若干个音素组合成一个单词。也就是说,只要知道每帧语音对应哪个状态了,语音识别的结果也就出来了。
参考