翻译自: combining-cnn-and-rnn-for-spoken-language-identificatio
github:源码
翻译的原因是觉得示意图很好
输入和输出
正如以前一样,网络的输入是语音记录的图谱。图谱似乎是语音的作为深度学习系统的标准表征形式。
一些网络使用多达11khz的频率(858x256的图像),而其他使用5.5khz的频率(858x128)。通常情况下,使用5.5khz的结果要相对好一点(可能是因为更高的频率没有包含太多有用的信息,反倒更容易过拟合)。
所有网络的输出层都是全连接的softmax层,176个神经元。
网络结构
我们测试了几个网络结构。第一个是纯粹的类似Alex-Net的卷积网络。第二个没有使用任何卷积层,并将(语音)图谱的列作为RNN的序列输入。第三个使用的是,将卷积神经网络抽取出的特征输入到RNN。所有的网络都用Theano和Lasagne。
几乎所有的网络都可以很轻易地在训练集上达到100%的准确率。下表描述的是在验证集上的准确率。
卷积网络
网络结构由6块(block) 2D卷积组成,Relu激活函数,2D maxpooling和BatchNormalization。第一个卷积层的kernel尺寸是 $7\times 7$,第二个是 $5\times 5$,剩下的都是 $3\times 3$。Pooling的尺寸一直都是 $3\times 3$,步长为2.
BatchNormalization可以显著提升训练速度。我们最后只在最后的一个Pooling层和softmax层之间使用了一个全连接层,并使用了50%的dropout。
| 网络 | 准确率 | 注意 |
|---|---|---|
| tc_net | <80% | 此网络与前面描述的CNN的区别在于,这个网络只有一个全连接层。我们并没有怎么训练这个网络,因为ignore_border=False,这个会拖慢训练过程 |
| tc_net_mod | 97.14% | 与tc_net相同,只不过这里不是 ignore_border=False而是加入了pad=2 |
| tc_net_mod_5khz_small | 96.49% | 是tc_net_mod的较小副本,使用的是5.5khz |
Lasagne设置ignore_border=False 会使得Theano不使用CuDnn,将其设置为True,可以显著提升速度。
下面是tc_net_mod的详细网络结构:
| Nr | Type | Channel | Width | Height | Kernel size/stride |
|---|---|---|---|---|---|
| 0 | input | 1 | 858 | 256 | |
| 1 | Conv | 16 | 852 | 250 | 7x7/1 |
| Relu | 16 | 852 | 250 | ||
| MaxPooling | 16 | 427 | 126 | 3x3/,pad=2 | |
| BatchNorm | 16 | 427 | 126 | ||
| 1 | Conv | 16 | 852 | 250 | 7x7/1 |
| Relu | 16 | 852 | 250 | ||
| MaxPooling | 16 | 427 | 126 | 3x3/,pad=2 | |
| BatchNorm | 16 | 427 | 126 | ||
| 2 | Conv | 32 | 423 | 122 | 5x5/1 |
| Relu | 32 | 423 | 122 | ||
| MaxPooling | 32 | 213 | 62 | 3x3/2,pad=2 | |
| BatchNorm | 32 | 213 | 62 | ||
| 3 | Conv | 64 | 211 | 60 | 3x3/1 |
| Relu | 64 | 211 | 60 | ||
| MaxPooling | 64 | 107 | 31 | 3x3/2,pad=2 | |
| BatchNorm | 64 | 107 | 31 | ||
| 4 | Conv | 128 | 105 | 29 | 3x3/1 |
| Relu | 128 | 105 | 29 | ||
| MaxPooling | 128 | 54 | 16 | 3x3/,pad=2 | |
| BatchNorm | 128 | 54 | 16 | ||
| 5 | Conv | 128 | 52 | 13 | 3x3/1 |
| Relu | 128 | 52 | 14 | ||
| MaxPooling | 128 | 27 | 8 | 3x3/2,pad=2 | |
| BatchNorm | 128 | 27 | 8 | ||
| 6 | Conv | 256 | 25 | 6 | 3x3/1 |
| Relu | 256 | 25 | 6 | ||
| MaxPooling | 256 | 14 | 3 | 3x3/2,pad=2 | |
| BatchNorm | 256 | 14 | 3 | ||
| 7 | Fully connected | 1024 | |||
| Relu | 1024 | ||||
| BatchNorm | 1024 | ||||
| Dropout | 1024 | ||||
| 8 | Fully Connected | 176 | |||
| Softmax Loss | 176 |
RNN
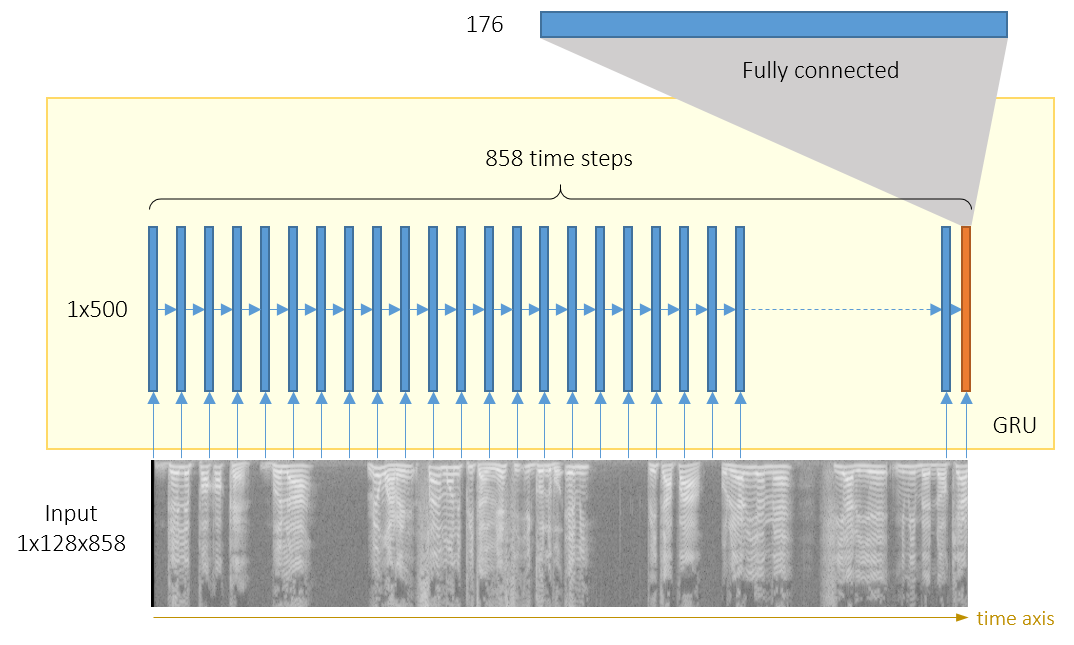
图谱可以看做列向量序列,其中列向量由256(或者128,如果只使用<5.5khz)个数字组成。我们使用了RNN,其中每一层500个GRU Cell,结构图如下:
| 网络 | 准确率 | 注意事项 |
|---|---|---|
| rnn | 93.27 | 在输入层上只有一个GRU层 |
| rnn_2layers | 95.66 | 输入层上两个GRU层 |
| rnn_2layers_5khz | 98.42 | 输入层上两个GRU层,最大频率是5.5khz |
CNN和RNN都在几个epoch中使用了$adadelta$ 参数,然后再使用冲量SGD(0.003或0.0003)。如果从一开始就使用带冲量的SGD,收敛得很慢。带$adadelta$ 的收敛速度会快一点,但是一般不会得到很高的准确率。
结合CNN和RNN
CNN与RNN结合的框架一般是卷积抽取的特征作为输入,RNN作为输出,然后再在RNN的输出之后连接一个全连接层,最后是一个softmax层。
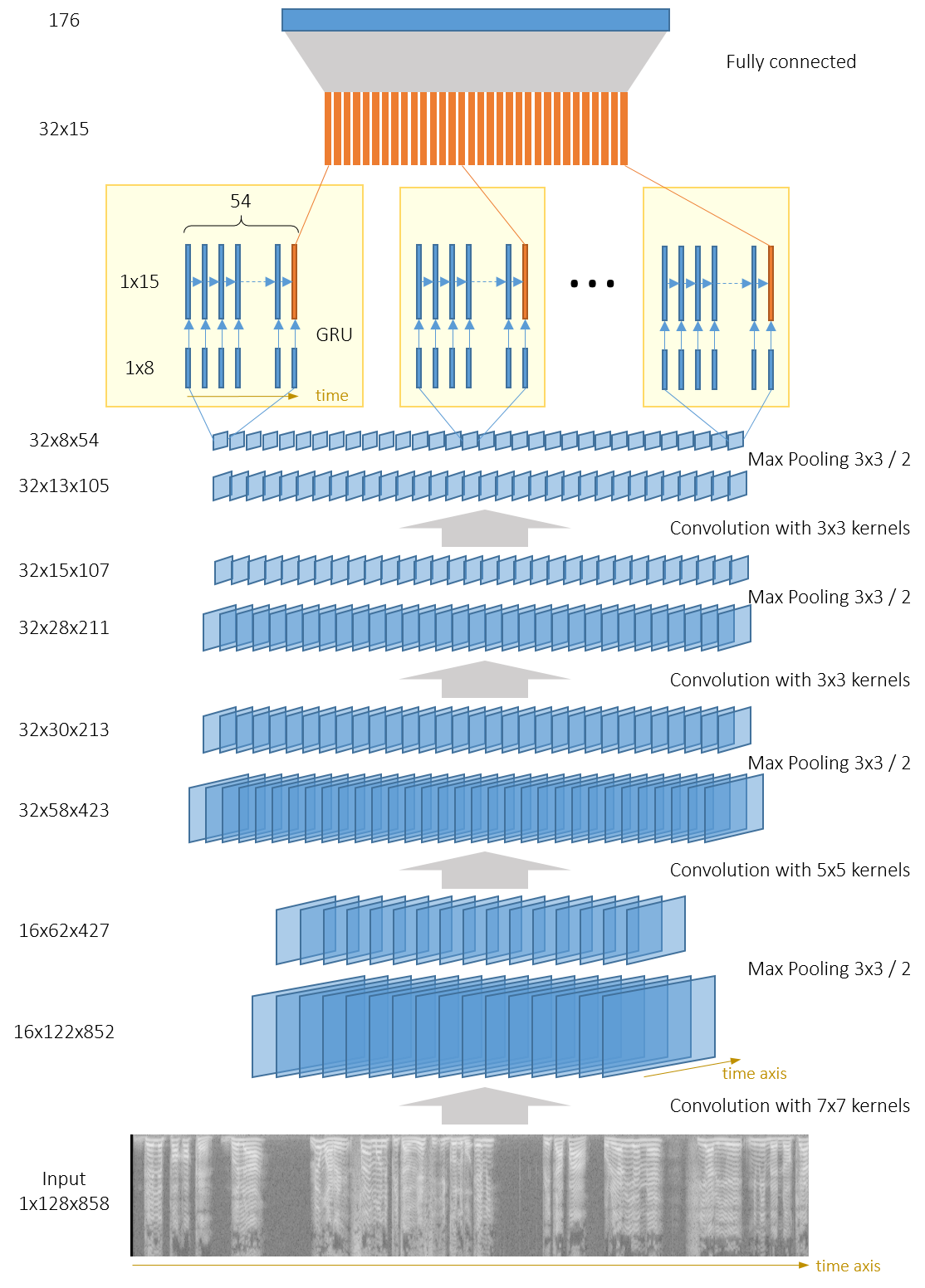
CNN的输出是几个channel(即feature map)的集合。我们可以在每个channel上使用几个独立的GRU(可以使用或者不适用权值共享),如下图:
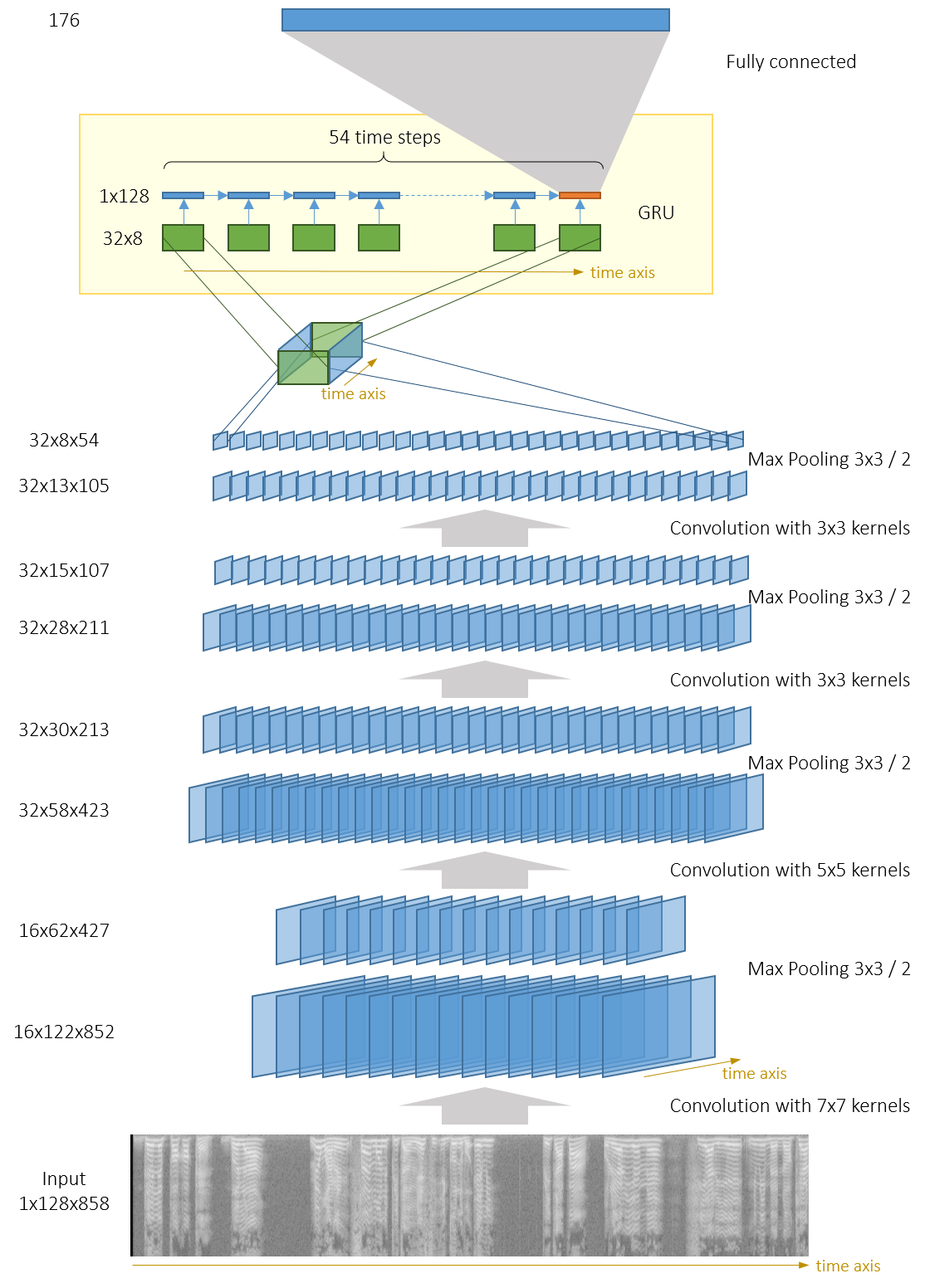
另外一种做法是,将CNN的输出作为一个3D-tensor,然后在那个tensor的2D slice上运行单个GRU。
后一个做法需要更多的参数,但是不同channel的信息会在GRU中混淆,这看起来会提升一点性能。这种架构类似于这篇语音识别论文,除了他们会使用一些从输入到RNN和CNN到全连接层的残差(residual)连接。注意到类似的架构在文本分类上效果较好。
下面的网络对应的代码位于网络
| 网络 | 准确率 | 注意 |
|---|---|---|
| tc_net_rnn | 92.4 | CNN由3个卷积块组成,输出32个channel,尺寸为104x13。每个channel以104个尺寸为13的向量序列输入喂入独立的GRU。GRU的输出会最终融合,然后输入到一个全连接层 |
| tc_net_rnn_nodense | 91.94 | 与上一个网络一样,只是GRU之后没有全连接层,GRU的输出直接喂入softmax层 |
| fc_net_rnn_shared | 96.96 | 与上一个网络一样。但是32个GRU单元之间共享权重,这可用于对抗过拟合 |
| tc_net_rnn_shared_pad | 98.11 | 4个卷积块使用pad=2,而不是ignore_border=False.CNN的输出是32个尺寸为 $54\times 8$的channels。使用32个GRU(每个channel与一个GRU对应),同时共享权重,同时不使用全连接层 |
| tc_net_deeprnn_shared_pad | 96.57 | 4个卷积块与上面的一样,但是在CNN的输出之后使用了2层共享权重的GRU。由于使用了2层,所以过拟合会严重一点 |
| tc_net_shared_pad_agum | 98.68 | 与tc_net_rnn_shared_pad一样,但是网络会在输入上做随机裁剪,并间隔9秒。性能提升了一点 |
| tc_net_rnn_onernn | 99.2 | 4个卷积块的输出被分组为一个 $32\time 54\times 8$ 的3D-tensor,单个GRU运行于54个尺寸为 $32\times 8$的序列上 |
| tc_net_rnn_onernn_notimepool | 99.24 | 与上面的网络类似,但是pool层在时间轴上的步长设为1。因为CNN的输出是32个尺寸为 $852\times 8$的channels |
第二层GRU并没有什么用,因为会产生过拟合。
看起来在时间维度的子抽样并不是什么好办法。在子抽样过程中丢失的信息,被RNN用起来效果更好。在论文文本分类中,作者直接建议所有的池化层/子抽样层都可以用RNN层来代替。本文没有尝试这种方法,不过应该是蛮有前景的。
这些网络都使用了带冲量的SGD。学习率在10个epoches左右时设置为0.003,然后手工缩减到0.001,然后到0.0003。平均大概需要35个epoches来训练这些网络。
Ensembling(集成学习)
最好的单模型在验证集上取得了99.24%的准确率。所有的这些模型做了33个预测(不同的epoches之后,一些模型不止预测一次),我们只是简单的累加预测概率,并获得99.67%的准确率。出乎意料之外的是,其他集成学习尝试,(只是在所有模型的某些子集上集成)并没有获得更好的结果。
最后
这些CNN+RNN混合模型的超参数数量十分之多。受限于硬件,我们只覆盖了很少一部分可能的配置。
由于原始的竞赛是非公开的数据集,所以我们没法发布全部的源代码在Github。
参考: http://blog.revolutionanalytics.com/2016/09/deep-learning-part-3.html