说明
文章来源A Gentle Introduction to Graph Neural Networks
1 引入
将神经网络用于拟合图数据的结构和属性,本文展开了构建一个图神经网络所需组件以及背后的设计思想。
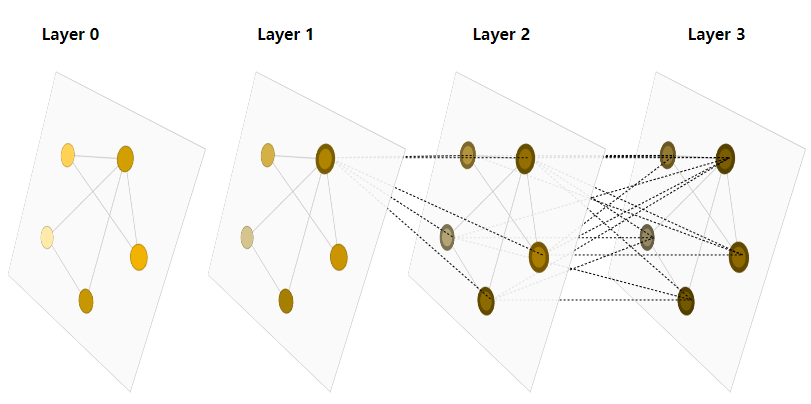
下图展示了一个简单的图,图有4层,每一层都是有5个节点的图。点击某一层的某个节点,会自动显示该节点由上一层哪些节点计算而来。本图中点击的是Layer1中某个节点,会显示它由Layer2中该节点的邻居节点,以及Layer3中邻居的邻居节点共同计算而来。图越深,扩散的点越多。此即为图神经网络如何利用图的结构化信息的。
1.1 摘要
最近的图神经网络有应用在药物发现,物理模拟,虚假新闻检测,车流量预测,推荐系统。
本文将阐述如下四块内容
- 什么数据可以表达成一张图,以及一些常见实例
- 图跟其他数据的区别,以及为何一定要用图神经网络而非CNN等
- 如何构建一个GNN,并展示GNN各个模块内容
- 提供一个GNN的playground,供用户探索真实世界中的数据
1.2 什么是图
图是表示实体(节点 node)之间关系(边 edge)的。如下图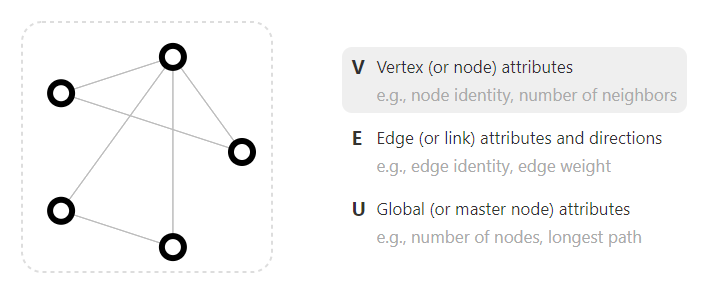
为了进一步描述这些节点、边或整个图,我们需要存储图中的所有要素信息。下图是一种将节点、边和整个图用embedding的方法表示出来的示例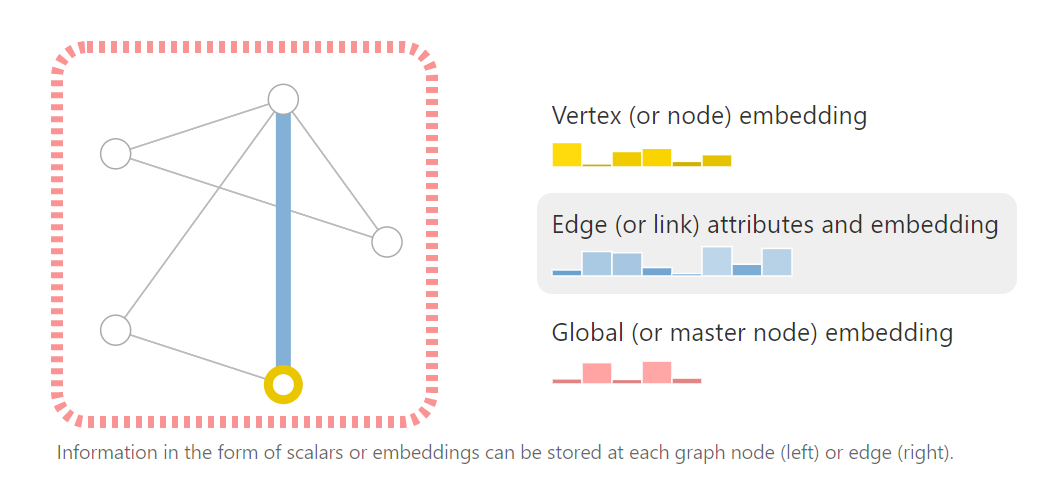
2 图的分类以及如何将数据表征为图
可能你对一些图数据有所了解,比如社交网络等。但是图本身是一种强有力的数据表征方式,有两类数据可能你没想过会用图数据来表示: 图像和文本。
2.1 图像表示为图
通常我们将图像认为是一种带通道的矩形格字,将其表示为数组,比如$224\time 224 \times 3$。另外一种看待图像的方式是将图像视为某种有规则结构的图,其中每个像素代表一个节点,邻接像素视为边。每个非边缘像素都有8个邻居,每个节点存储的信息是一个三维向量(即像素的RGB通道)。
可以通过图的邻居矩阵来可视化其连接性。将节点排序,然后将每25个像素划分为一个$5\times 5$的小方格(下图左图),并填充一个$n_{nodes}\times n_{nodex}$的矩阵(下图中间图),填充规则是:如果两个节点共享一条边的话则填充蓝色格子,否则不填充(白色)。下图三种方式表示的都是同一个图像的数据。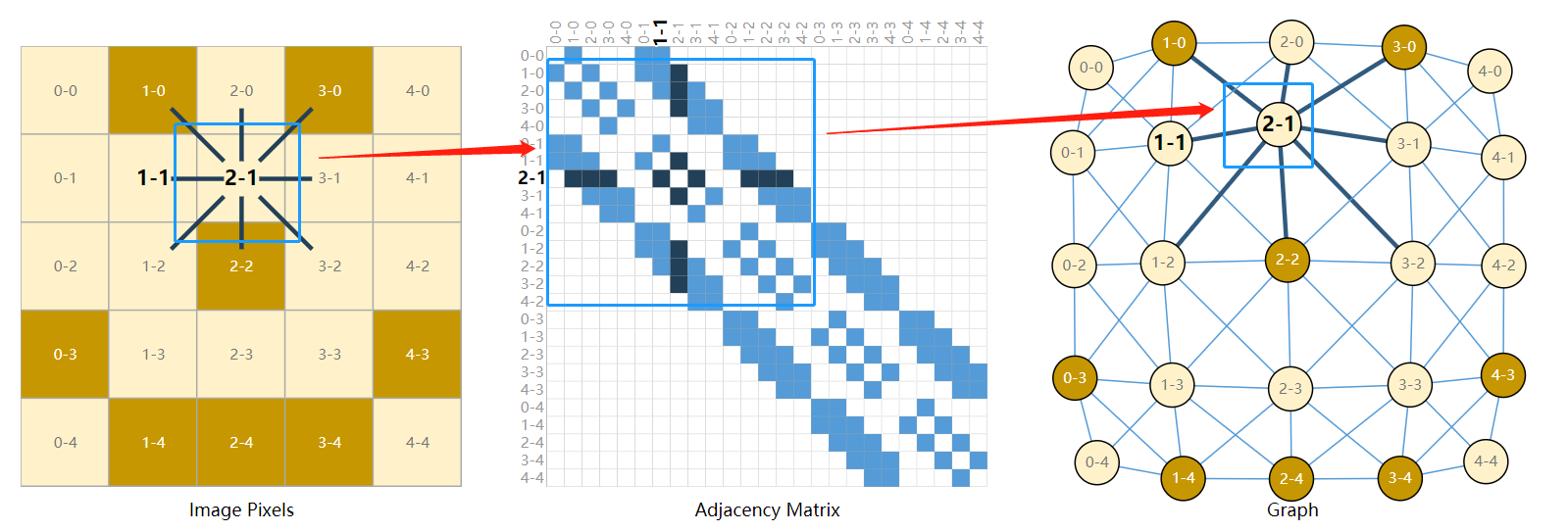
2.2 文本表示为图
可以通过将每个字符串、词或token,用其序号来代替,进而将文本表示为这些序号的序列。这就创造了有向图,其中每个字符串或其索引都是一个节点,然后会与下一个字符串之间有一条边相连。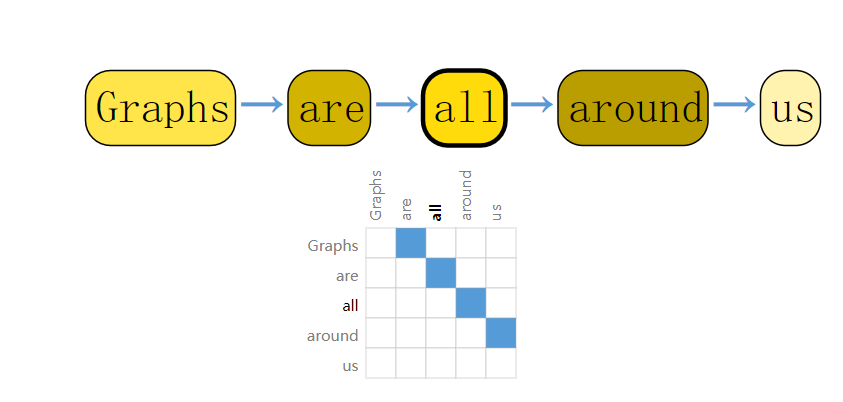
当然,现实场景中不会这样来对图像和文本编码:这些图表征过于冗余,因为图像和文本都是规整结构的。例如图像的邻接矩阵有带状结构,因为所有的节点(像素)在网格中都是相连的。
2.3 现实生活中的图数据表示
2.3.1 分子表示为图
下图为一个香料分子表示为图,里面是一个原子通过作用力连接在一起。每个原子为一个点,如果原子之间相连则有一条边
2.3.2 社交网络图
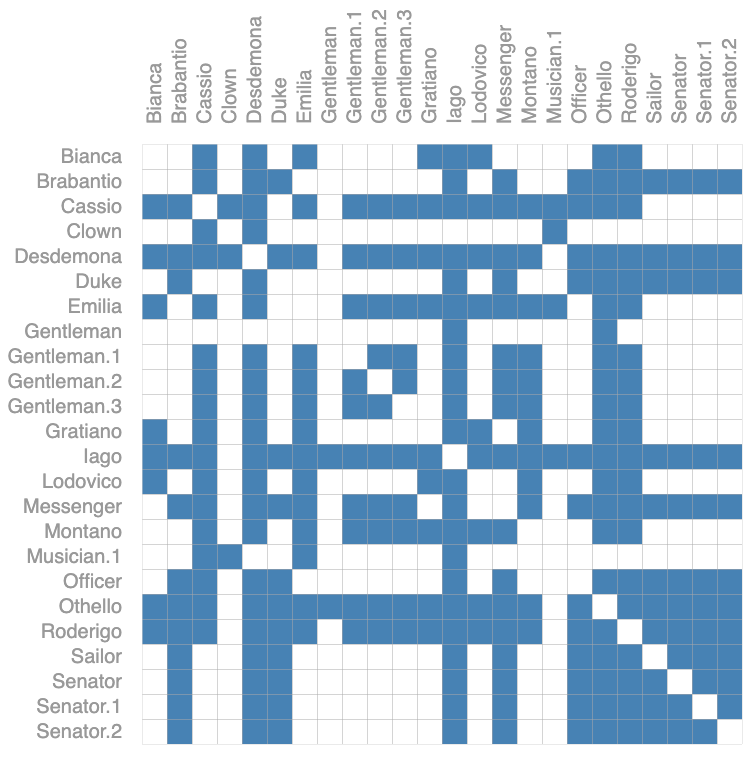
社交网络中可以将人或组织表示为节点,关系表示为边。下图为歌剧 奥赛德中人物之间的交互图。图中任何一个人物如果在某个场景中同时出现则连接一条边。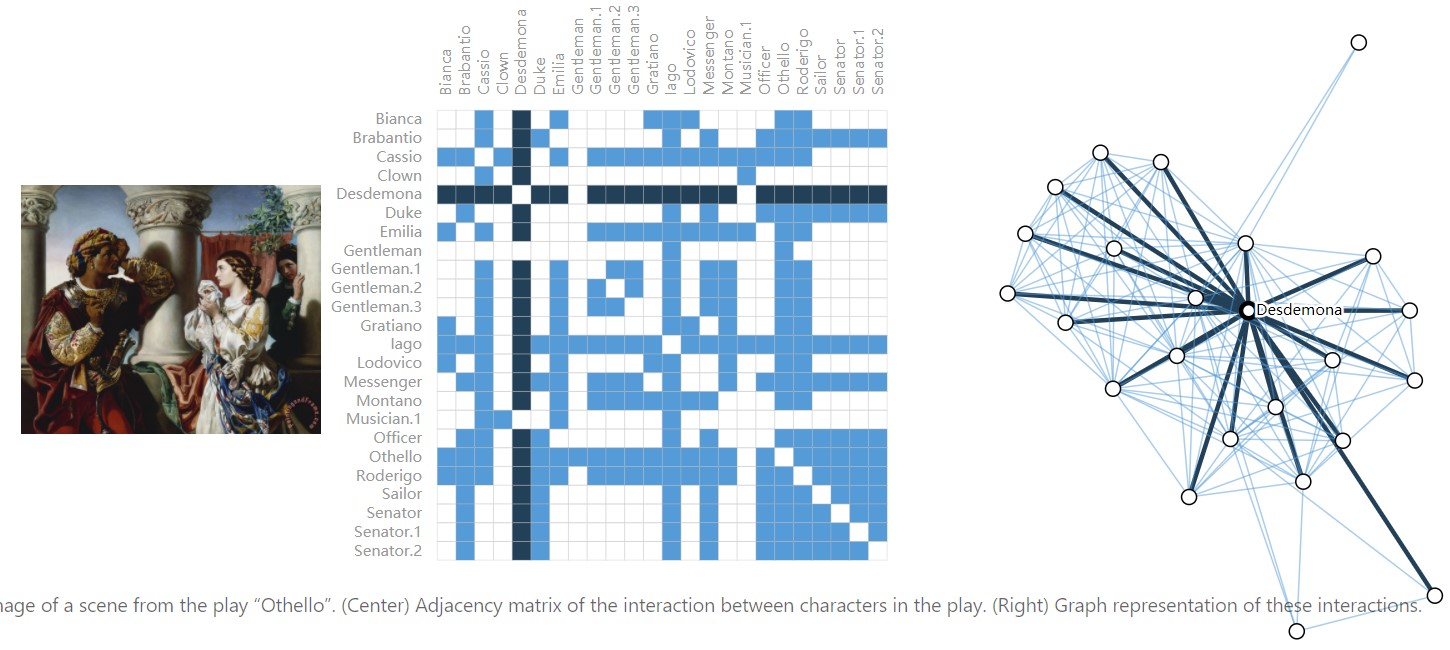
如图中Desdemona这个人物基本上跟所有人都共同出现在某个场景里,邻接矩阵第5行基本都填满了。与图像和文本数据的图的邻接矩阵不同,社交网络没有完全相同的邻接矩阵。
下图为一个空手道俱乐部的关系网络图,每个老师会跟一些同学做比赛,如果老师有给某个同学做过比赛,则会产生一条边。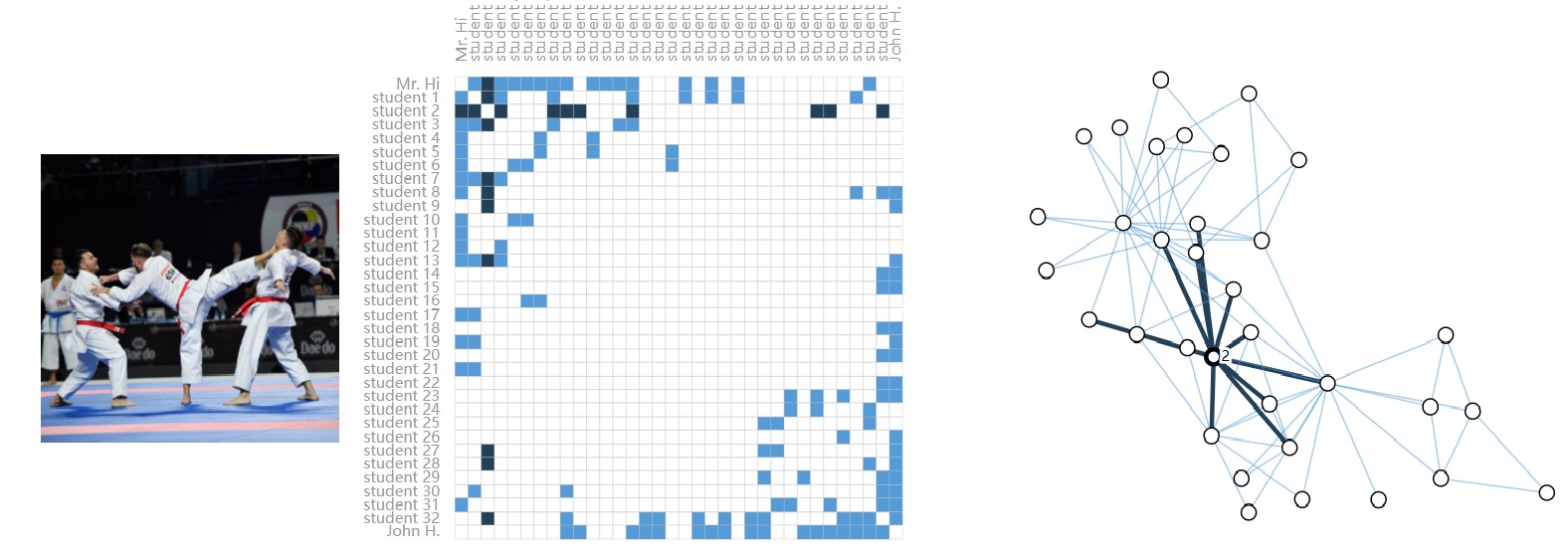
2.3.3 引用图
如果某一篇文章引用了另外一篇,则会有一条边,这是一个有向边。
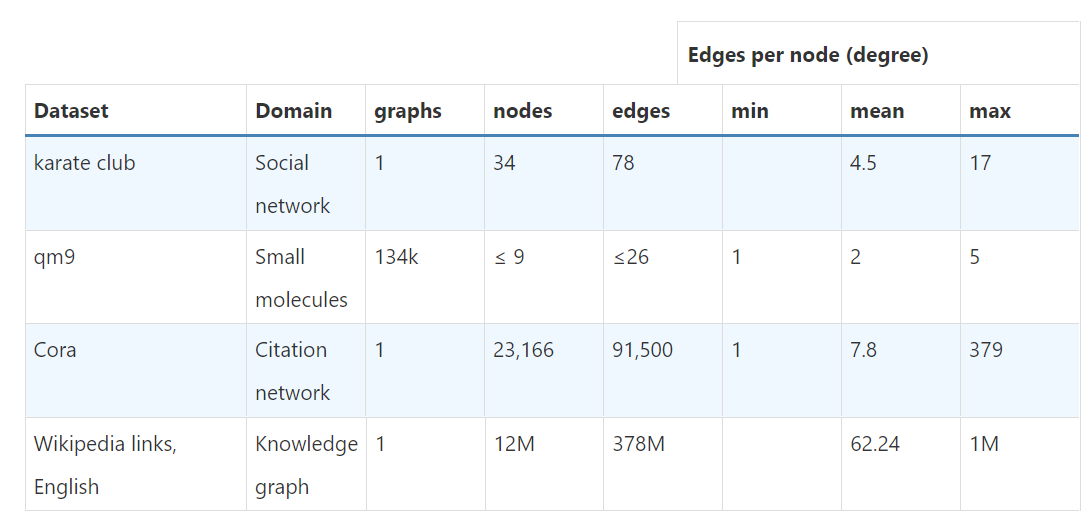
2.3.4 其他图的简单总结
下图总结了一些经典网络图的总结,包括领域、节点数、边数、节点最大、最小、平均度数。
第一个就是上一节中的空手道俱乐部图。
3 可以在图上定义哪些问题
主要有三大类问题
- 图层面的: 对整张图的某个属性做预测。
- 节点层面的: 对图中每个节点的属性做预测
- 边层面: 对图中每条边做预测
记下来分别研究这三种层级的问题
3.1 图层面的任务
如下图,左侧为原始图集合,我们需要识别图是否包含两个环
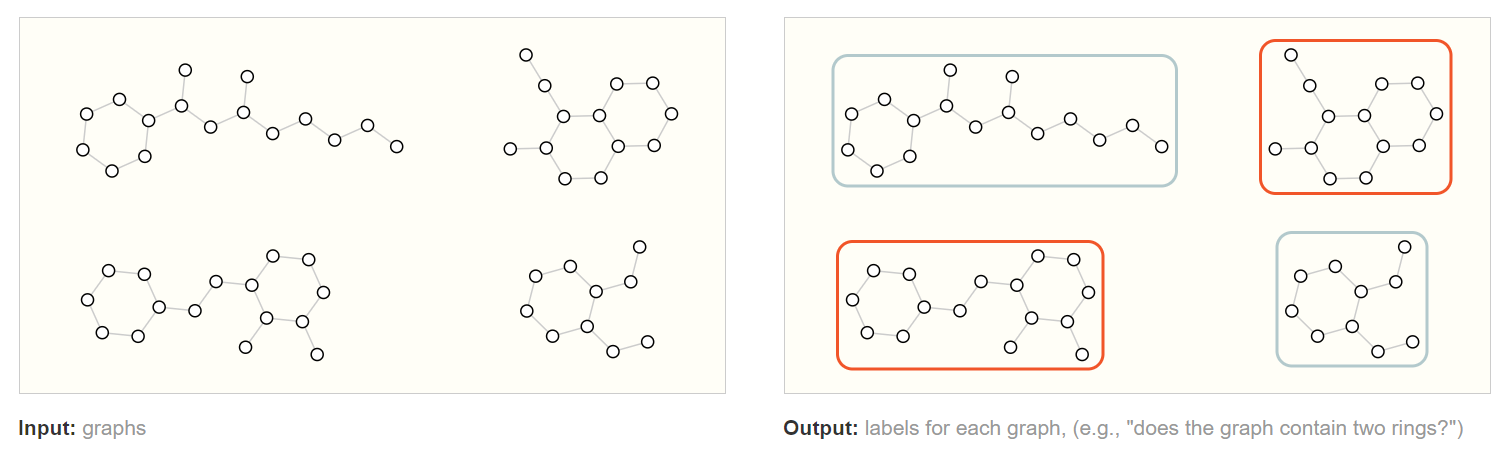
红色框的图为包含了两个环的,灰色的没有。
这一点与图像分类任务,如MNIST和CIFAR图像数据,希望对某个图整体做一个分类。在文本相关任务中类似的问题是为语义分析,需要对一个句子的整体的情感分类。
3.2 节点层面任务
前面的示例图中的空手道俱乐部图中,有两个老师给学生做比赛,后来两个老师(下图中的John A和 Mr.Hi)出现分歧,所有的学生需要选边站。此时需要根据历史的社交网络图,对某个节点(学生)的选边做预测,他是站John A(蓝色) 还是 Mr.Hi(红色)。
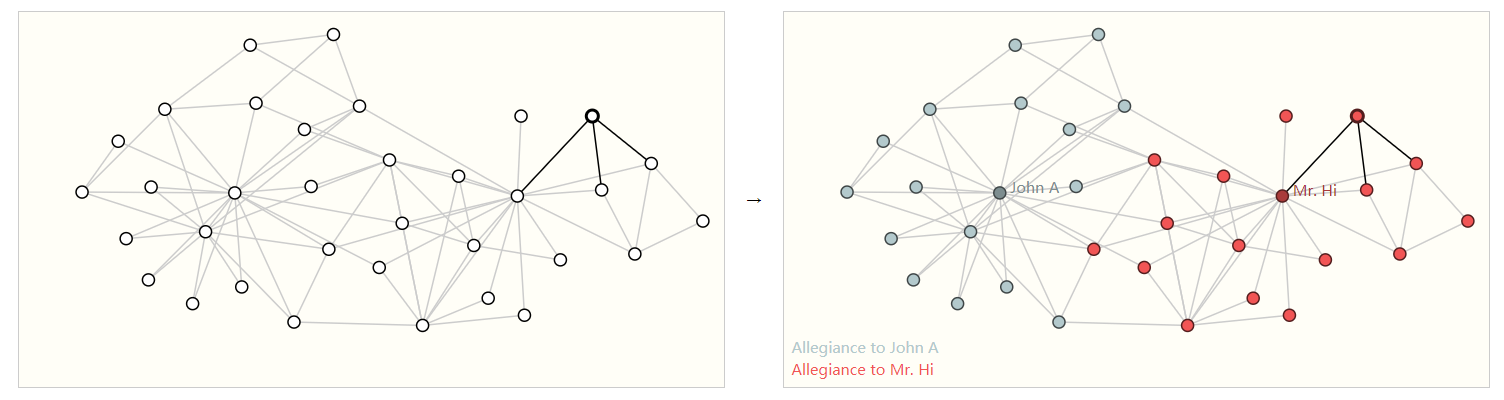
与图像对比,节点层面的预测任务类似于图像任务中的分割,即对每个像素点预测其标签。
3.3 边层面任务
一个示例是图像场景理解。如下图中,先用语义分割,将图片中的人物和背景都提取出来,然后预测人物之间的关系。此时人物之间的关系的预测就是用图算法对边做预测。
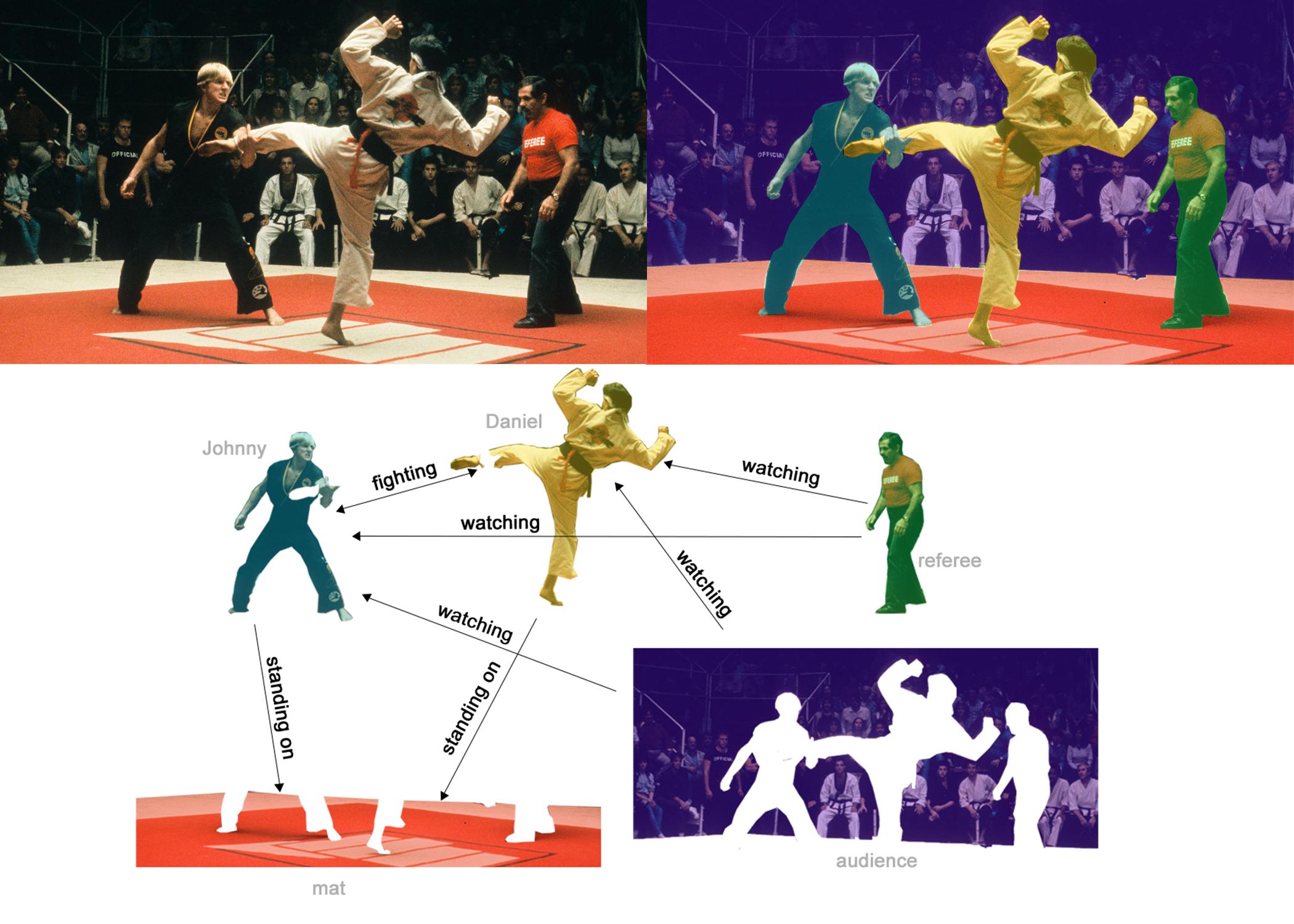
从图中下半部分可以看出各类边的关系描述
- $Johny \stackrel{Standing On}{\longrightarrow} 地板$
- $Johny \stackrel{fighting}{\longrightarrow} Daniel$
- $referee \stackrel{watching}{\longrightarrow} Daniel$
- $audience\stackrel{watching}{\longrightarrow} Daniel$
下图中左边的图是从图像中做语义分割拿到的图数据,右边是用图模型对此图对应的边描述预测。
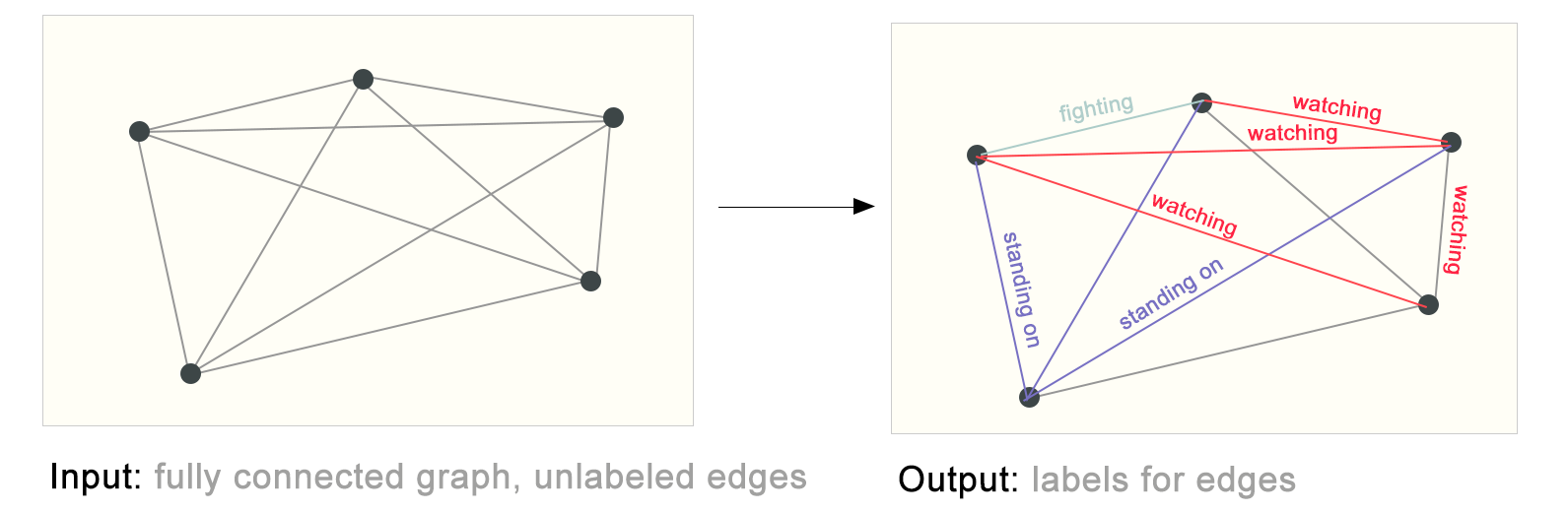
4 机器学习(主要是神经网络)中使用图时的一些挑战
首先要考虑的一个核心问题是,如何将图数据表征成与神经网络相兼容的。
图中有四类信息:图,边, 节点,连接性,前面3个都可以用向量来表示。例如节点可以形成节点特征矩阵$N$,给每个节点一个序号$i$,然后在该位置保存该节点的特征即可。
此外,表示图的连接性显得更加复杂。首先想到的是使用邻接矩阵,但是这种方案有以下问题
- 稀疏矩阵: 图中节点的数量可能是百万级别,比如维基百科的1200个节点网络,同时每个节点相关的边也是千变万化的。虽然可以可以使用稀疏矩阵存储数据,但是无法高效计算稀疏矩阵,特别是将稀疏矩阵放在GPU中计算。
- 相同的连接性可以表示成多种不同形式的邻接矩阵,但是这些不同的矩阵是否能经过神经网络产生相同的结果无法保证(即这些矩阵不具备置换不变性)。
例如前面提到的奥赛德歌剧图中,可以用两个不同的邻接矩阵来表示,完全不影响
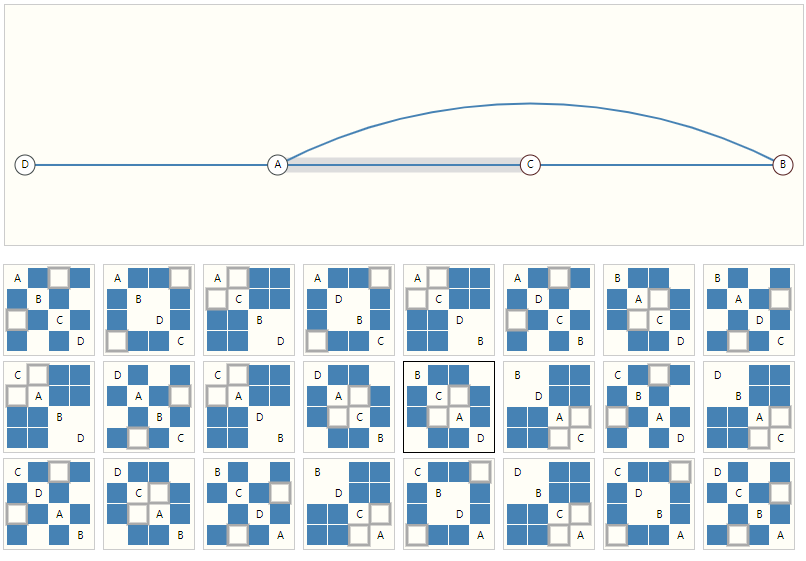
下图展示一个包含了4个节点的简单的图,但是其邻接矩阵可以有24种,可以想象稍微大一点的图其邻接矩阵变化量无法估算。
一种省内存的表示稀疏矩阵的方式是将邻接矩阵表示为边列表。将节点$e_i和n_j$之间的边$e_k$表示为一个元组,在邻接列表的第k个位置。这种存储可用节省内存,并且无视边的顺序。改变边的顺序时,将相应的邻接列表的顺序也改变即可。
为了比邻接矩阵的方式存储($n^2 _{nodes}$)省内存,我们需要避免计算和存储图中不相连的部分。如下图为一个简单示例
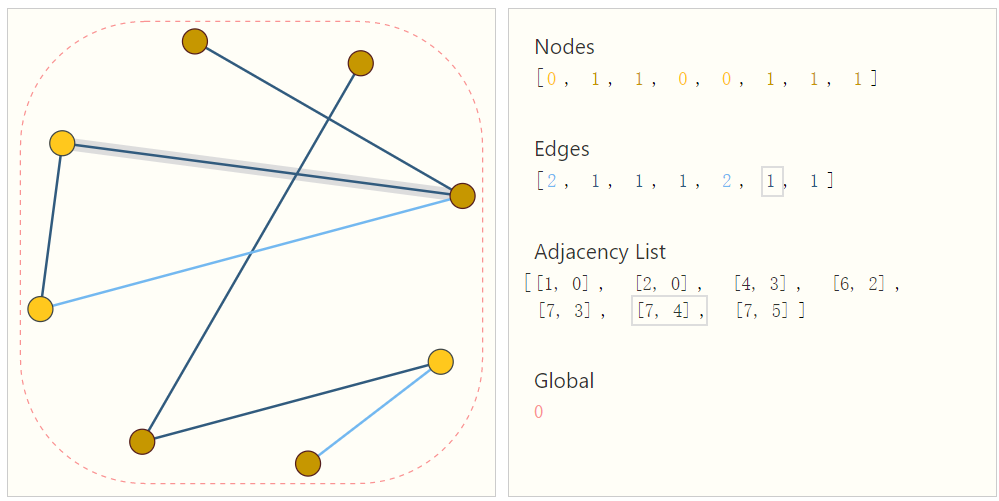
图中每个节点/边/全局信息都是用标量表示的,但是大部分实际场景下都是用向量。
4 图神经网络
GNN是一个对图上所有属性(包括顶点、边和全局上下文)进行一个可以优化的变换,这种变换可以保持图的对称信息的。GNN是一种信息传递框架,其输入是一个图,输出也是一个图,它会对图中所有属性做一些变换,但是不会改变图的连接性。
4.1 最简单的GNN
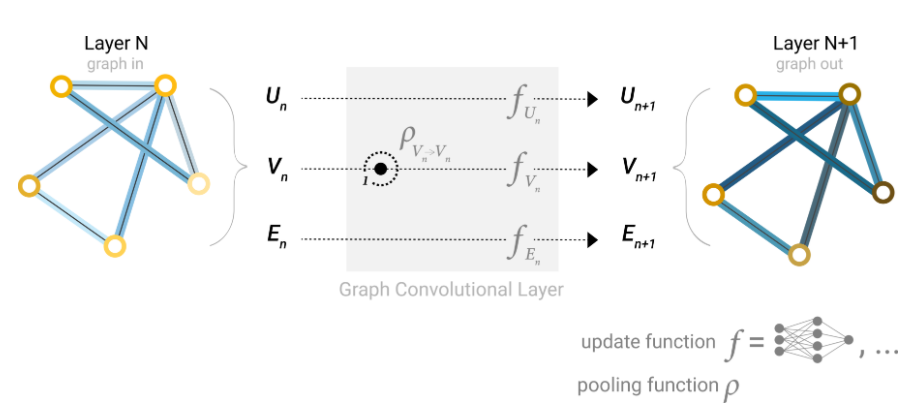
分别对节点向量,边向量,全局向量分别构建一个MLP(多层感知机),感知机的输入输出大小一样。然后这三个MLP(下图中全局MLP($f_{U_n}$),边MLP($f_{E_n}$),节点MLP($f_{E_n}$))构成了GNN的一层。
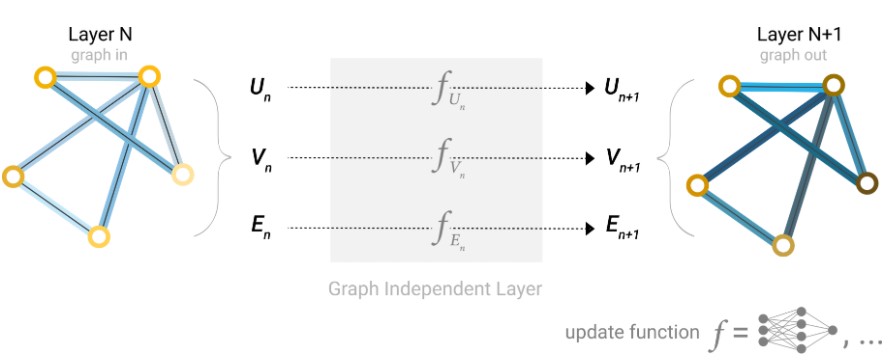
这一层GNN的输入是一个图,输出也是一个图。其对于节点、边、全局的向量,分别找到对应的MLP,将向量数据输入然后得到输出,作为对应的更新。图的属性被更新,但是图的结构没有发生变化。
4.2 GNN如何输出预测
假设一种简单的场景,对节点做二分类预测。每个节点都有了对应的向量表示,对每个节点embedding信息应用一个线性分类器即可。
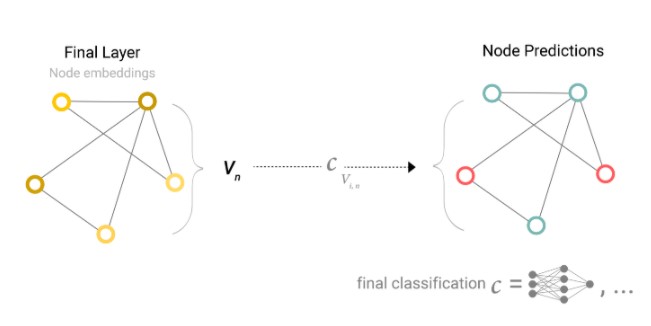
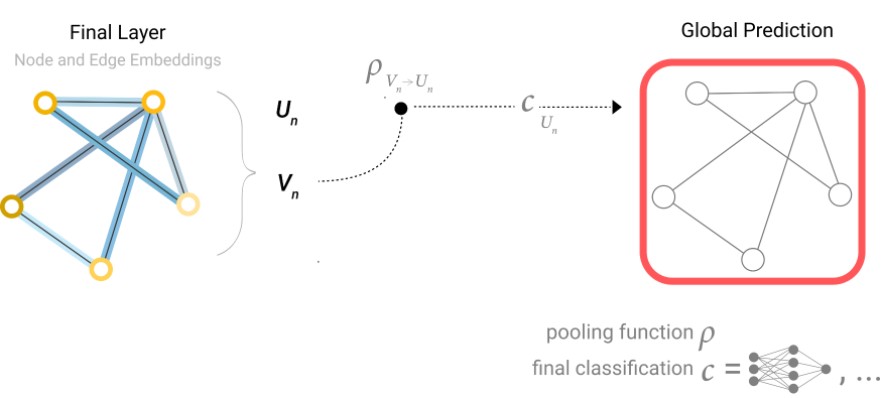
但是有些时候,一些复杂的场景。比如图中只保存了边的信息,但是没有节点信息,但是仍然需要对节点做预测。此时需要某种方式从边集合里面抽取数据用来对节点做预测。我们可以使用pooling.Pooling过程分为两步
- 对每个需要pool的数据项,拼接每个项的embedding然后组合成一个矩阵。例如节点$A,B$的embeding向量分别为$ A=[0.25,0.302,0.211],B=[0.102,0.45,0.105]$,那么拼接后的矩阵为$C=[[0.25,0.302,0.211], [0.102,0.45,0.105]]$
- 对组合的embedding结果做聚合,一般是累加和。例如上面的向量C做累加和之后变成了$C^*=[0.25+0.102,0.302+0.45,.0211+0.105]=[0.352,0.752,0.316]$
通常以字母$p$代表pooling操作,从边向节点聚合数据的操作表示为$pE_n\rightarrow V_n$
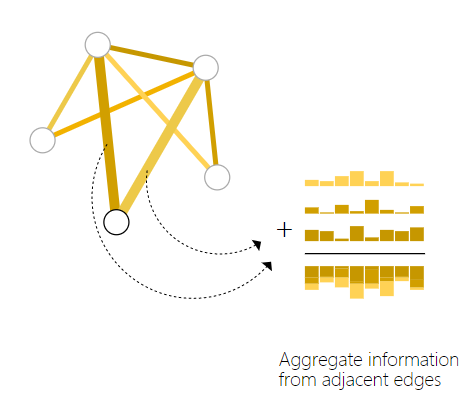
如上图节点,有两条相关的边,在右侧做聚合。右侧有四行,上面三行包含两条边的向量表示和图的全局向量表示,最后一行为最终的聚合向量结果。
4.2.1 只有边特征,对节点特征做预测
如果我们仅有边层面的特征,需要对节点信息做预测,使用pooling汇聚数据 模型的示意图如下:
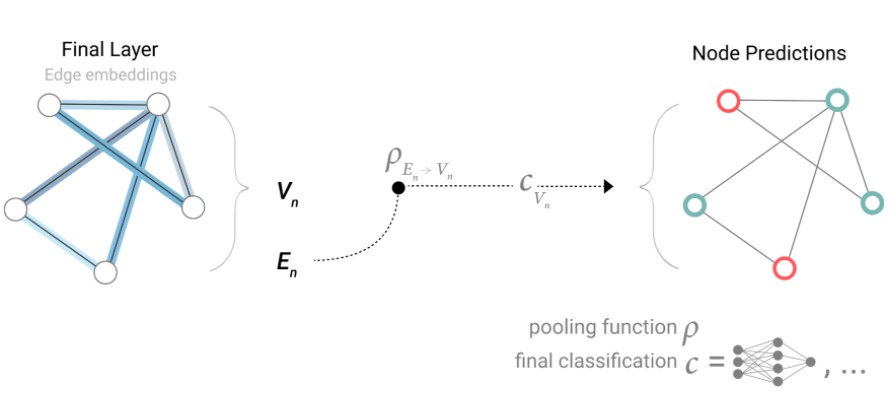
只有边信息$E_n$,没有节点信息$V_n$,此时通过边的信息pooling汇聚$P_{E_n\rightarrow V_n}$,得到节点向量特征,再将数据传入节点之间共享的输出层,得到节点输出。
4.2.2 只有节点特征,对边特征做预测
同样的,假设只有节点向量信息,没有边的向量,但是需要对边做预测的话,也是通过边的两个节点信息做pooling汇聚,再进入边的输出层,得到预测
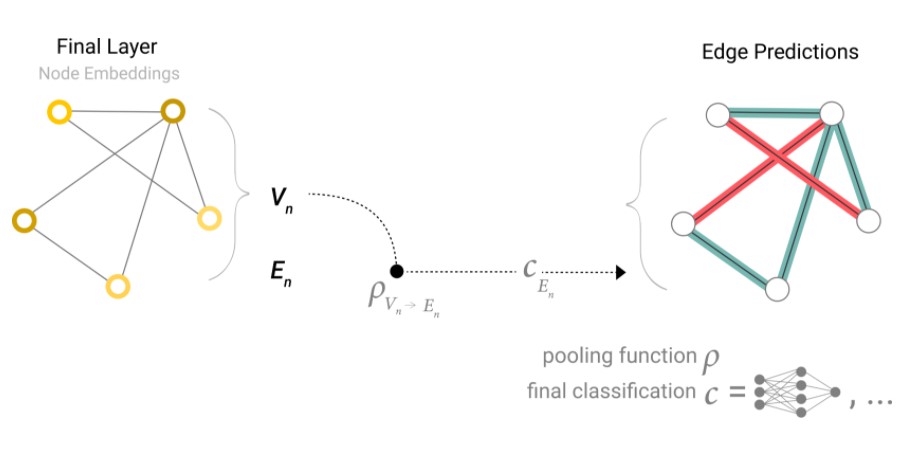
4.2.3 只有节点特征,对全局图预测
可以将所有的节点向量特征pooling汇聚,这一点类似CNN中的全局avg pooling。然后将数据传入到图的输出层。
4.2.4 总结
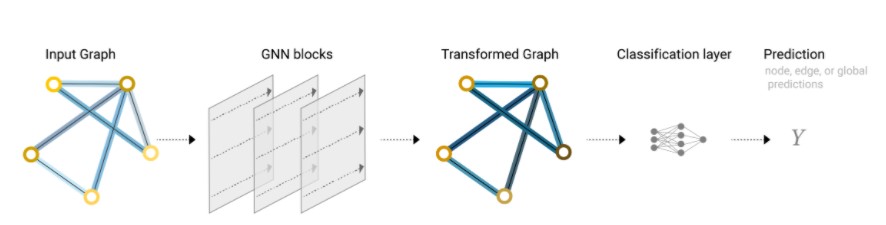
最简单的GNN如下:
给定输入的图(Input Graph),首先进入一层或多层的GNN层(GNN blocks),每一层都有3个MLP,分别对应节点、边、全局的特征的处理,最后输出是一个保持了整个图结构的输出(Transformed Graph),但是其中图中所有属性已经发生了变换。最后对于需要做预测的属性,添加输出层(Classification layer),如果中间缺失某些信息,可以添加汇聚Pooling层,就可以完成预测(Prediction)。
局限性
- 上面的GNN层并没有使用图的结构信息,即只是单独的将每个属性(节点、边、全局)传入到对应的MLP做变换,没有关联节点和边,没有考虑连接信息。导致最终的结果没有充分利用数据。这一点可以使用后面介绍的信息传递技术
4.3 图的各个部分的信息传递
为了让学习到的embedding感知到图的连接性,可以在GNN层内通过pooling做一些随机预测。邻居节点或边交换信息并彼此影响embedding更新的过程可以用信息传递来完成。信息传递分为三步
- 对图中每个节点,集合所有邻居节点的embedding信息,这里的集合可以是前面的向量拼接
- 通过比如求这种聚合操作来聚合所有embedding信息
- 所有聚合完的信息输入到一个更新函数中,通常为一个训练好的神经网络。
正如可以对节点或边做pooling,信息传递也可以出现在边或节点上。这些都是让embedding能拟合图的连接性的关键步骤。
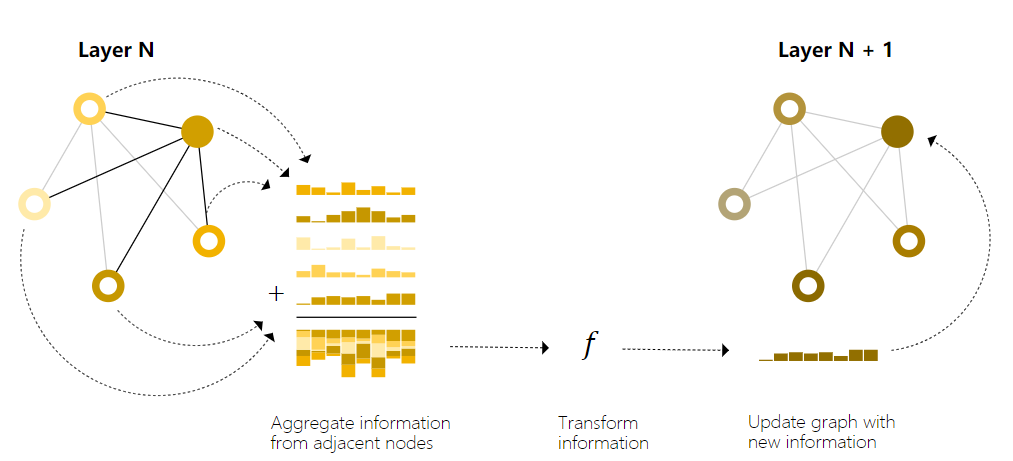
如上图中,我们在计算选中节点embedding信息时汇聚了全部的4个邻居节点,一共5个节点的embedding信息先做汇聚pooling再进入f函数,f函数的输出用来更新选中节点的embedding信息。
这个步骤与图像卷积CNN很像,但是在CNN中相邻像素(比如 $3\times 3$的窗口)都有自己单独的权重,而这里节点邻居的权重全部都是相同的,直接累加。CNN中有多个输入和输出通道,这里相对应的就是MLP过程。
通过堆叠多层GNN层,GNN多层之间有信息传递,一个节点可以最终瞥见整个图的概要信息。即,每个节点只考虑其邻居节点信息,多层堆叠之后,最后的一层的节点可以感知到邻居的邻居的邻居的信息。这样就完成了图的长距离信息传递。
此时我们可以将前面的GNN架构图更新如下
4.4 学习边表征
数据集可能不是永远都有所有类型的信息(节点、边和全局信息)。如果我们只有边信息,如何去预测一个节点,上面展示了如何通过节点相关的边的信息汇聚pooling达成,但是那只是在模型的最后预测阶段。我们可以通过信息传递在GNN层内的边和节点之间共享信息。
我们可以像上面提到的使用邻居节点信息这种方式,合并邻居边信息:首先,pooling汇聚边信息,经过函数转换,然后更新信息,再存储。
下图展示了这个过程,其中节点信息$V_n$将其信息传递到边$E_n$,再将信息从边传递到节点上
- 首先通过一个$\rho_{V_n \rightarrow E_n}$把节点向量传递给边向量(每条边把其连接的两个节点信息加到边自己的向量中,如果边向量和节点向量是相同维度的话,直接相加即可,如果不一致,则需要做一次投影变换)
- 同样的,每个节点也可以将关联的边的向量相加,加到节点自身向量上。如果有维度问题做投影即可。
下图展示的 节点 $V_n \rightarrow 边 E_n$和$E_n \rightarrow V_n$分别做了两次投影$\rho_{V_n \rightarrow E_n}$和$\rho_{E_n \rightarrow V_n}$
完成上面的信息汇聚之后,再对边和节点做各自的MLP更新$f$
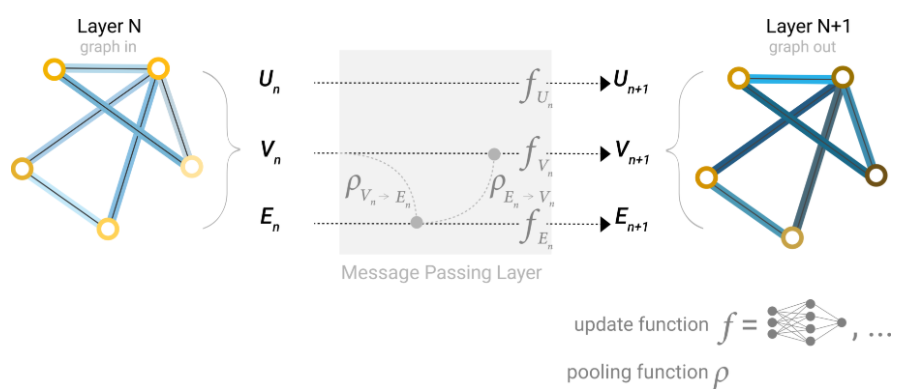
下图左图展示的是从节点$V_n$信息传递到边$E_n$,右图是从边$E_n$传递到节点$V_n$。这在之前信息更新的先后顺序是无关紧要的,因为节点和边之间不交换信息, 但此时有做信息交换,信息更新顺序会影响结果,但是哪种更新顺序,目前没有统一结论孰优孰劣。
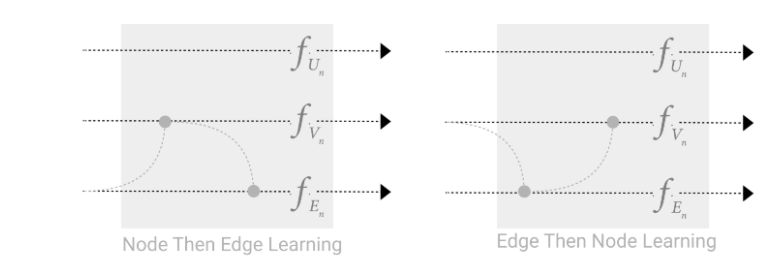
作者认为不如交替更新,同时做节点汇聚到边和边汇聚到节点,单次汇聚后向量暂不相加,交替之后再相加。
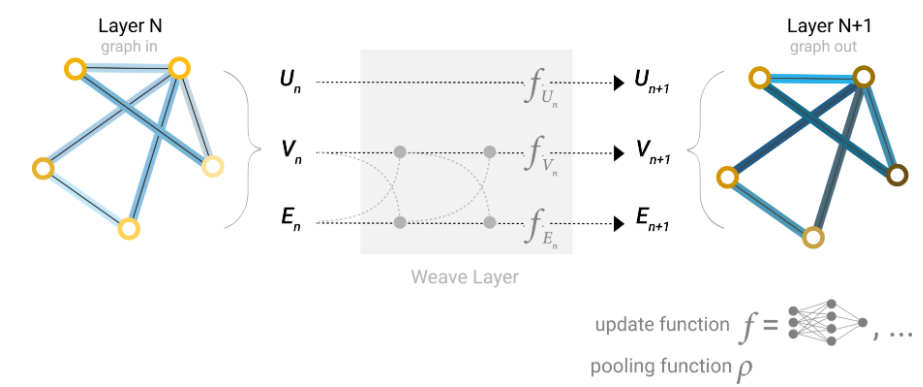
4.5 加入全局信息表征
在图较大并且连接稀疏时,远距离节点之间信息传递需要走很长的步。作者的解决方案是加入一个称之为 master node或 context verctor的虚拟节点,该节点可以跟所有节点相连,也跟所有边相连,表示为$U_n$。
此时如果想汇聚节点或边的信息,会自动汇聚虚拟节点$U_n$
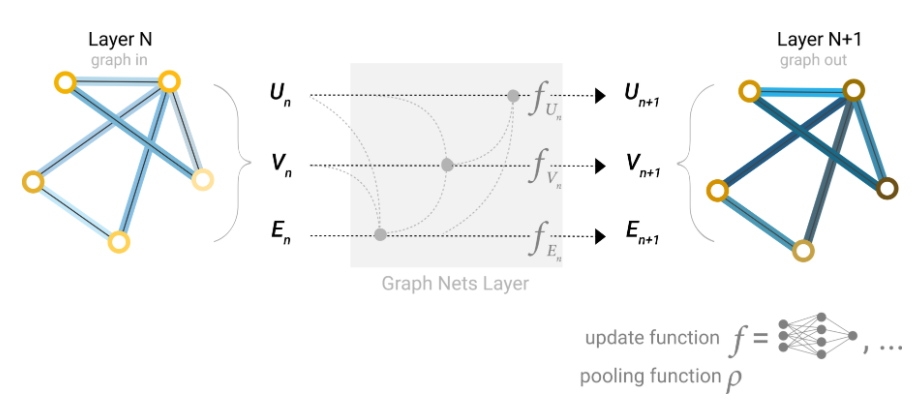
截止当前,已经获得图的所有属性(节点、边、全局)的向量表征,并且这些向量在前期已经做了大量信息传递,最终做预测时可以只用本身的向量或再加上相连边向量或再加上全局向量,一起做预测。所有的这些属性可以直接相加或者拼接起来,这个过程类似attention 机制
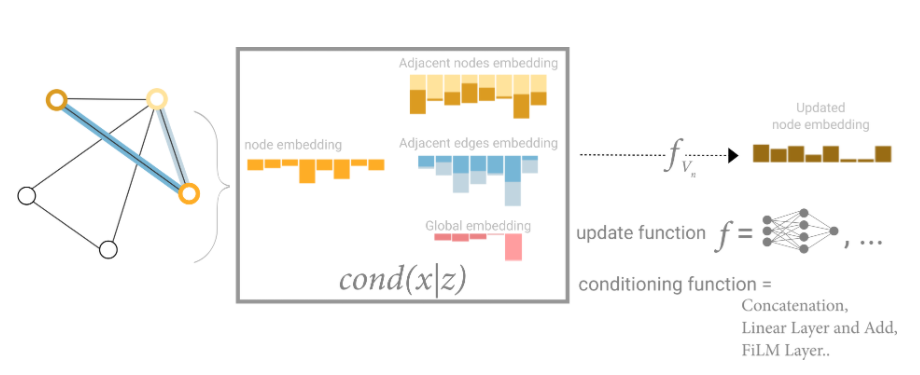
5 GNN Playground
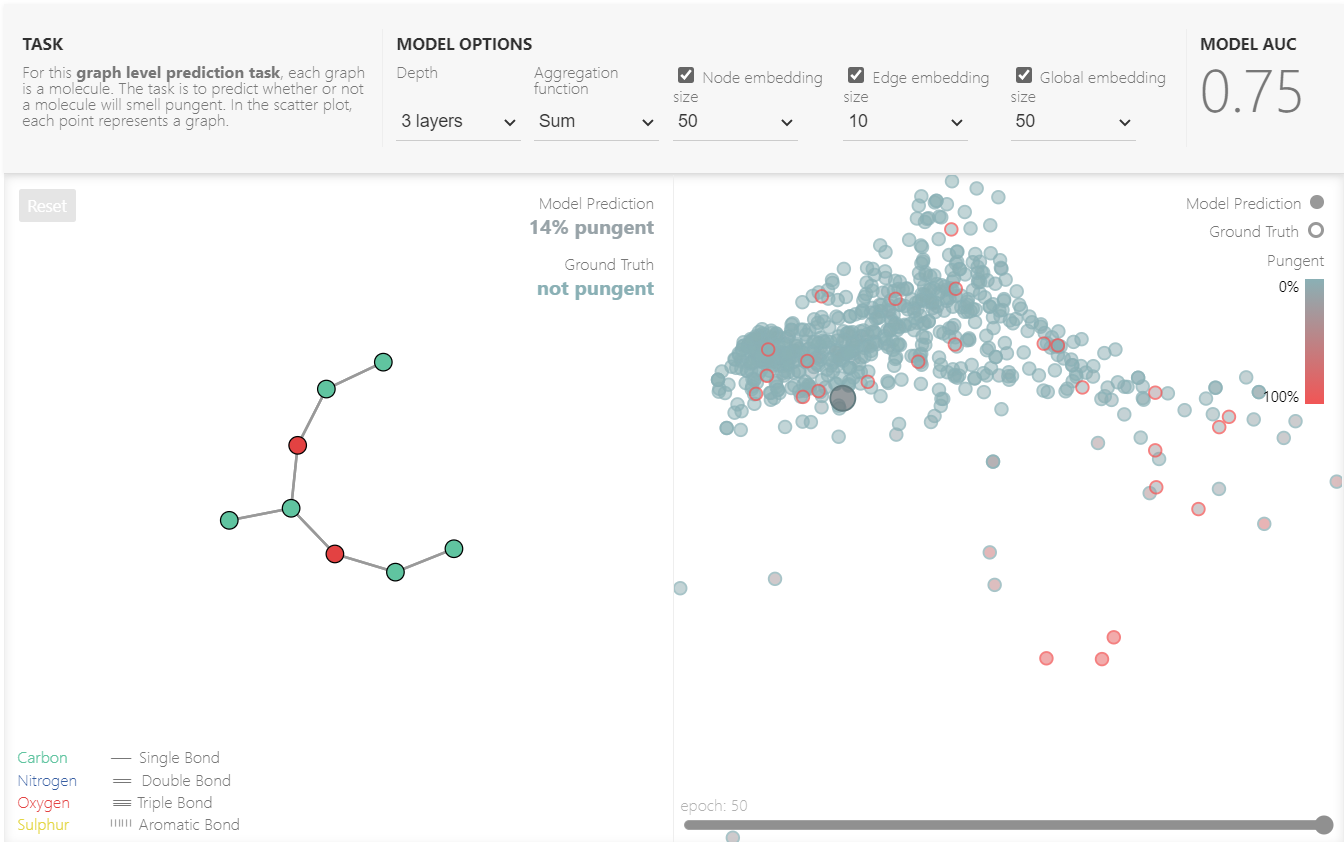
在原文网页中,作者把GNN训练程序嵌入到网页里面,可以自由调节参数并做可视化训练。示例的是一个小的分子图预测任务,可以调节网络层数,聚合函数,节点emebdding的维度,每次调节参数后会立刻给出模型的评估结果AUC.图中右侧是对所有数据点的预测,节点真实标签以节点边框标识(边框有两个颜色:红色和蓝色),预测值为内部实心颜色,如果节点的边框和实心颜色统一,那么预测正确,否则预测错误。
5.1 一些对模型影响的超参数
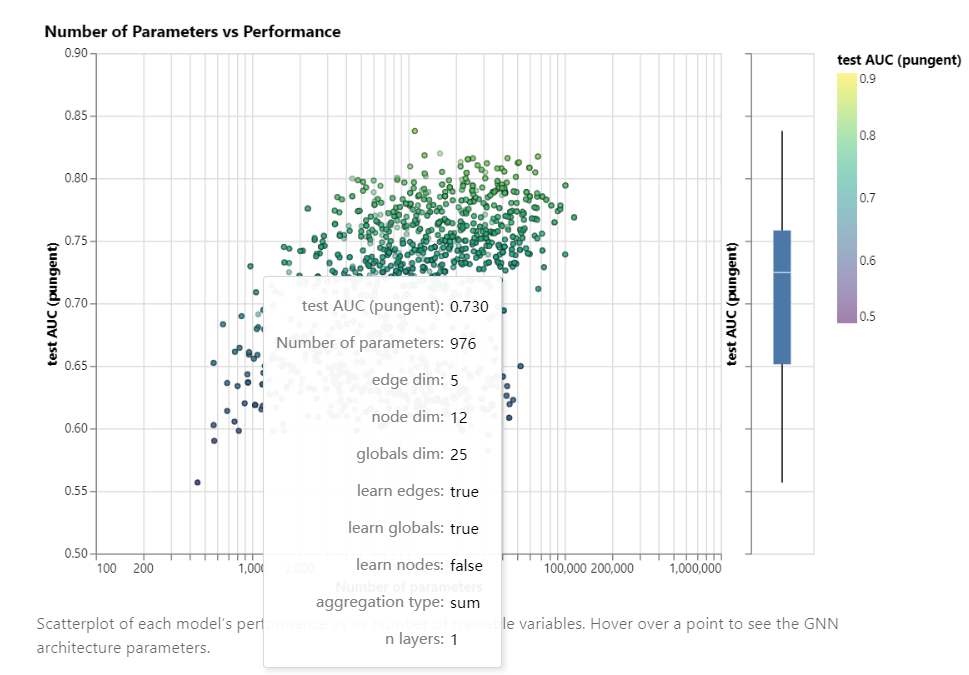
模型可以学习的参数的大小和最终测试AUC之间的关系,下图中每个点对应了一个特定超参数在模型上训练得到的结果,x轴为超参数个数(越往右超参数越多),y轴为测试集的AUC(越大越好)。整体来看,超参数增加时,模型AUC上线变高。
接下来单独看每个超参数对模型影响
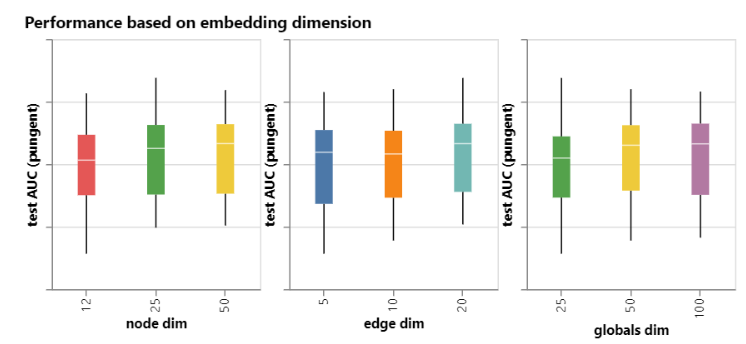
- 每个属性向量embedding长度,下图从左向右分别展示了
节点,边,全局做embedding向量维度变化与AUC关系的盒图。其中维度从12边为25时AUC中值有所提升,但是从25变为50提升不明显。
- GNN层数影响:下图展示的是X轴为可学习参数数量,Y轴为AUC,右侧4根盒图代表了层数由1增长到4时模型AUC统计结果,可以看到层数为1时AUC中值较低,左侧也可以看到红色点集中在左下测。当层数增加时,AUC中值在增加。
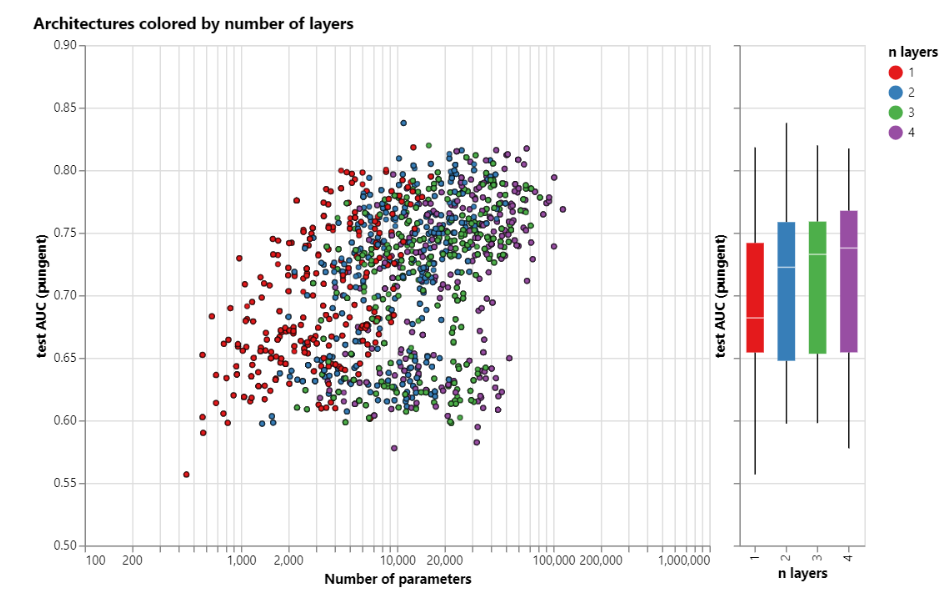
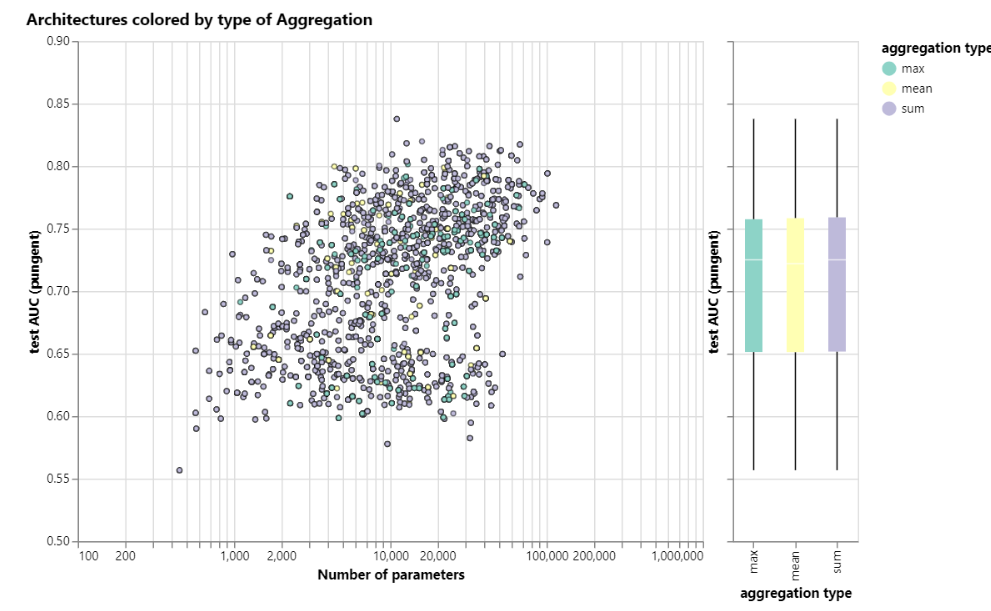
- 不同聚合操作的影响。即属性(节点、边或全局)的向量聚合,从图中看到,基本没差别。
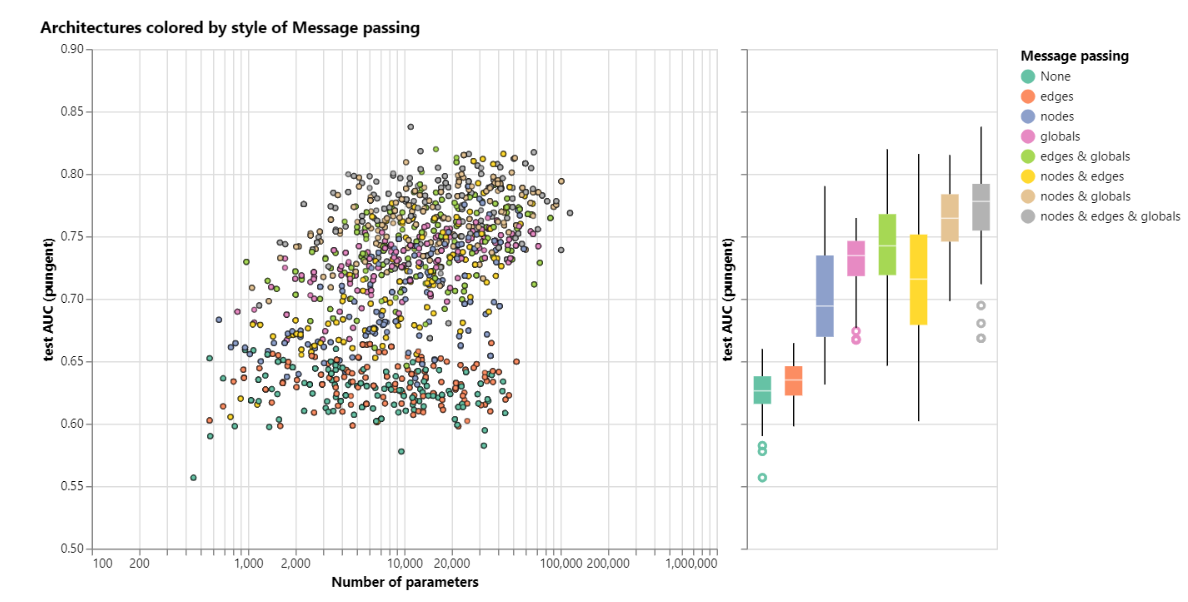
- 哪些属性之间传递信息的影响。信息传递在哪些属性之间传递,对模型的影响。右边盒图依次是
- 不传递任何信息 : 即前面提到的最简单的GNN,没有任何消息传递,其结果AUC也是最差的
- ….
- 节点和全局属性之间传递信息
- 节点、边、全局之间都传递信息,其AUC中值是最高的。
6 相关技术
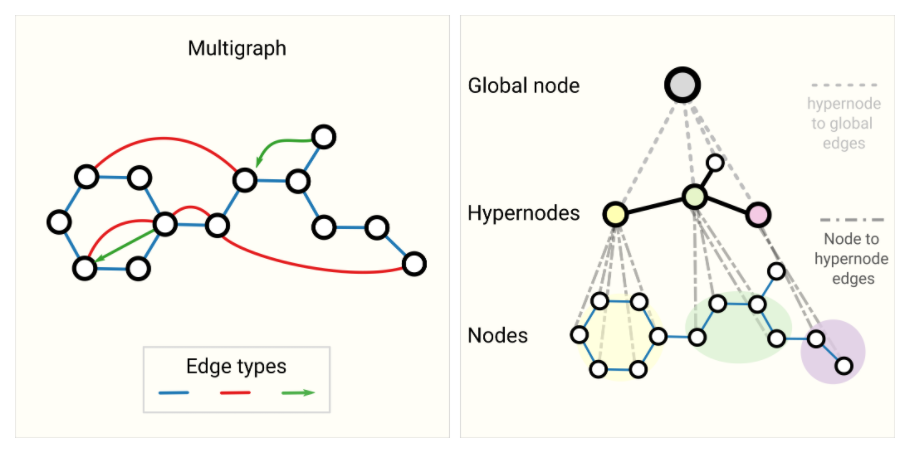
6.1 其他类型的图(多图、超图、超节点、层次图)
如下图左边图为多图,即节点之间存在多种边。右边为层次图,图中有些节点其实是一些子图,此时这些节点就是超节点hypernode。
6.2 如何对图做采样和batch
采样
假设图有很多层,由于前面多层网络之间做了足够充分的信息传递,那么多层之后的节点,即使只看起近邻节点,该节点可能会包含图的所有信息。而计算梯度时,需要保留整个forward的所有中间变量,这样会导致计算量不可承受。此时需要做图采样,即每次抽取图的一部分子图,在子图上做信息汇聚。
有以下采样方法
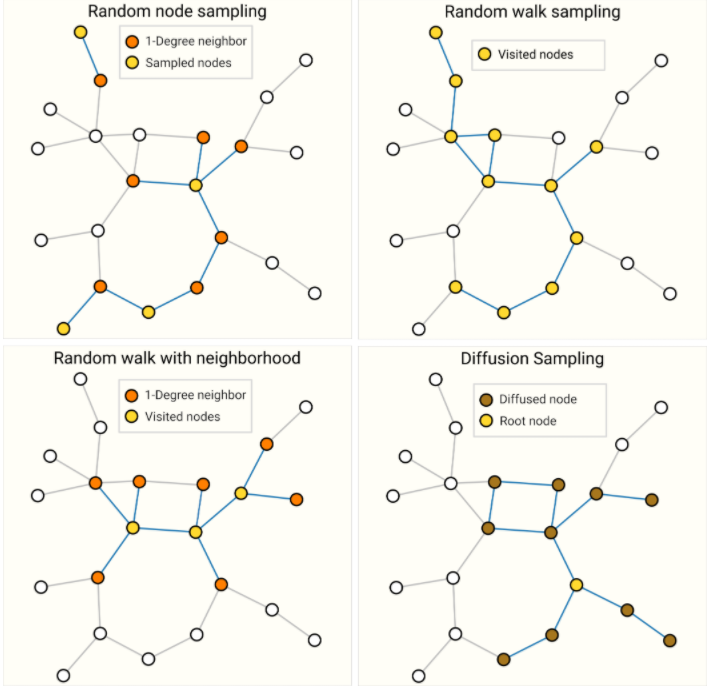
- 随机采样:抽取某些几点的1-近邻节点。示例图中左上图,随机采样了4个黄色节点,其1-近邻邻居节点为红色。计算时只在子图上做计算,通过控制每次采样点数量来避免计算量过大。
- 随机游走: 从某个节点开始,沿着随机的一条边走到下一个节点,规定随机游走步数,即可得到一张子图。
- 随机游走+随机采样: 先随机走规定步数,然后把随机游走过程中的节点的以及其邻居抽取出来,得到一张子图。
- Disfussion Sampling: 随机抽取一个节点,把它的1-近邻,2-近邻,3-近邻往前走K步,做一个宽度遍历,进而得到一张子图。
batch
假设不想对每个节点逐个更新,每一步计算量太小,不利于并行计算。如何像标准神经网络一样,每次对一小批量样本拼接,一次性计算一个大矩阵。但是有以下问题
- 每个节点邻居数量不同,如何合并成规整数据
7 GNN的假设原理
- CNN的前提假设是空间变换的不变性
- RNN的前提假设是时间的延续性
- GNN的前提假设是保持了图的对称性: 交换节点顺序,GNN对其作用不变。